
Each Feature Flag Should Be Owned By A Single Deployment Boundary
For the past two years, InVision has been using LaunchDarkly to manage its feature flags (aka feature toggles). At first, we were just trying to understand how to use feature flags; but now, we use feature flags aggressively in our day-to-day development requirements. In the same two years, InVision has also been migrating from a large, monolithic application to a distributed, service-oriented architecture. And, as various modules have been broken out into their own repositories and deployment life-cycles, it wasn't always clear as to how feature flags should be used to coordinate changes across the application landscape. Looking back now, and reflecting on the overhead and cost of feature flags, I think it merits drawing a hard line around a given feature flag and a single service deployment. Meaning, each feature flag should be owned and operated within a single deployment boundary.
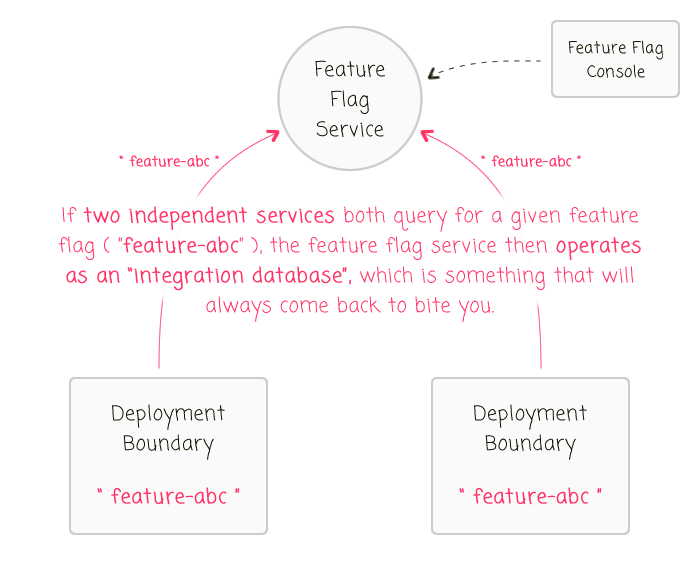
Now, I don't mean that a feature flag can't be referenced across multiple deployment boundaries - I only mean that the "source of truth" for that feature flag should be owned and operated by a single deployment boundary. In essence, we don't want feature flags to become an "integration database":
| |
|
|
||
| |
 |
|
||
| |
|
|
In this case, we have two independently-deployed services both reaching out directly to the feature flag database for the same feature toggle. When this happens - as with any integration database - it becomes unclear as to what will actually precipitate when you change the value of a given feature flag.
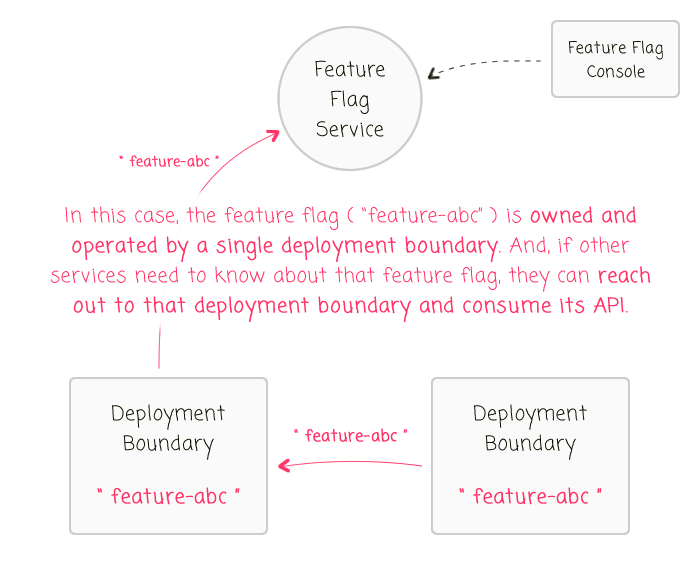
If you do have two independently-deployed services that need to reference a given feature flag, one service needs to "own and operate" that feature flag and expose it through an API end-point:
| |
|
|
||
| |
 |
|
||
| |
|
|
In this case, one service deployment boundary acts as the "source of truth" for a given feature. Then, if other services also need to know about that feature, they can do so by querying the owning-service's API. This flow of control makes the scope of a feature flag much more obvious. And, just as critical, this flow of control hides the implementation details of the feature flag value. This allows the logic behind the feature flag to change without creating an inconsistent understanding of the feature across coupled systems.
For example, imagine that the owning service starts out by exposing the feature flag in an API response payload that looks like this:
{ featureAbc: featureFlags.isEnabled( "featureAbc" ) }
At first, the value of the feature flag is based on some roll-out strategy. But later on, when this feature flag is eventually pushed out to 100% of the audience, the owning service can change its internal implementation to be hard-coded:
{ featureAbc: true }
This particular feature flag can then be safely deleted from the feature flag service without creating any cascading / breaking changes to the dependent services. This makes it much easier to clean up feature flags without having to wait on other services to remove their relevant references. And, by leaving in the hard-coded reference, it keeps your API backwards compatible.
Now, with all that said, I honestly don't think services should actually share the same feature flag concepts. The most obvious exception to that is the separation of UI (User Interface) and server (ex, BFF: Back-end For Front-end). In the case where a UI is built and deployed separately from its back-end, it's entirely reasonable for the UI to ask the back-end service for feature flag values. Of course, this still uses the "proper" workflow because it treats the back-end as the "source of truth" for the feature flags - the client never attempts to reach out directly to the feature flag service.
If you find that you often have multiple, independently-deployed services all needing to know about the same feature flag, I would view that as a "code smell." My guess is that you're trying to coordinate things with pin-point precision that don't actually need to be coordinated.
For example, you might be tempted to use "enableSingleSignOn" across all repositories that present a login interface to the user. The hope being that you can instantly enable the Single Sign-On UI in every login page, everywhere, on all devices, at exactly the same time for all users. But, this requirement is a fallacy. Just as a feature can often be rolled-out to a percentage of users, so can it also be rolled-out to a percentage of deployment boundaries (through the use of different feature flags, one per deployment boundary).
On day-one, integration database are awesome! They're the bee's knees. Giving multiple services the ability to query the same database cuts down on HTTP overhead, response times, architecture complexity, and increases the speed of development. But, it's never day-one that kills you. It'd day-one-hundred. And day-one-thousand. An integration database creates a architecture that's so coupled it becomes dangerous to make changes. And, after having used feature flags for a few years now, I've seen the feature flag database carry the cost of any other integration database. Which is why I think it is important that any given feature flag be "owned" by a single deployment boundary such that one service - and one service alone - can act as the source of truth for that feature flag.

Reader Comments