
Exploring The Interplay Between HTML Entities And TextContent In JavaScript
As I was playing around with inserting text at the last known caret location yesterday, I stumbled upon a large gap in my mental model for how HTML works. For years, I've been using HTML entities to generate web-safe HTML markup. However, I only just realized that if you read the textContent of an element that contains HTML entities, you don't get the HTML markup of said element, you get the interpreted text content. What this means, as an example, is that if you render an emoji using hex-encoded HTML entities, reading the textContent out of that node gives you the actual emoji glyph! To see this in action, I put together a small JavaScript demo.
Run this demo in my JavaScript Demos project on GitHub.
View this code in my JavaScript Demos project on GitHub.
To demonstrate, all we're going to do is render a paragraph that is composed entirely of HTML entities. Then, we're going to grab the textContent of that element and echo the value into both an input element and the browser's console:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>
Exploring The Interplay Between HTML Entities And TextContent In JavaScript
</title>
<link rel="stylesheet" type="text/css" href="./demo.css" />
</head>
<body>
<h1>
Exploring The Interplay Between HTML Entities And TextContent In JavaScript
</h1>
<p id="encoded">
<!-- Common HTML entities. -->
< > " →
<!-- Slightly smiling face emoji. -->
🙂
<!-- Frowning face. -->
☹️
</p>
<input id="input" type="text" size="40" />
<script type="text/javascript" src="../../vendor/jquery/3.6.0/jquery-3.6.0.min.js"></script>
<script type="text/javascript">
var encoded = $( "#encoded" );
var input = $( "#input" );
// Our encoded element contains text that we created using HTML entities; that
// is, web-safe encodings that represent other values. When we then extract that
// generated content, we get the RENDERED VALUE, not the ENCODED VALUE!
var encodedValue = encoded
.text()
.replace( /\s+/g, " " ); // Cleaning up the white-space.
;
// Echo the textContent in the Input and the Console.
input.val( encodedValue );
console.log( ( "%c" + encodedValue ), "font-family: monospace ;" );
// And, just as a test, let's make sure the jQuery .text() method is actually
// matching the raw .textProperty content.
console.log( encoded.text() === encoded.prop( "textContent" ) );
</script>
</body>
</html>
As you can see, our test paragraph contains some common HTML entities and some encoded emoji codepoint sequences. But, when we grab those values using textContent and echo them to other text-base outputs, we get the following output:
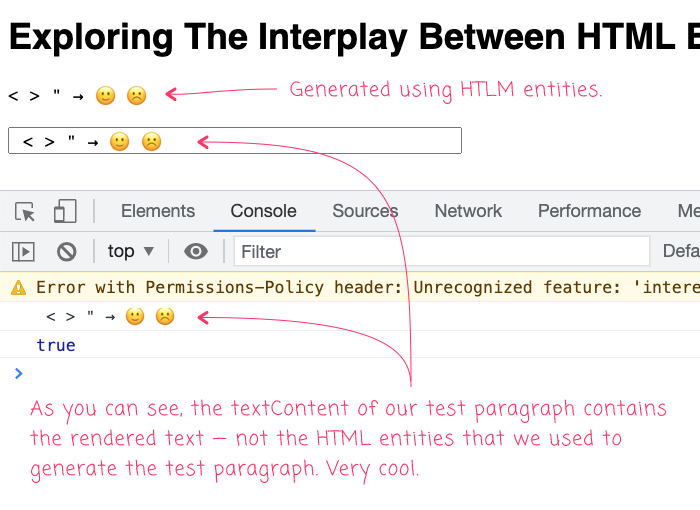
As you can see, the textContent property contains the evaluated HTML which, in this case, contains actual emoji glyphs, not the Unicode codepoints that we used to define the HTML content.
I can't believe I didn't know that the browser DOM (Document Object Model) worked this way. But, learning this is better late than never. I can definitely see this being helpful (unless you are one of those die-hards that believes "state" should never be stored on the DOM).
Want to use code from this post? Check out the license.
Reader Comments
Ben. This is interesting stuff.
I must admit, I never really thought about this and now that I am a full time Angular Dev, everything is abstracted away from the DOM! In fact, I have almost forgotten what Vanilla JS, looks like 😮
I kind of miss my days of being highly creative with CF FW1 & Vanilla JS + JQuery 😞
Sometimes, Angular feels too opinionated, especially when using NgRX!
I am loving your new comment emojis 🤣
@Charles,
Angular definitely provides a lot of utility that mean you don't have to manipulate the DOM all that much. But, also remember that Directives are just encapsulation around DOM elements / bindings. So, there's always room to get low-level DOM action happening inside of Directives.
That said, I'm using this totally outside of Angular 😂 sooo, your mileage may vary.