
PouchDB Data Modeling For My Dig Deep Fitness Offline First Mobile Application
CAUTION: I am just a CouchDB / PouchDB novice trying to think-out-loud about data modeling with this particular NoSQL database. I am in no way expert and all remarks made below should be taken with that perspective.
After years of neglect, I've decided to rebuild my web-based fitness application - Dig Deep Fitness - as an offline-first mobile application. Not only would this give me an opportunity to learn about relatively new technologies like Service Workers, it would also let me look at leveraging older technologies like PouchDB and CouchDB to provide offline data storage. With an offline-first approach, I could actually track my workouts in my garage gym, which doesn't get consistent cell reception. PouchDB, which implements the CouchDB API in JavaScript, is a NoSQL ("Not Only" SQL) database that stores JSON (JavaScript Object Notation) documents. I have very little experience with NoSQL, and no experience at all with CouchDB, so I wanted to publicly noodle on some data modeling in case anyone had any constructive feedback.
After doing some research in the world of "offline first" mobile applications, I decided to go with PouchDB because of its replication protocol. Or rather, CouchDB's replication protocol, which PouchDB implements on top of various storage engines (like IndexedDB and WebSQL). Unlike many databases, CouchDB allows for master-master replication, which means that I can write to an offline master database on my mobile device and then "easily" sync those offline records to a remote master database in the cloud (for eventual consistency). That remote master database could then, in turn, sync back down to other offline-first databases.
Another alluring aspect of CouchDB is its ability to use a "database per user" infrastructure (if you so desire). In the world of CouchDB, a database is just a set of flat files. So, creating another database is as simple as creating a new file (which CouchDB does for you). The attraction of the database-per-user approach is that all of the data in a given database pertains to a single user. This means you never have to worry about filtering based on user. And, since CouchDB only support security at the database level, it's nice to be able to lock a given database down to a single user when you're making direct calls from a mobile client to the remote database and don't have a web-tier in the middle negotiating security.
NOTE: There are, apparently, some long-term operational complexities with the database-per-user approach (such as backups). This is why Cloudant is developing "Envoy" - a service that exposes a database-per-user API in front of a single-database persistence mechanism.
For my offline first application, I'm using the "database per user" approach; but, I'm punting on the problem of authentication and the use of a remote master database. I assume that I'll be able to tackle those problems down the road when I have a better understanding of how PouchDB and CouchDB work. This is why none of my data modeling has any user relationships - all data will be assumed to belong to a single user, with security being applied at the database level.
NOTE: The only Database as a Service (DBaaS) that I could find for CouchDB was Cloudant. There was one called Iris Couch; but, it no longer appears to be accepting sign-ups at this time. Of course, you can always run your own CouchDB server (or cluster as of CouchDB 2.0).
On To The Data Modeling
Dig Deep Fitness is a fitness application with a very small scope. It revolves around just a few basic concepts:
- Exercices - These represent the type of physical activities one can perform in the gym.
- Workouts - These represent a collection of exercises performed in one cohesive fitness session.
- Lift - These represent the execution of a given exercise during a given workout.
- Set - These represent a single effort performed during a lift.
That's it - that's all there is to it. No fitness routines, no calorie tracking, no instructional videos, no unlocking badges. It's just simple fitness for serious people. But, "simple" doesn't mean "obvious" when I'm dealing with completely new (to me) technologies like CouchDB.
Key Schema
In PouchDB and CouchDB, there is only one collection of documents. Exercises, Workouts, Lifts, etc. - they all go into the same key-value store as part of the primary key index. As such, we need a way to differentiate one document type from another. We can do this using an embedded document attribute (ex, doc.type = "exercise"); or, we can build the type into the document key itself (ex, "exercise:1234" => doc).
From what I can see, the benefit of building logic into the key-structure is that you don't [always] need to create a secondary index in order to find the data that you're looking for. This requires fewer files on disk and therefore saves space; but, it doesn't necessarily provide a performance savings. After all, both the primary index and the secondary indices are all stored in B+tree structures that are very fast.
That said, secondary view indices are incrementally-updated lazily, which means that additional processing may have to be done on new or modified documents at the onset of your next search operation. From that point of view, you could argue that key-based logic is better for performance since the primary key index is always up-to-date.
Building your own key, of course, means that you - as the developer - take on the burden of uniqueness. By default, PouchDB will generate a UUID (Universally Unique Identifier) for you (with the .post() operation); but, if you build logic into the key, it means that you have to generate the key which means there is no UUID to leverage for uniqueness.
For Dig Deep Fitness, I've decided to build the type differentiator - and other meaningful meta-data - into the key itself:
Exercises: "exercise:${ utc-milliseconds }" - ex, "exercise:1233992" - Since all exercises belong to a single user, using UTC milliseconds as part of the key should be sufficient for global uniqueness. I'm specifically not using the exercise Name as part of the key since the name can be tweaked and changed over time.
Workouts: "workout:${ date-string }" - ex, "workout:2016-12-12-05-52-01" - Unlike exercises, where all I care about is uniqueness, the date is meaningful for a workout. Using the date string should be sufficient, business-wise, for uniqueness; but, using a date string in the key also provides implicit sorting of workouts by date. Meaning, if I want to grab the most recent workout, I just need to get the first workout, sorted by key in descending order (see example below).
Lift: "lift:${ exercise-id }:${ date-string }" - ex, "lift:1233992:2016-12-28-14-00-34" - Since a lift is a specific execution of an exercise, I am using the exercise ID (or at least the numeric potion) as part of the lift key. This will allow me to use the primary key index to look up all lifts for a particular exercise. Then, I'm using a date-string at the end of the key so that I can query for the lifts in date order.
Set: In a relational database, I would break Sets out into their own table. But, in a document database, these don't feel like they have a reason to stand on their own. As such, I'm building them directly into the Lift schema.
To be clear, all keys could just have easily been UUIDs; and, all of the benefits of having manually-generated primary keys could have been accomplished using secondary indices. When it comes down to it, I don't have a really strong argument for one approach or the other. I could even argue that using UUIDs across the board would have been less complex and provided a simpler mental model for the consumer. But, I'm going with "smart keys" because Nolan Lawson has repeatedly suggested that we "use and abuse document IDs" to obtain free indexing:
Luckily, it turns out that the primary index, _id, is often good enough for a variety of querying and sorting operations. So if you're clever about how you name your document _ids, you can avoid using map/reduce altogether.... If you're just using the randomly-generated doc IDs, then you're not only missing out on an opportunity to get a free index - you're also incurring the overhead of building an index you're never going to use. So use and abuse your doc IDs!
So, I'm trying it and seeing how it feels.
Document Schema
Now that we have the initial key schema outlined, we can look at the data we'll actually store in our documents. Because I am using "meaningful keys", some of the meta-data for a document could theoretically be extracted from the key itself. For example, in the case of an Exercise, I am storing the UTC-millisecond time-stamp in the key. This could, theoretically, give me the "created at" date for the Exercise. But, I don't want to start thinking about the key as part of the "data storage". Any data that may have been available via key-parsing will, instead, be represented as properties of the associated document. The keys are for look-ups, the document is for data. I like having a clean separation of responsibilities.
Exercise, "exercise:${ utc-milliseconds }":
{
_id: string;
_rev: string;
name: string;
description: string;
isPush: boolean;
isPull: boolean;
isLegs: boolean;
isFavorite: boolean;
createdAt: number;
}
Since I'm using a "database per user" approach, I can build the "isFavorite" concept right into the exercise itself. I don't have to worry about "joining" a "favorite indicator" to the exercise record, the way I might in a multi-tenant relational database design.
Workout, "workout:${ date-string }":
{
_id: string;
_rev: string;
createdAt: number;
}
There's not much going on in a workout. A workout really just ties together a number of exercises.
Lift, "lift:${ exercise-id }:${ date-string }":
{
_id: string;
_rev: string;
workoutId: string;
exercise: {
_id: string;
name: string;
isFavorite: boolean;
description: string;
}
note: string;
sets: [
{
resistance: string;
performance: string;
note: string;
}
...
]
createdAt: number;
}
As I stated above, I'm building the concept of Sets into the Lift document itself. But, the interesting part of this document is the duplication of some Exercise data. Rather than storing just an "exerciseId" key reference, I'm copying some of the relevant Exercise data right into the Lift itself. Part of this is to make the view rendering easier; but, part of it is philosophical. A "lift" is a snapshot in time of a particular understanding of an exercise and the effort that goes into performing that exercise. As such, I think it makes sense that the name, description, and "favoriteness" of the exercise also be captured at that moment.
Another benefit of this denormalization is that if the referenced Exercise is ever deleted, the Lifts associated with that exercise will be kept on record with enough information to function properly as an historical document. I don't want to undo history with a sigle delete.
Views / Secondary Indices
In both SQL and CouchDB, secondary indices are about finding data. But, with SQL, you get a lot more flexibility in how a table index gets applied. Meaning, based on various table JOINs, an index can be leveraged to gather different combinations of data. In CouchDB, there are no JOINs. So, in CouchDB, views and secondary indices are much less about "what data do I have," and much more about "what data do I need". With NoSQL in general, and perhaps even more so with CouchDB, secondary indices are about View rendering.
As such, in order to get a sense of what database Views we need to create, we need to walk through the important views in the application.
NOTE: These prototype screens actually have more functionality than I am currently dealing with. Remember that I am punting on the concept of authentication.
Home Screen
On the home screen, the only piece of data that I need to query for is the last workout such that it can be "resumed" if it exists. For this, we don't actually need a database View. Since we are storing our Workouts using keys that contain time-strings, we can access the most recent workout using the primary key index and the .allDocs() method with a limit of 1.
var promise = db
// Load some sample workout data into the database. Notice that the ID for each
// workout is prefixed with "workout:" and then uses a date-string that will sort
// "naturally" as an ASCII value.
.bulkDocs([
{
_id: "workout:2016-12-11-15-07-43",
createdAt: 1481486863000
},
{
_id: "workout:2016-12-12-14-00-15",
createdAt: 1481569215000
}
])
.then(
function( result ) {
// The .allDocs() allows us to leverage the persisted sort of the primary
// key index. Since the workouts are keyed by date, we can get the most
// recent workout by get the "last" (descending, limit 1) workout.
return db.allDocs({
startKey: "workout:\uffff", // NOTE: Not entirely sure I need \uffff here.
include_docs: true,
// Get the last one based on the persisted index sort.
limit: 1,
descending: true
});
}
)
.then(
function( results ) {
console.log( "Most recent workout:" );
console.log( results.rows[ 0 ].doc );
}
)
;
Exercise List Screen
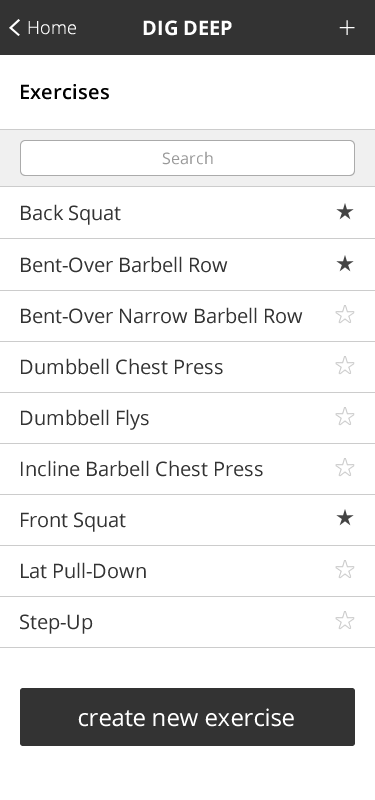
On the exercise list page, we could theoretically create a View that collates the exercises by "name". But, the same thing can be accomplished with a simple client-side .sort() operation on the resultant collection. As such, it seems a bit wasteful to create an additional index (which would necessitate another B+tree and file on disk) for an entire subsection of the key-space.
As far as accessing the exercises, we can simply use the primary key index and the .allDocs() method with a startkey and endkey range query:
var promise = db
// Load some sample exercise data into the database. Notice that the ID for each
// exercise is prefixed with "exercise:" and then uses a number for uniqueness. Since
// this number is not "meaningful", we won't be able to leverage the sort of the
// primary key index (with regard to the Name of the exercise).
.bulkDocs([
{
_id: "exercise:1234",
name: "Dumbbell Bench Press"
// ...
},
{
_id: "exercise:4830",
name: "Barbell Back Squat"
// ...
},
{
_id: "exercise:223",
name: "Weighted Dips"
// ...
}
])
.then(
function( result ) {
// The .allDocs() allows us to query for all keys that start with the
// prefix, "exercise:", by using a range query (inclusive by default). Since
// we're searching on a range, we need to give it an upper-end of the range
// to stop on. We can use a high Unicode character - \uffff - to provide a
// meaningful limit.
return db.allDocs({
startkey: "exercise:",
endkey: "exercise:\uffff",
include_docs: true
});
}
)
.then(
function( results ) {
// Since the key-space for the "exercise:" documents isn't sorted in a
// meaningful way, we can just sort it after the query.
results.rows.sort(
function( a, b ) { console.log( a.doc, b.doc );
var aName = a.doc.name.toLowerCase();
var bName = b.doc.name.toLowerCase();
return( ( aName < bName ) ? -1 : 1 );
}
);
console.log( "Exercises:" );
console.log( results.rows );
}
)
;
Workout Screen
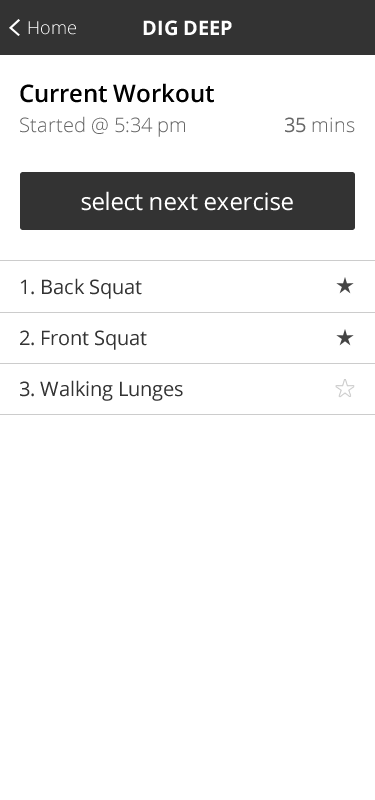
On the workout screen, we need to gather two sets of data: the workout record and all of the lifts associated with that workout. The workout can be queried directly by key; but, the lifts are keyed by exercise, not by workout. As such, we'll need a secondary index to gather the lifts by workout ID.
Here's where I'm still very fuzzy on "best practices" view creation in PouchDB. I've read several articles talking about returning mixed doc-types in a single View so as to reduce the number of calls that need to be made to the CouchDB database over HTTP. However, since I know that I am using PouchDB to connect to a local data store (hence the offline first approach), I am not sure that it's worth the complexity of creating these heterogeneous views. As such, for this application, I'm going to gather each set of data in its own call.
Therefore, the workout can be queried by key. And, we'll create a secondary index for Lifts based on Workout:
var promise = db
// Load some sample lift data into the database. Notice that the ID for each
// lift is prefixed with "lift:" and then numeric portion of the exercise key and a
// time string. Since none of these values pertain to the workout, we won't be able
// to query the primary key index.
.bulkDocs([
{
_id: "lift:223:2016-12-11-15-27-59",
workoutId: "workout:2016-12-11-15-07-43",
exercise: {
_id: "exercise:4830",
name: "Barbell Back Squat"
// ...
},
sets: [],
createdAt: 1481488079000
},
{
_id: "lift:223:2016-12-12-14-18-59",
workoutId: "workout:2016-12-12-14-00-15",
exercise: {
_id: "exercise:223",
name: "Weighted Dips"
// ...
},
sets: [],
createdAt: 1481570339000
}
])
.then(
function( result ) {
// Since the primary key index won't allow us to search for lifts by workout,
// we'll have to create a persisted query (View) that indexes the lifts by
// the workout ID. And, since we want the lifts to be sorted in the same
// order in which they were executed, we'll emit a compound key which sorts on
// the workout first, and the creation-date second.
return db.put({
_id: "_design/lifts-by-workout",
views: {
"lifts-by-workout": {
map: function( doc ) {
if ( doc._id.indexOf( "lift:" ) === 0 ) {
// The compound key sorts on workoutId AND createdAt.
// This way, when we query the docs, they will come out
// of the database in proper order.
emit( [ doc.workoutId, doc.createdAt ] );
}
}.toString()
}
}
});
// From the documentation on design document names:
// --
// Technically, a design doc can contain multiple views, but there's really
// no advantage to this. Plus, it can even cause performance problems in
// CouchDB, since all the indexes are written to a single file. So we
// recommend that you create one view per design doc, and use the same name
// for both, in order to make things simpler.
}
)
.then(
function( result ) {
// When querying with a secondary index, we have to use the .query() method
// instead of the .allDocs() method. The concept is the same (searching a
// B+tree). This time, however, since our index has a compound key, we have
// search with a compound key range.
return db.query(
"lifts-by-workout",
{
startkey: [ "workout:2016-12-12-14-00-15" ],
endkey: [ "workout:2016-12-12-14-00-15", {} ],
include_docs: true
}
);
}
)
.then(
function( results ) {
console.log( "Lifts in this workout:" );
console.log( results.rows );
}
)
;
In this persisted query (ie, View), I'm emitting an array of values rather than a simple value. This creates a compound index in which the view is indexed and collated based on both parts of the emitted value. Since we want to render our lifts in the same order in which they were entered into the application, adding the secondary collation on "createdAt" forces PouchDB to persist the lifts in both workoutId and createdAt order in the B+tree.
This is convenient for access speed, but it does mean that our .query() method is a bit more complex. Rather than querying for a simple key range, we have to query for a compound index range, in which the "{}" empty object takes the place of "\uffff" as the "high value".
Lift Screen

On the lift screen, we need to gather two sets of data: the current Lift record and the previous lifts for the same exercise. We could also query for the Workout itself, to validate existence; but, since we're not outputting any workout-level information, the extra validation doesn't seem necessary.
The lift can be queried directly based on the key. And, as it turns out, so can the previous lift attempts. Since our Lift key is based (in part) on the exercise ID, we can use the primary key index and the .allDocs() method to query for recent lifts after we figure out which exercise the given lift is referencing:
// Lifts are keyed against the exercise ID (in part) and a date-string that will sort
// naturally. This means that we can query for previous attempts at any given exercise
// by searching for all lifts with the proper exercise prefix.
var promise = db
.allDocs({
descending: true,
// Since we sorting in a DESCENDING order, we have to switch what you might
// consider the "start" and "end" keys.
startkey: "lift:223:\uffff",
endkey: "lift:223:",
// Skip the "current" lift, only return previous lifts.
skip: 1,
include_docs: true
})
.then(
function( results ) {
console.log( "Previous attempts at this lift:" );
console.log( results.rows );
}
)
;
There's a bit more to the app than that; but, those are the main screens and the secondary indices / Views that are needed to render them.
After Two Days Of Writing And One More Night Of Sleep
I had hoped that writing up these notes would allow me to walk away from this PouchDB brainstorming with confidence that I'm moving in the right direction. But, the truth is, I feel just as frustrated and confused as I did at the onset. To be honest, it's frustrating that PouchDB and CouchDB have both a primary key index and secondary view indices. It means that I have to be able to justify my choice of one or the other; and, I don't think that this justification is easy to make (especially at the onset of a project where your choice will influence the code in your application).
Imagine for a moment that there was no primary key index, except for direct access, like in the NoSQL database Redis. In that case, I would be forced to use Views to access collections of data and it wouldn't matter if the keys were UUIDs or some other semantic token. At the end of the day, I would have all the same functionality as I did before; but, at best guess, it would be in a format that would be easier to understand and program against.
Perhaps my biggest frustration with the primary key index in PouchDB is that it couples the experience of the application to the actual storage of the documents. By that, I mean that the usage pattern of the application influences the keys that I use. For example, I built the exerciseId into the lift key because it made sense to query for lifts by exercise. But, this only made sense because the application UI (User Interface) called for it. Had I never needed to list related lifts, I would have likely chosen a different key structure.
And, therein lies the frustration - that I'm architecting a fundamental part of the persistence layer based on a possibly-transient aspect of the application experience. This just feels wrong. It has a "smell" to it. For secondary indices / Views, this coupling doesn't bother me because that's the point of the View - data access. But, for the core key structure itself, something just doesn't sit well with me.
That said, I will likely continue on with the "creative keying" approach that I've outlined if, for no other reason, it forces me to get outside of my comfort zone. After 15 years of working with relational database management systems (RDBMS), I expect NoSQL to make me feel funny, like when I used to climb the ropes in gym class. So, rather than trying to fit PouchDB into a SQL-shaped box, I'm going to try and use the practices that other PouchDB enthusiasts seem to suggest.
Want to use code from this post? Check out the license.
Reader Comments