
Using Multivariate Feature Flags In LaunchDarkly To Gradually Ramp-Up Batched Operations Like Database Migrations
Yesterday, in my review of Distributed Systems Observability by Cindy Sridharan, I mentioned that I've never gotten a lot of value out of pre-production load-testing. Instead, I use LaunchDarkly feature flags to incrementally roll-out a new feature while monitoring the underlying database and application performance. Essentially, I use production users to safely perform load testing in the most "production like" environment (aka Production). A few days ago, I was discussing this with fellow InVision'eer, Gabriel Zeck, when it occurred to us that we could use the very same approach to gradually ramp-up database migration tasks that operate on batched records. Meaning, we could use LaunchDarkly's multivariate (multi-value) feature flags to gradually increase the batch size of each subsequent database operation while closely monitoring the database performance.
When LaunchDarkly first launched, it only allowed for Boolean flags. Meaning, each feature flag was either True or False. With the introduction of multivariate feature flags, however, multiple datatypes became possible. And, with datatypes like Number and String, arbitrary values also became possible.
Now, what's really cool about multivariate feature flags is that the set of flag values can be augmented after the feature flag is created. This means that we can continue to add and synchronize multivariate feature flag values with our production application even after the consuming code has been deployed. Which, in turn, means that we can dynamically alter runtime behavior with great flexibility.
To explore this idea in the context of batched operations like database migrations, I went into LaunchDarkly and created a multivariate feature flag for "batch size":
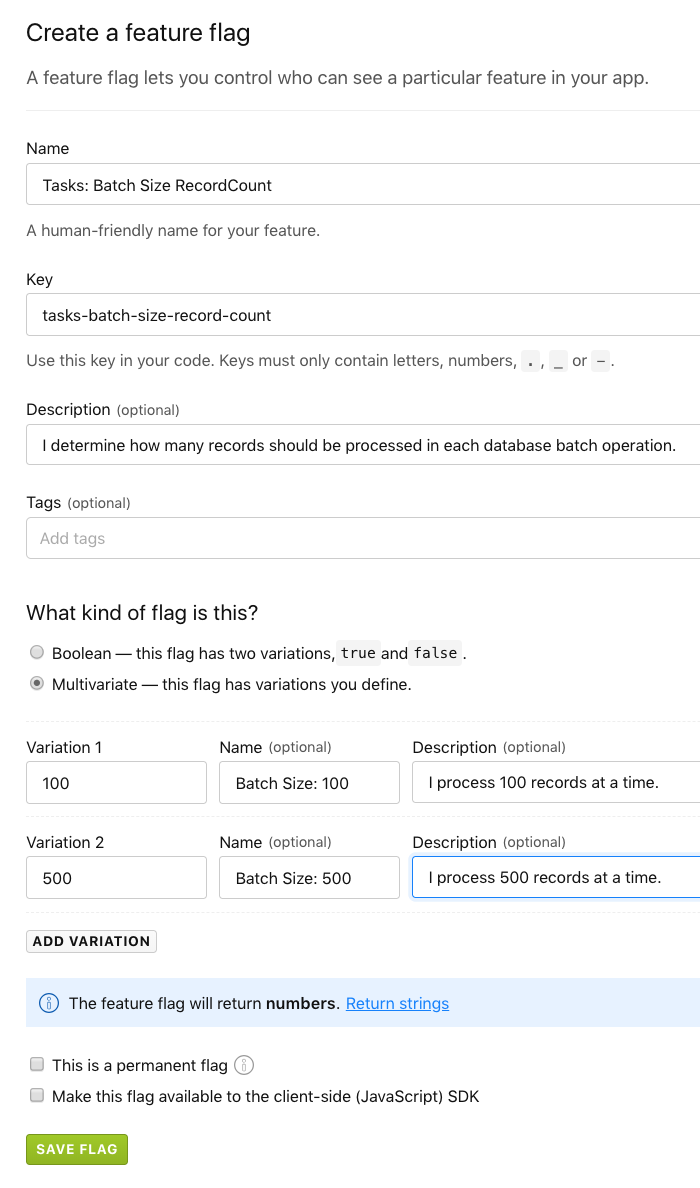
As you can see, this multivariate feature flag - tasks-batch-size-record-count - has two variations: 100 and 500. These values will then be used to drive the iteration size in a mock database migration in Node.js. In the following code, notice that I'm calling the this._getBatchSize() method for each chunk of records that I pull back from the "database":
| // Require the core node modules. | |
| var chalk = require( "chalk" ); | |
| var LaunchDarkly = require( "ldclient-node" ); | |
| // Require the application modules. | |
| var config = require( "./config" ); | |
| // ----------------------------------------------------------------------------------- // | |
| // ----------------------------------------------------------------------------------- // | |
| class TaskRunner { | |
| // I initialize the task runner with the given Launch Darkly client. | |
| constructor( launchDarklyClient ) { | |
| this._launchDarklyClient = launchDarklyClient; | |
| } | |
| // --- | |
| // PUBLIC METHODS. | |
| // --- | |
| // I execute the database task, processing chunks of records at a time. | |
| async run() { | |
| while ( true ) { | |
| // For each batch, we're going to check to see how many records we should be | |
| // processing. This allows us to gradually ramp-up the batch size while we | |
| // monitor the database to see how it is handling the demand. | |
| var batchSize = await this._getBatchSize(); | |
| var batch = await this._getNextBatch( batchSize ); | |
| // If there are no more records to process, break out of the loop. | |
| if ( ! batch.length ) { | |
| break; | |
| } | |
| console.log( chalk.cyan( "Processing", chalk.bold( batchSize, "records." ) ) ); | |
| await this._processBatch( batch ); | |
| } | |
| } | |
| // --- | |
| // PRIVATE METHODS. | |
| // --- | |
| // I get the size of the next batch to process in this task. | |
| async _getBatchSize() { | |
| // Wait until the LaunchDarkly client is ready before we try to read our feature | |
| // flag for the task runner batch size. If we don't do this, we're more likely to | |
| // get the fall-back value rather than the synchronized value. | |
| await this._launchDarklyClient.waitUntilReady(); | |
| // When getting the batch size feature flag, we're going to identify a new "user" | |
| // (key) for each task that we run in the application. This way, we can use the | |
| // same flag across all of our tasks while still allocating a unique "batch size" | |
| // variation for each individual task runner. | |
| var batchSize = await this._launchDarklyClient.variation( | |
| "tasks-batch-size-record-count", | |
| { | |
| key: "task-runner-node-demo" // The "user" for this task. | |
| }, | |
| 100 // Default / fall-back variation value. | |
| ); | |
| return( batchSize ); | |
| } | |
| // I get the next batch of records (this is just a mock). | |
| async _getNextBatch( batchSize ) { | |
| return( new Array( batchSize ).fill( 0 ) ); | |
| } | |
| // I process the given batch of records (this is just a mock). | |
| async _processBatch( batch ) { | |
| await new Promise( | |
| ( resolve, reject ) => { | |
| setTimeout( resolve, 1000 ); | |
| } | |
| ); | |
| } | |
| } | |
| // ----------------------------------------------------------------------------------- // | |
| // ----------------------------------------------------------------------------------- // | |
| // NOTE: Internally, the LaunchDarkly client will set up an INTERVAL, which will hold | |
| // the node.js process open until you .close() the client. In a long-running application, | |
| // this doesn't matter. But, in a "test" script, it's just something to be aware of. | |
| var launchDarklyClient = LaunchDarkly.init( config.launchDarkly.apiKey ); | |
| new TaskRunner( launchDarklyClient ).run(); |
As you can see, for each pass of the while(true) loop, I'm checking the LaunchDarkly client for the "tasks-batch-size-record-count" feature flag, which I'm then using to drive the number of records that I read from and then write to the database (all mocked-out). When I do this, I am uniquely identifying this particular task runner as, "task-runner-node-demo". This unique key allows me to use the same feature flag across different task runners while still allocating a different batch-size to each task identifier.
Once I have this identifier in place, I can go into the LaunchDarkly dashboard and target it in my feature flag rules:
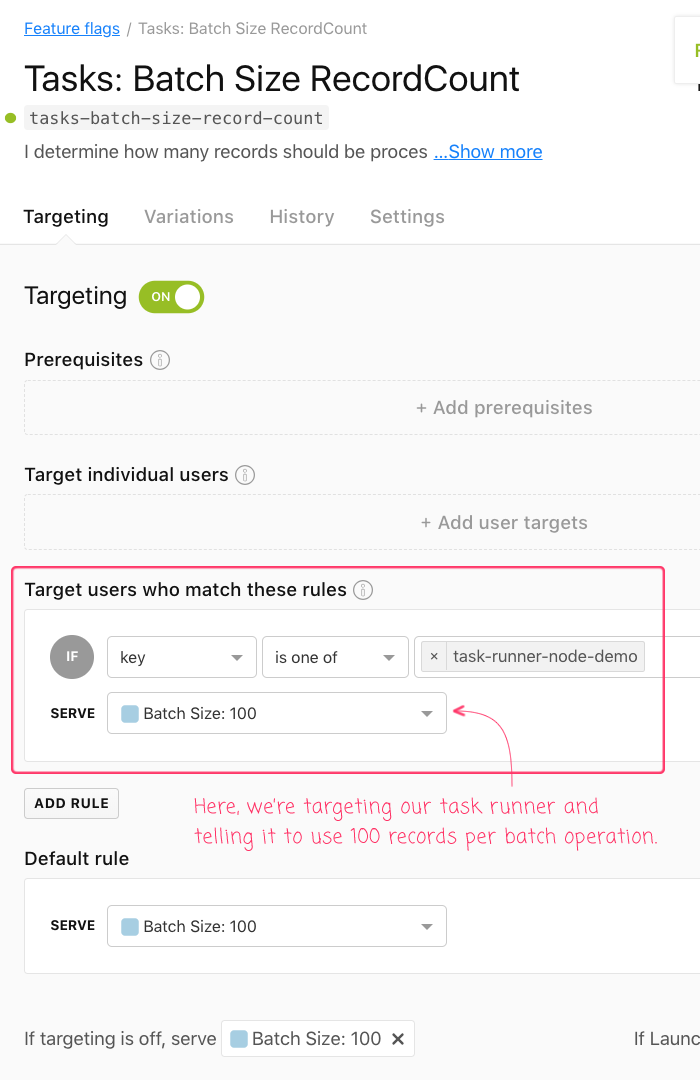
As this point, if we initiate the task runner in Node.js and then change the value that we're serving in LaunchDarkly, we can see the batch size of our database migration change in realtime:
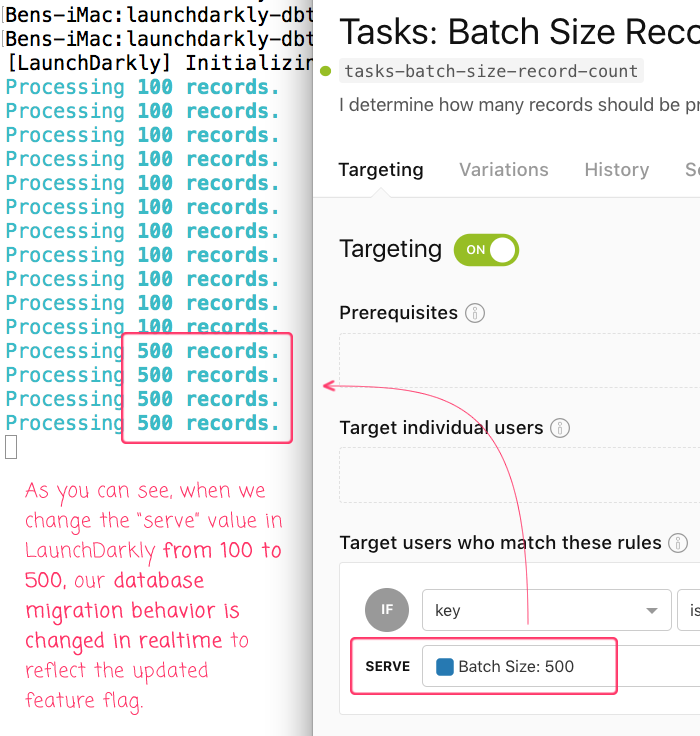
As you can see, the task runner started out by using batches of 100 records. Then, when we changed the LaunchDarkly feature flag to serve 500, our task running immediately responded by grabbing 500 records in each subsequent batch operation. With this approach we can gradually ramp-up our batch operations while ensuring that the database does not get overloaded (or start having a negative impact on our other users' experience).
To me, databases are kind of magical in so much as they tend to be able to handle way more load than I think they can. As such, it would not be surprising if my initial set of multivariate flag values ended up underutilizing the database throughput. Luckily, we can dynamically change the set of multivariate values at any time. All we have to do is go into the LaunchDarkly dashboard and configure our feature flag's variations:
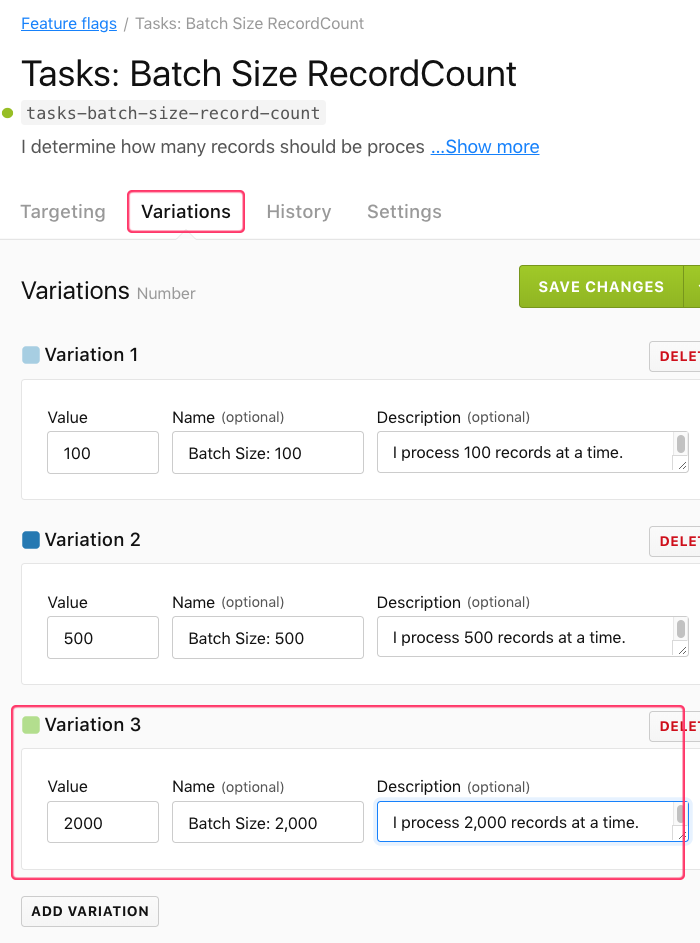
As you can see, I can go in an add new variations to a multivariate feature flag at any time. And, in this case, if I add "2000" as a possible variation and then start serving that value to my task runner, we can see that our migration - already in progress - will immediately pick up the change and start using the new batch size:

As you can see, even though the set of multivariate values was altered some time after our task runner had been initiated, the LaunchDarkly client picked up on the changes and immediately started applying them to subsequent batch operations.
This is so powerful! It allows us to use LaunchDarkly feature flags to dynamically change the runtime behavior of our batch operations in ways that we couldn't anticipate when we were writing the code in the first place. I already use LaunchDarkly feature flags to safely rollout new features. But now, I can use LaunchDarkly feature flags to gradually increase the processing demand of batch operations (like database migrations). This will allow me to squeeze as much performance as I can out of the database with the ability to pull-back on the demand the moment I see the database starting to struggle.
Want to use code from this post? Check out the license.
Reader Comments
Hi There,
Are you aware of using the percentage rollout in above scenario.
It didn't work for me using percentage rollout. Any idea on same.
@Vishal,
Oh, very interesting question. I have not tried to do a percentage-base rollout with anything other than a Boolean feature flag. I wonder if they can't do a percentage-based rollout with multi-variate feature flags because it might not be obvious what the True/False equivalent variations are?
That said, I just poked around in the LaunchDarkly docs and I see this warning:
... so, based on that warning, it reads as though you should be able to set a percentage rollout even for variations.
I'm not sure why it wasn't working for you. If I can carve out some time, I'll see if I can replicate. But, percentage-based rollouts are never something that I've actually tested explicitly -- I just assumed they work :D