
Monkey-Patching The Mango .find() Plugin To Use .allDocs() In PouchDB 6.2.0
Yesterday, I took a look at the new .find() plugin in PouchDB 6.2.0. This plugin provides a simplified query language that can search both the primary / default index as well as the secondary indices that you created using the .find() plugin. As I was experimenting with it, however, I discovered that the .find() method would not use the primary index when searching for a collection of _id values. Since I know the .allDocs() bulk-fetch method can do this, I wanted to see if I could monkey-patch the .find() plugin and dip down into the more performant .allDocs() method if the selector contained nothing more than a collection of _id values.
Run this demo in my JavaScript Demos project on GitHub.
In PouchDB, the .allDocs() method is a way to use the primary key index to fetch multiple documents. This can be done based on a range of keys or an explicit collection of keys. For example, if we wanted to retrieve the keys "a", "b", and "c", we could use the .allDocs() "keys" criteria:
| db.allDocs({ | |
| keys: [ "a", "b", "c" ], | |
| include_docs: true | |
| }) |
With the PouchDB's new .find() method, the same thing can be done using the $in operator:
| .find({ | |
| selector: { | |
| _id: $in: [ "a", "b", "c" ] | |
| } | |
| }); |
However, the difference, as we discovered yesterday, is that the .find() plugin doesn't actually use the primary key index for this. Instead, PouchDB ends up doing a full-collection scan in order to locate the documents with the given keys.
To fix this performance gap, I wanted to see if I could create a PouchDB plugin that would monkey-patch the existing .find() plugin. Essentially, my plugin would proxy the .find() plugin and inspect the selector criteria. And, if the selector contained nothing more than a collection of _ids, I would use the more performant .allDocs() method; or, if the selector criteria was more complicated, I would fallback to using the original .find() method.
Since PouchDB plugins exist on the prototype object, I just had to capture a reference to to the original .find() method and then inject my own version of .find() on the PouchDB.prototype object:
| <!doctype html> | |
| <html> | |
| <head> | |
| <meta charset="utf-8" /> | |
| <title> | |
| Monkey-Patching The Mango .find() Plugin To Use .allDocs() In PouchDB 6.2.0 | |
| </title> | |
| </head> | |
| <body> | |
| <h1> | |
| Monkey-Patching The Mango .find() Plugin To Use .allDocs() In PouchDB 6.2.0 | |
| </h1> | |
| <p> | |
| <em>Look at console — things being logged, yo!</em> | |
| </p> | |
| <script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb-6.2.0.min.js"></script> | |
| <!-- | |
| NOTE: When running this in the browser, the Find() plugin will AUTOMATICALLY | |
| inject itself into the PouchDB global object. We don't have to wire this up | |
| explicitly (except when running in node). | |
| --> | |
| <script type="text/javascript" src="../../vendor/pouchdb/6.2.0/pouchdb.find.js"></script> | |
| <script type="text/javascript"> | |
| // I monkey-patch the .find() plugin to use the .allDocs() bulk-fetch method for | |
| // selectors that are looking up documents based on a collection of _id values. | |
| PouchDB.plugin( | |
| function applyPlugin( PouchDB ) { | |
| var originalFind = PouchDB.prototype.find; | |
| // I am the monkey-patched .find() method which is capable of efficiently | |
| // looking-up a collection of _id values using an $in selector. | |
| PouchDB.prototype.find = function( options ) { | |
| // Use the .allDocs() method if we can ... | |
| if ( isSearchingForIds( options ) ) { | |
| return( findCollectionOfIds( this, options ) ); | |
| // Or, revert to using the original .find(). | |
| } else { | |
| return( originalFind.call( this, options ) ); | |
| } | |
| }; | |
| // I find the documents using .allDocs() and return a Promise<result> | |
| // that conforms to the .find() results object. | |
| function findCollectionOfIds( db, options ) { | |
| console.warn( "USING MONKEY-PATCHED .find() METHOD" ); | |
| console.warn( "Using primary key index:", options.selector._id.$in ); | |
| console.warn( "Selector:", options.selector ); | |
| var promise = db | |
| .allDocs({ | |
| keys: options.selector._id.$in, | |
| include_docs: true | |
| }) | |
| .then( | |
| function( results ) { | |
| var docs = results.rows | |
| .map( | |
| function operator( row ) { | |
| return( row.doc ); | |
| } | |
| ) | |
| // Since the .allDocs() method will return undefined | |
| // objects for keys that it couldn't find, we have to | |
| // filter our collection down to only valid docs | |
| // since the .find() method will only return valid | |
| // documents. | |
| .filter( | |
| function operator( doc ) { | |
| return( !! doc ); | |
| } | |
| ) | |
| ; | |
| return({ | |
| docs: docs | |
| }); | |
| } | |
| ) | |
| ; | |
| return( promise ); | |
| } | |
| // I determine if the given .find() options represents an _id-based query | |
| // that can be converted into an .allDocs() query. | |
| function isSearchingForIds( options ) { | |
| // Checking to see if the selector has the given shape: | |
| // -- | |
| // selector: { _id: { $in: [ ... ] } } | |
| // -- | |
| return( | |
| // Make sure the _id selector is using $in. | |
| ( options instanceof Object ) && | |
| ( options.selector instanceof Object ) && | |
| ( options.selector._id instanceof Object ) && | |
| ( options.selector._id.$in instanceof Array ) && | |
| // Make sure there are no additional selector criteria. There | |
| // should be only one selector for _id, which, in turn, should | |
| // only be one condition for $in. | |
| ( Object.keys( options.selector ).length === 1 ) && | |
| ( Object.keys( options.selector._id ).length === 1 ) && | |
| // In addition to the _id selector, we want to make sure the user | |
| // hasn't defined any other query criteria. If they have, then | |
| // the logic is more complicated than a simple _id search. | |
| ! options.hasOwnProperty( "limit" ) && | |
| ! options.hasOwnProperty( "skip" ) && | |
| ! options.hasOwnProperty( "sort" ) && | |
| ! options.hasOwnProperty( "fields" ) && | |
| ! options.hasOwnProperty( "r" ) && | |
| ! options.hasOwnProperty( "conflicts" ) | |
| ); | |
| } | |
| } | |
| ); | |
| // --------------------------------------------------------------------------- // | |
| // --------------------------------------------------------------------------- // | |
| var dbName = "javascript-demos-pouchdb-find-playground"; | |
| // Creating the PouchDB database instance is a synchronous operation. This means | |
| // that we can immediately start to interact with the "db" object. | |
| var db = new PouchDB( dbName ); | |
| // When I am playing around with PouchDB, I like to destroy and recreate the | |
| // database on each test run. This way, any conflicts with existing data are | |
| // explicitly coded into the experiment and not a byproduct of dirty data. | |
| db.destroy().then( | |
| function() { | |
| // Once we destroy the database, we have to create a new one otherwise | |
| // we'll get an error, "Error: database is destroyed". | |
| db = new PouchDB( dbName ); | |
| } | |
| ) | |
| // At this point, we have a pristine PouchDB instance to experiment with. Every | |
| // PouchDB operation returns a Promise (though you could use a Callback if you | |
| // wanted to for some reason). So, to start experimenting, we can just chain the | |
| // "thenable" operations together. | |
| .then( | |
| function() { | |
| // Let's insert some Friend data. | |
| var promise = db.bulkDocs([ | |
| { | |
| _id: "friend:kim", | |
| name: "Kim" | |
| }, | |
| { | |
| _id: "friend:sarah", | |
| name: "Sarah" | |
| }, | |
| { | |
| _id: "friend:joanna", | |
| name: "Joanna" | |
| } | |
| ]); | |
| return( promise ); | |
| } | |
| ).then( | |
| function() { | |
| // Now that we've inserted our Friends, we can immediately access those | |
| // friends using the "default" index (ie, the one implicitly created on | |
| // the _id field). | |
| // -- | |
| // CAUTION: This does NOT SEEM TO BE THE CASE with the $in operator. | |
| // While you might expect this to map directly to the allDocs() "keys" | |
| // filter, .find() will warn us that NO INDEX could be found. | |
| var promise = db.find({ | |
| selector: { | |
| _id: { | |
| $in: [ "friend:kim", "friend:sarah" ] | |
| } | |
| }, | |
| // NOTE: Using limit to ensure monkey-patched find() is skipped. | |
| limit: 2 | |
| }); | |
| promise.then( | |
| function( results ) { | |
| console.group( "ONE: Found %s friends by _id AND limit.", results.docs.length ); | |
| results.warning && console.warn( results.warning ); | |
| results.docs.forEach( | |
| function( doc ) { | |
| console.log( doc.name, "-", doc._id ); | |
| } | |
| ); | |
| console.groupEnd(); | |
| } | |
| ); | |
| return( promise ); | |
| } | |
| ).then( | |
| function() { | |
| // This time, we're going to omit the LIMIT so that we have a query | |
| // configuration that contains nothing more than a collection of ids. | |
| // This way, our monkey-patched .find() method will route the request | |
| // into an .allDocs({ keys }) query. | |
| var promise = db.find({ | |
| selector: { | |
| _id: { | |
| $in: [ "friend:kim", "friend:sarah" ] | |
| } | |
| } | |
| }); | |
| promise.then( | |
| function( results ) { | |
| console.group( "TWO: Found %s friends by _id.", results.docs.length ); | |
| results.warning && console.warn( results.warning ); | |
| results.docs.forEach( | |
| function( doc ) { | |
| console.log( doc.name, "-", doc._id ); | |
| } | |
| ); | |
| console.groupEnd(); | |
| } | |
| ); | |
| return( promise ); | |
| } | |
| ).catch( | |
| function( error ) { | |
| console.warn( "An error occurred:" ); | |
| console.error( error ); | |
| } | |
| ); | |
| </script> | |
| </body> | |
| </html> |
As you can see, my .find() method is rather straightforward: it inspects the given selector and then either uses .allDocs() for a keys-based lookup; or falls back to the original .find() plugin. Once my plugin is defined, I then attempt two different searches for a collection of _id values. In the first search, I'm including the "limit" value just to make sure that the .allDocs() approach is skipped.
When we run the above code, we get the following output:
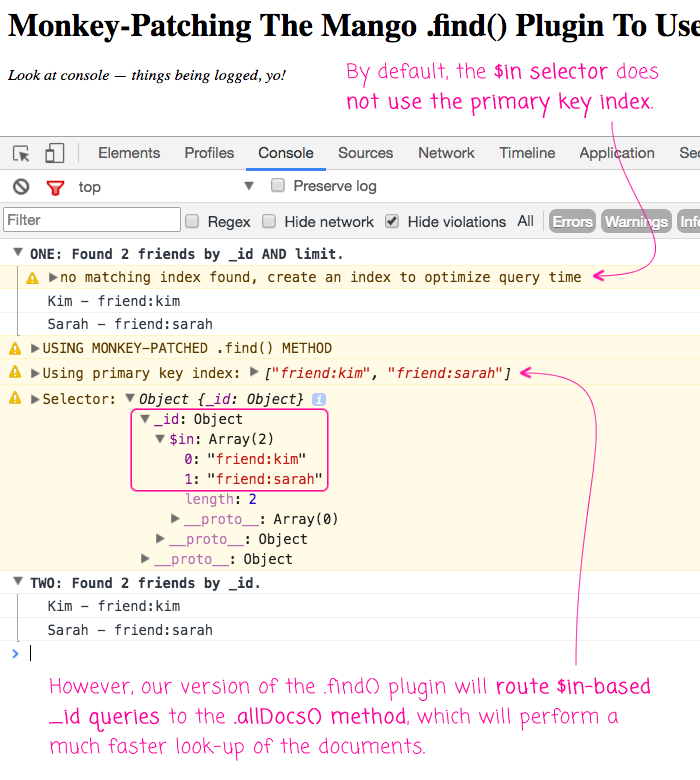
As you can see, the first _id and $in-based query warns us that the Mango .find() plugin could not locate an efficient index. As such, it had to do a full-collection scan. However, in the second query, the monkey-patched .find() method is routing the request to the primary key index, via .allDocs(), where the lookup can be done much more efficiently.
PouchDB's new .find() plugin is very nice in the way it provides a unified interface for searching both the primary key index and [some of] the secondary indices. However, it seems to have a gap in the way some of the selector criteria get translated into query plans. Luckily, PouchDB's plugin architecture is flexible enough that we can step in and fill in the performance gaps with some simple code.
Want to use code from this post? Check out the license.
Reader Comments
Hi Ben,
I thought you might find this interesting. Here is an example of using the allDocs with the keys option and then doing further filtering via the pouchdb-find in-memory selectors.
https://gist.github.com/garrensmith/52bd16c086c46dfe2461c6cdedf8943e
@Garren,
Ah, very interesting. I didn't realize the selector stuff could be used directly (or perhaps that somewhat of an undocumented feature). That's cool, though - is that basically the pattern that .find() uses -- get primary payload from allDocs(), then filter in-memory with selectors?
@Ben,
It is undocumented because its a semver free zone :)
Its possible to use the pouchdb-find selectors in the changes feed and in replication and it uses a similar pattern internally.
This pattern is used by default if no other index is available. Otherwise instead of allDocs it will first use the index and then the in-memory filtering.
Some self promotion :) but I wrote a blog post explaining how pouchdb-find works internally http://www.redcometlabs.com/blog/2015/12/1/a-look-under-the-covers-of-pouchdb-find
@Garren,
Ah, very cool - reading now.