
Using UPDATE + ORDER BY + LIMIT To Drive Multi-Worker Migrations In Lucee CFML 5.3.6.61
Earlier this week, I took a look at using ORDER BY and LIMIT clauses within an UPDATE statement in MySQL 5.6.37 in order to limit the scope of the data-mutation. In that post, I said that such a technique can be used to drive a multi-worker / multi-threaded migration in which each worker "claims" and then "processes" a subset of records within a "task table". Since I find this technique to be relatively simple but also wickedly useful, I thought it would be fun to put together a migration demo in Lucee CFML 5.3.6.61.
In this demo, we're going to be using a database table as a message queue of sorts. Typically, you don't want to use a database table as a message queue for interprocess communication - you'd want to use a more specialized technology like Amazon SQS or RabbitMQ or the like. However, in this context, the database table in question is being pre-allocated to represent a finite set of work. As such, a database table is perfectly acceptable and a very pragmatic choice at that.
To set the stage, this "migration" requires us to download and reprocess a set of image files. I don't actually care about the reprocessing itself - that's incidental. As such, I'm just going to download the image and consider that to be a successful task execution. The real meat of the post is how we manage the downloading and the incremental traversal of the shared database table across multiple threads / workers.
To do this, I'm going to create and populate a MySQL table named, migration_task. Each record in this table represents a single, cohesive unit-of-work to be executed (in this case, downloading a given imageUrl). Each task / record can exist in one of three states:
open- Ready to be claimed.processing- Claimed by one of the workers and is in mid-process.complete- Successfully processed.
In reality, you might want additional statuses, such as "failure", based on your particular migration needs. However, for this demo, these three are sufficient to illustrate my technique.
This table is going to be created and populated ahead of time. As such, it represents a finite set of work that needs to be consumed. And, the algorithm for consuming this table is thus:
A worker claims a set of records, changing the state from
opentoprocessing. This is where ourUPDATE+ORDER BY+LIMITSQL statement comes into play.Said worker iterates over the claimed records in-turn and processes them each individually.
Each record is marked as
completeif it was processed successfully; or, is "reset" (ie, put back into anopenstate) upon failure.
In the following MySQL table, the claimedBy value is the unique ID of the worker / thread that is processing a given record:
| CREATE TABLE `migration_task` ( | |
| `id` int(10) unsigned NOT NULL AUTO_INCREMENT, | |
| `status` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL, | |
| `iteration` tinyint(3) unsigned NOT NULL, | |
| `claimedBy` char(35) DEFAULT NULL, | |
| `claimedAt` datetime DEFAULT NULL, | |
| `completedAt` datetime DEFAULT NULL, | |
| `imageUrl` varchar(500) NOT NULL, | |
| PRIMARY KEY (`id`), | |
| KEY `byClaim` (`claimedBy`,`status`), | |
| KEY `byStatus` (`status`,`completedAt`,`claimedAt`) USING BTREE | |
| ) ENGINE=InnoDB DEFAULT CHARSET=utf8; |
To populate this database table, I literally ran a for-loop from 1 to 50,000 and inserted a quasi-random remote imageUrl. Again, the goal of this post isn't to showcase image processing - the goal here is to look at the traversal and processing of this table.
The Golden Rule Of Migrations: Something Will Go Wrong!
Whenever you're performing a migration in a production setting, you must assume that something will go wrong. Trust me, it almost always does! For example, once you deploy your migration code, you may find:
There's an edge-case in your processing that you didn't account for in the code.
There's "dirty data" or state in your application that is causing the migration to fail in an unexpected way.
There's a misconfigured environment (
ENV) variable.The load on the database or platform is greater than anticipated and the migration itself is hurting the performance of the application at large.
The migration is running much slower than anticipated and some aspect of it will have to be tweaks in order to make it a "tractable" problem.
An upstream service crashes and is causing the migration to fail.
An upstream service starts responding with rate-limiting errors.
As much as we try to plan and account-for and anticipate in our code, no plan survives first contact with production. Instead of fighting this, we have to embrace the reality and build constructs into the migration that allow us to stop it and start it using an external process.
For this demo, I'm going to represent this safety-valve with an Application variable called, application.isProcessing. Each worker will have to check this flag during processing; and, if this value moves to false, the worker will have to short-circuit and halt processing. In this way, we can monitor the state of the migration; and, if something seems fishy, we can pull the safety-chord and stop the migration while we investigate any issues.
Multi-Server Migration: Since this demo is running on a single ColdFusion server, I can use the shared
applicationscope. However, if you are running the migration across multiple servers, this flag would have to move to a remote system like Redis or a LaunchDarkly feature flag.
Simulating A Multi-Worker Migration Environment
Right now, this demo / migration is being run on a single Lucee CFML server. As such, in order to simulate a multi-worker / multi-server environment, I've created a dashboard that loads several workers using IFRAME elements. Each IFRAME is intended to represent an isolated worker on a different server:
| <!doctype html> | |
| <html lang="en"> | |
| <head> | |
| <meta charset="utf-8" /> | |
| <title> | |
| UPDATE + ORDER BY + LIMIT Migration Demo In Lucee CFML 5.3.6.61 | |
| </title> | |
| <link rel="stylesheet" type="text/css" href="./demo.css" /> | |
| </head> | |
| <body class="dashboard"> | |
| <iframe src="./controls.cfm" scrolling="no" class="controls"></iframe> | |
| <!--- | |
| For this demo, each worker is going to be run in its own IFRAME on the same | |
| server. However, this could easily be workers spit across a multitude of | |
| servers that use some sort of shared global state (like a Redis key) to know if | |
| they should continue processing. | |
| ---> | |
| <div class="workers"> | |
| <iframe src="./worker.cfm?id=1" class="worker"></iframe> | |
| <iframe src="./worker.cfm?id=2" class="worker"></iframe> | |
| <iframe src="./worker.cfm?id=3" class="worker"></iframe> | |
| <!--- | |
| NOTE: Trying to use 10-workers was overwhelming my dev-machine for some | |
| reasons. The CPU was fine; but, it wasn't letting me send additional | |
| requests to the server to stop processing - maybe it was the browser | |
| blocking X-number of pending requests to the same domain??? | |
| ---> | |
| <!--- | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| <iframe src="./worker.cfm" class="worker"></iframe> | |
| ---> | |
| </div> | |
| </body> | |
| </html> |
At first, I tried to run this with 10-workers; but, I was finding that with so many open HTTP requests to the same server, I didn't seem to be able to flip the isProcessing flag with an additional HTTP request. I believe this was a browser limitation, not a ColdFusion limitation.
In this HTML page above, the first IFRAME - "controls.cfm" - is our "external process" that can start and stop the migration:
| <cfparam name="application.isProcessing" type="boolean" default="false" /> | |
| <cfparam name="url.isProcessing" type="boolean" default="false" /> | |
| <!--- Log the state-change for the migration. ---> | |
| <cfif ( application.isProcessing neq url.isProcessing )> | |
| <cfif url.isProcessing> | |
| <cfset systemOutput( "Migration: --- STARTING WORKERS ---", true, true ) /> | |
| <cfelse> | |
| <cfset systemOutput( "Migration: --- STOPPING WORKERS ---", true, true ) /> | |
| </cfif> | |
| </cfif> | |
| <!--- Drive the application state from the current URL. ---> | |
| <cfset application.isProcessing = url.isProcessing /> | |
| <!doctype html> | |
| <html lang="en"> | |
| <head> | |
| <meta charset="utf-8" /> | |
| <link rel="stylesheet" type="text/css" href="./demo.css" /> | |
| </head> | |
| <body> | |
| <h1> | |
| UPDATE + ORDER BY + LIMIT Migration Demo In Lucee CFML 5.3.6.61 | |
| </h1> | |
| <p> | |
| <strong>Processing:</strong> | |
| <cfoutput>#yesNoFormat( application.isProcessing )#</cfoutput> | |
| <cfif application.isProcessing> | |
| — | |
| <a href="./controls.cfm?isProcessing=false">Stop Processing</a> | |
| <cfelse> | |
| — | |
| <a href="./controls.cfm?isProcessing=true">Start Processing</a> | |
| </cfif> | |
| </p> | |
| <!--- If we're starting the migration, refresh all the Worker IFRAMES. ---> | |
| <cfif url.isProcessing> | |
| <script type="text/javascript"> | |
| for ( var iframe of window.top.document.querySelectorAll( "iframe.worker" ) ) { | |
| iframe.contentWindow.location.reload(); | |
| } | |
| </script> | |
| </cfif> | |
| </body> | |
| </html> |
As you can see, this page either sets the application.isProcessing flag to true or false. In the case of true, this page also reaches into the parent document (using JavaScript) and calls .reload() on each of the workers so as to kick-start their processing.
Traversing The Migration Task Table With Parallel Workers
Now that we have a high-level sense of how the migration is being managed by an external process; and how the workers may be spread across multiple servers; let's look at how the worker itself is implemented - this is where the really fun stuff is.
For the sake of simplicity, I'm putting all the worker logic right into a top-level CFML page request. In reality, you may want to run this inside a CFThread; and, you may even want to add application-level locking around the processing in order to make sure that each server only has a single active worker running at any given moment. But, again, I'm trying to keep it simple.
In the following code, I've tried to separate the algorithmic steps from the implementation details. Each step has been encapsulated in a method call:
resetOverdueTasks()- I reset any overdue tasks. These are tasks that are in a "processing" state for too long and need to be returned to the pool of open tasks.claimNextBlockOfTasks()- I claim the next block of "open" tasks for the given worker. This is where theUPDATE+ORDER BY+LIMITSQL statement works its magic.processTask()- I perform the migration work associated with a given task. In this case, it's just going to useCFHTTPto download the image - not really the point of the article, just an incidental detail.completeTask()- I mark the given task record as completed.resetTask()- I mark the given task record as "failed", returning it to the set of open tasks.logError()- I log migration errors. Remember, something will always go wrong! Be prepared to catch errors and then monitor for them in your log aggregation.
And, it will do all of this while the application.isProcessing flag is set to true; and, will bail-out when it sees that the application.isProcessing flag is flipped to false:
| <cfparam name="application.isProcessing" type="boolean" default="false" /> | |
| <!doctype html> | |
| <html lang="en"> | |
| <head> | |
| <meta charset="utf-8" /> | |
| <link rel="stylesheet" type="text/css" href="./demo.css" /> | |
| </head> | |
| <body> | |
| <h3> | |
| Worker | |
| </h3> | |
| <cfscript> | |
| // When running a migration, I like to have some sort of "flag" that determines | |
| // whether or not the processing should continue. This is especially helpful as | |
| // you pretty much ALWAYS RUN INTO ISSUES where you want to stop the code after | |
| // you notice something "funky" after you code hits production :D | |
| // -- | |
| // NOTE: Since all the works in this demo are on the same server, we can use the | |
| // application scope to drive processing. However, if the workers in production | |
| // were running across many servers, this flag could easily be read from a shared | |
| // memory store like Redis. | |
| while ( application.isProcessing ) { | |
| // Before this worker checks for another set of records, let's reset any | |
| // overdue tasks - returning them back to the pool of unprocessed tasks. | |
| // -- | |
| // NOTE: This could be done as an EXTERNAL check (ie, not part of the | |
| // runner). I'm just lumping it all together here to make the demo a bit | |
| // more cohesive (and to see how it affects database read-times). | |
| resetOverdueTasks(); | |
| // For each iteration, let's give the worker a new ID. This will make the | |
| // worker ID more "selective" in the underlying query. | |
| workerID = "worker-#createUniqueID()#"; | |
| tasks = claimNextBlockOfTasks( workerID, 10 ); | |
| // If no tasks could be claimed, let's stop processing. | |
| if ( ! tasks.recordCount ) { | |
| break; | |
| } | |
| for ( task in tasks ) { | |
| try { | |
| processTask( task ); | |
| completeTask( task ); | |
| } catch ( any error ) { | |
| logError( task, error ); | |
| resetTask( task ); | |
| } | |
| // Just some output to make the demo more colorful when stop the | |
| // processing (U+25CF is the "BLACK CIRCLE" Unicode character). | |
| echo( "&###inputBaseN( '25CF', 16 )#; " ); | |
| } | |
| } // END: while. | |
| </cfscript> | |
| </body> | |
| </html> | |
| <!--- ------------------------------------------------------------------------------ ---> | |
| <!--- ------------------------------------------------------------------------------ ---> | |
| <cfscript> | |
| /** | |
| * I reset tasks that have been processing for over 2-minutes without completion. We | |
| * are going to assume that something went wrong and the error was not properly | |
| * handled; or the thread got into some sort of bad state. For whatever reason, the | |
| * claimed tasks should be returned to the pool of open tasks. | |
| */ | |
| public void function resetOverdueTasks() { | |
| ``` | |
| <cfquery name="local.resetTasks" result="local.results"> | |
| /* DEBUG: worker.resetOverdueTasks(). */ | |
| UPDATE | |
| migration_task | |
| SET | |
| status = 'open', | |
| iteration = ( iteration + 1 ), | |
| claimedBy = NULL, | |
| claimedAt = NULL | |
| WHERE | |
| status = 'processing' | |
| AND | |
| completedAt IS NULL | |
| AND | |
| claimedAt <= DATE_ADD( UTC_TIMESTAMP(), INTERVAL -2 MINUTE ) | |
| ; | |
| </cfquery> | |
| ``` | |
| // Let's log how long it takes to reset any "stalled" tasks. | |
| systemOutput( "Migration: Reset time: #results.executionTime#", true, true ); | |
| } | |
| /** | |
| * I claim the next block of open tasks for the given worker. | |
| * | |
| * @workerID I am the working claiming open tasks. | |
| * @limit I am the maximum number of open tasks to claim. | |
| */ | |
| public query function claimNextBlockOfTasks( | |
| required string workerID, | |
| required numeric limit | |
| ) { | |
| ``` | |
| <cfquery name="local.claimOpenRows" result="local.results"> | |
| /* DEBUG: worker.claimNextBlockOfTasks(A). */ | |
| UPDATE | |
| migration_task | |
| SET | |
| status = 'processing', | |
| claimedBy = <cfqueryparam value="#workerID#" sqltype="varchar" />, | |
| claimedAt = UTC_TIMESTAMP() | |
| WHERE | |
| status = 'open' | |
| ORDER BY | |
| id ASC | |
| LIMIT | |
| <cfqueryparam value="#limit#" sqltype="integer" /> | |
| ; | |
| </cfquery> | |
| ``` | |
| // Normally, I would combine the above and below queries into a single query. | |
| // However, in order to get some insights into how long it takes to claim | |
| // records, I am breaking them apart so as to isolate the act of UPDATEing the | |
| // claimed records. | |
| systemOutput( "Migration: Claim time: #results.executionTime#", true, true ); | |
| ``` | |
| <cfquery name="local.tasks"> | |
| /* DEBUG: worker.claimNextBlockOfTasks(B). */ | |
| SELECT | |
| id, | |
| imageUrl | |
| FROM | |
| migration_task | |
| WHERE | |
| claimedBy = <cfqueryparam value="#workerID#" sqltype="varchar" /> | |
| AND | |
| status = 'processing' | |
| ; | |
| </cfquery> | |
| ``` | |
| return( tasks ); | |
| } | |
| /** | |
| * I process the given task, migrating the associated data (since this is just a demo, | |
| * this is pretty generic). | |
| * | |
| * @task I am the task being processed. | |
| */ | |
| public void function processTask( required struct task ) { | |
| // For the sake of the demo, we're just going to download the given image - | |
| // something to create a little processing overhead. In a true migration, we'd | |
| // do something more with the generated image; but, for now, I hope this is | |
| // sufficient to illustrate the point. | |
| http | |
| result = "local.results" | |
| method = "GET" | |
| url = task.imageUrl | |
| path = expandPath( "./downloads" ) | |
| file = "image-#( task.id % 100 )#.jpg" | |
| getAsBinary = "yes" | |
| throwOnError = true | |
| ; | |
| } | |
| /** | |
| * I mark the given task as completed. | |
| * | |
| * @task I am the task being completed. | |
| */ | |
| public void function completeTask( required struct task ) { | |
| ``` | |
| <cfquery name="local.complete"> | |
| UPDATE | |
| migration_task | |
| SET | |
| status = 'complete', | |
| completedAt = UTC_TIMESTAMP() | |
| WHERE | |
| id = <cfqueryparam value="#task.id#" sqltype="integer" /> | |
| AND | |
| status = 'processing' | |
| ; | |
| </cfquery> | |
| ``` | |
| } | |
| /** | |
| * I reset the given task after processing of it has failed. | |
| * | |
| * @task I am the task being reset. | |
| */ | |
| public void function resetTask( required struct task ) { | |
| ``` | |
| <cfquery name="local.complete"> | |
| UPDATE | |
| migration_task | |
| SET | |
| status = 'open', | |
| iteration = ( iteration + 1 ), | |
| claimedBy = NULL, | |
| claimedAt = NULL | |
| WHERE | |
| id = <cfqueryparam value="#task.id#" sqltype="integer" /> | |
| ; | |
| </cfquery> | |
| ``` | |
| } | |
| /** | |
| * I log the error that was thrown processing the given task. | |
| * | |
| * @task I am the task that was being processed. | |
| * @error I am the error that was thrown during processing. | |
| */ | |
| public void function logError( | |
| required struct task, | |
| required struct error | |
| ) { | |
| systemOutput( | |
| serializeJson({ | |
| error: error, | |
| task: task | |
| }), | |
| true, // Add new-line. | |
| true // Write to error-output. | |
| ); | |
| } | |
| </cfscript> |
As you can see in my resetOverdueTasks() and claimNextBlockOfTasks() methods, I'm using the built-in function, systemOutput(), to log the times of my database calls to the terminal-output. This is so we can see how the migration performs as multiple workers all try to read-from and write-to the same MySQL database table at the same time.
Granted, three workers and 50,000 records isn't necessarily representative of "production scale". But, I think it demonstrates the proof-of-concept.
That said, let's try to spin this migration up and watch the output:
NOTE: I changed the "chunk" size to
1for the following GIF so as to make it more "interactive" (ie, so more chunks were processed during the recording).
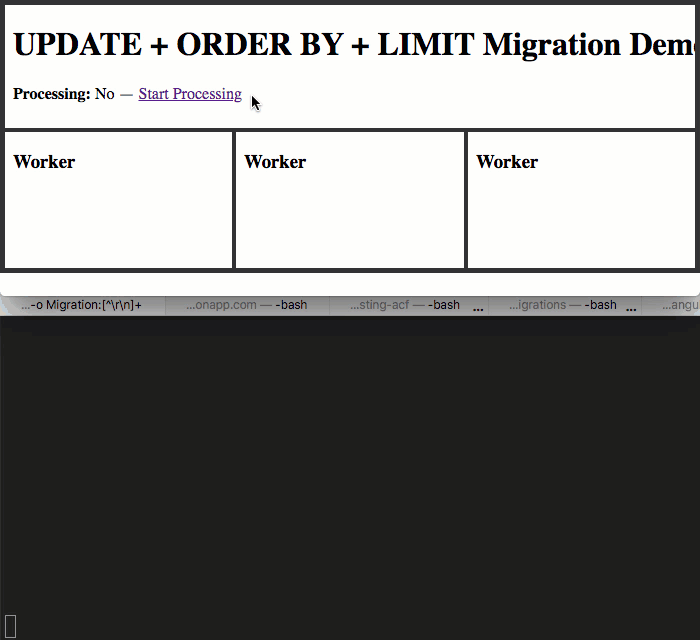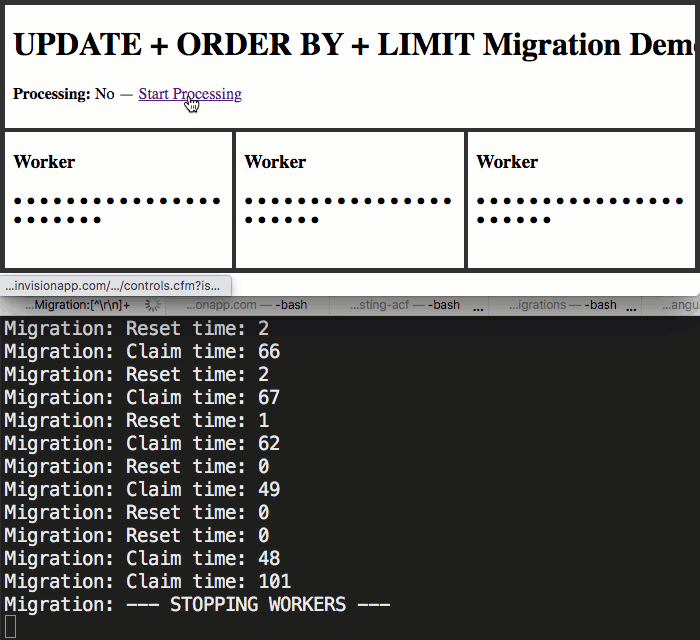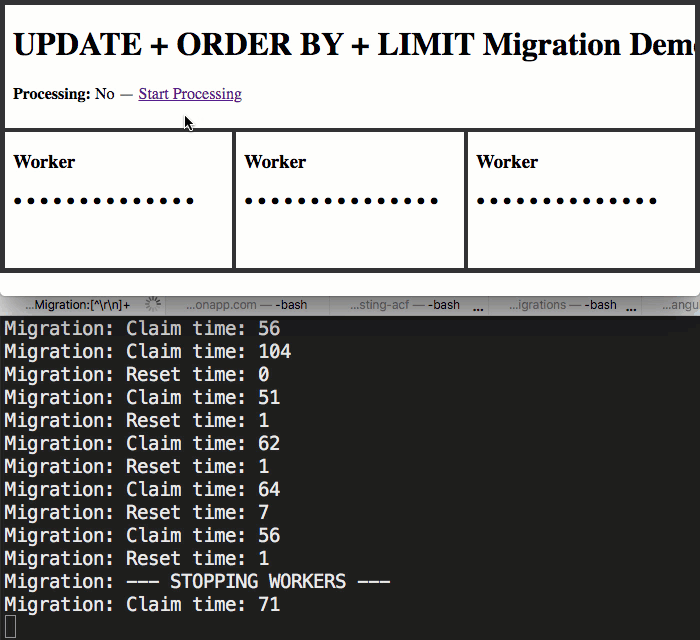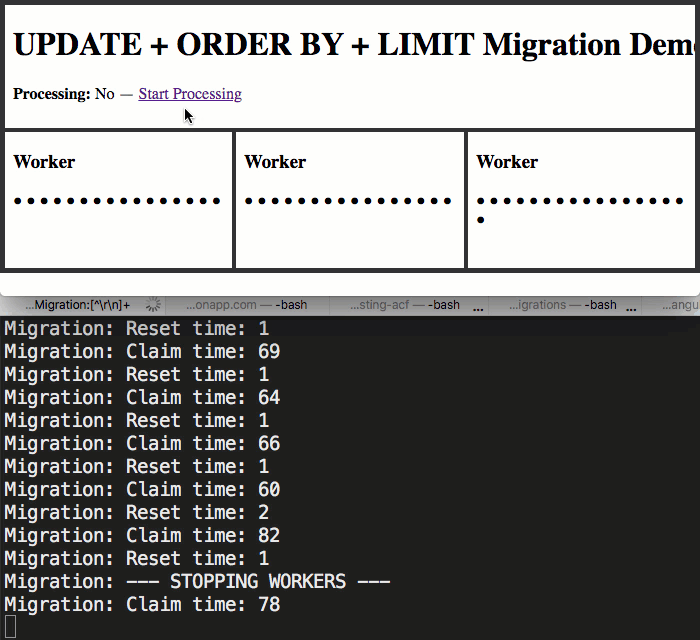
As you can see, by using the top IFRAME to manage the application.isProcessed flag, I was able to start and stop the migration within each worker. And, as we can see from the terminal output, even with three workers simultaneously hitting the same database table in order to "claim" and then process records, the performance is quite nice.
To be honest, I don't know if this technique would scale to billions of records (or more). But, I can tell you that it scales to the size of ColdFusion applications that I've built with MySQL in the past. And, the code isn't terribly complicated. The ability to use ORDER BY and LIMIT within an UPDATE statement in MySQL 5.6.37 makes it quite painless to have multiple workers traverse the same database table without stepping on each other's toes.
And, we didn't even need to pull-in any additional technologies like RabbitMQ or Amazon SQS. We just made pragmatic decisions that side-stepped pontification and academia and just got it done!
Want to use code from this post? Check out the license.
Reader Comments
Love your work.
@Geoff,
Thank you, kind sir! The older I get (and hopefully the more experienced I get), the more I just hold "getting it done" in high-esteem. You can try to spend all day telling me why my choices aren't "optimal" for one reason or another. But, I will happily do something sub-optimal, especially if it's a one-off process, so that I can move onto more important problems. :D