You're reading the free online version of this book. If you'd like to support me, please considering purchasing the e-book.
Feature Flags, an Introduction
I've been working in the web development industry since 1999; and, before 2015, I'd never heard the term, "feature flag" (or "feature toggle", or "feature switch"). When my Director of Product—Christopher Andersson—pulled me aside and suggested that feature flags might help us with our company's downtime problem, I didn't know what he was talking about.
Cut to me in 2024—after 9 years of trial and error—and I can't imagine building another product or platform without feature flags. They have become a critical part of my success. I put feature flags in the same category as I do logs and metrics: the essential services upon which all product performance and stability are built.
But, it wasn't love at first sight. In fact, when Christopher Andersson described feature flags to me in 2015, I didn't see the value. After all, a feature flag is just an if statement:
if ( featureIsEnabled() ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}I already had control flow that looked like this in my applications (see The Status Quo). As such, I didn't understand why adding yet another dependency to our tech-stack would make any difference in our code, let alone have a positive impact on our downtime.
What I failed to see then was the fundamental difference underlying the two techniques. In my approach, changing the behavior of the if statement meant updating the code and re-deploying it to production. But, with feature flags, changing the behavior of the if statement meant flipping a switch.
That's it.
No code updates. No deployments. No latency. No waiting.
This is the magic of feature flags: having the ability to dynamically change the behavior of your application at runtime. This is what sets feature flags apart from environment variables, build flags, and any other type of deploy-time or dev-time setting.
To stress this point: if you can't dynamically change the behavior of your application without touching the code or the servers, you're not using "feature flags". The dynamic runtime nature isn't a nice-to-have, it's the fundamental driver that brings both psychological safety and inclusion to your organization.
This dynamic nature means that in one moment, our feature flag settings look like this:

Which means that our application's control flow operates like this:
if ( featureIsEnabled() /* false */ ) {
// ... dormant code ...
} else {
// This code is executing!
}The featureIsEnabled() function is currently returning false, directing all incoming traffic through the else block.
Then, if we flip the switch on in the next moment, our feature flag settings look like this:

And, our application's control flow operates like this:
if ( featureIsEnabled() /* true */ ) {
// This code is executing!
} else {
// ... dormant code ...
}Instantly—or thereabouts—the featureIsEnabled() function starts returning true; and, the incoming traffic is diverted away from the else block and into the if block, changing the behavior of our application in near real-time.
But, turning a feature flag on is only half the story. It's equally important that a feature flag can be turned off. Which means that, should we need to in the case of emergency, we can instantly disable the feature flag settings:
Which will immediately revert the application's control flow back to its previous state:
if ( featureIsEnabled() /* false */ ) {
// ... dormant code ...
} else {
// This code is executing (( again ))!
}Even with the illustration above, this is still a rather abstract concept. To convey the power of feature flags more concretely, let's dip-down into the use-case that opened my eyes up to the possibilities: refactoring a SQL database query.
The efficiency of a SQL query changes over the lifetime of a product. As the number of rows increases and the access patterns evolve, some SQL queries start to slow down. This is why database index design is just as much art as it is science.
Traditionally, this type of refactoring involves running an EXPLAIN query, looking at the query plan bottlenecks, and then updating the SQL in an effort to better leverage existing table indices. The updated query code is then deployed to the production server. And, what the we hope to see is a latency graph that looks like this:
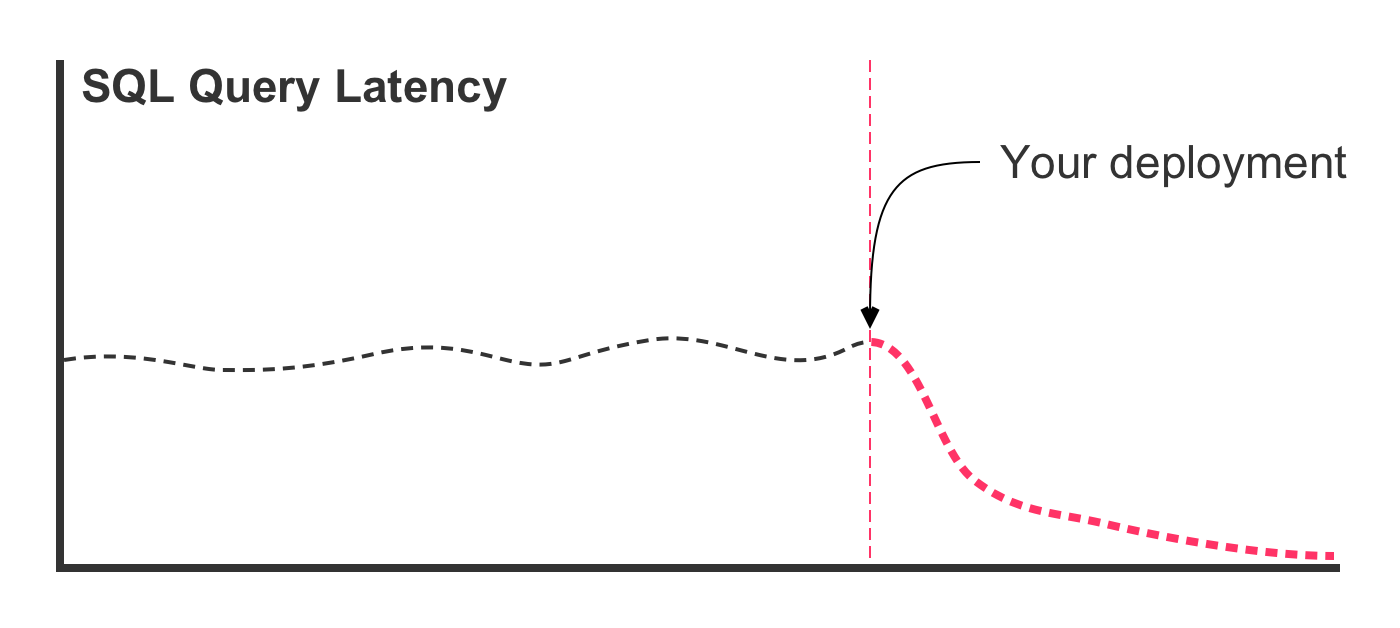
In this case, the SQL refactoring was effective in lowering the latency times. But, this is the best case scenario. In the worst case scenario, deploying the refactored query leads to a latency graph that looks more like this:
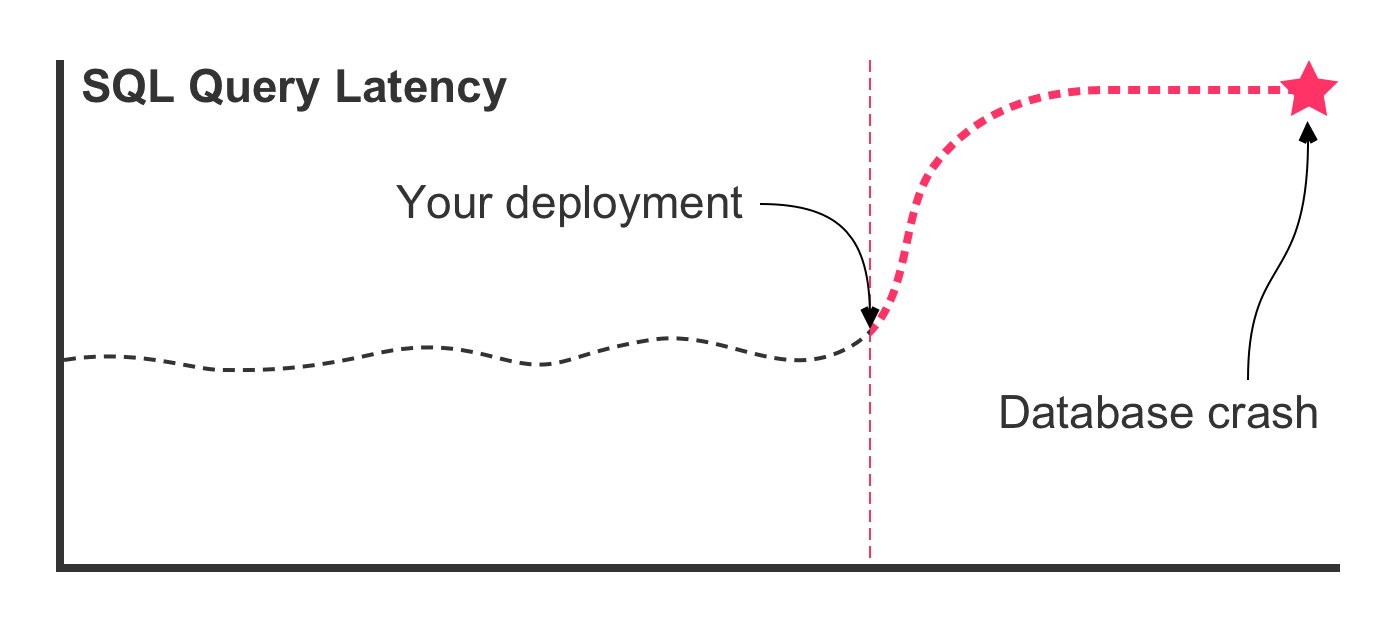
In this case, something went terribly wrong! The new SQL query that performed well in your development environment does not perform well in production. The query latency rockets upward, consuming most of the database's available CPU. This, in turn, slows down all queries executing against the database. Which, in turn, leads to a spike in concurrent queries. Which, in turn, starves the thread pool. Which, in turn, crashes the database.
If you see this scenario beginning to unfold in your metrics, you might try to roll-back the deployment. Or, you might try to revert the code and redeploy it. In either case, it's a race against time. Pulling down images, spinning up new nodes, warming up containers, starting applications, running builds, executing unit tests: it all takes time—time that you don't have.
Now, imagine that, instead of replacing your code and deploying it, you design an optimized SQL query and gate it behind a feature flag. Code in your data-access layer could look like this:
public array function generateReport( userID ) {
// Use new optimized SQL query.
if ( featureIsEnabled() ) {
return( getData_withOptimization( userID ) );
}
// Fall-back to old SQL query.
return( getData( userID ) );
}In this approach, both the existing SQL query and the optimized SQL query get deployed to production. However, the optimized SQL query won't be "released" to the users until the feature flag is enabled. And, at that point, the if statement will short-circuit the control flow and all new requests will use the optimized SQL query.
With a feature flag gating the new query, our worst case scenario looks strikingly different:
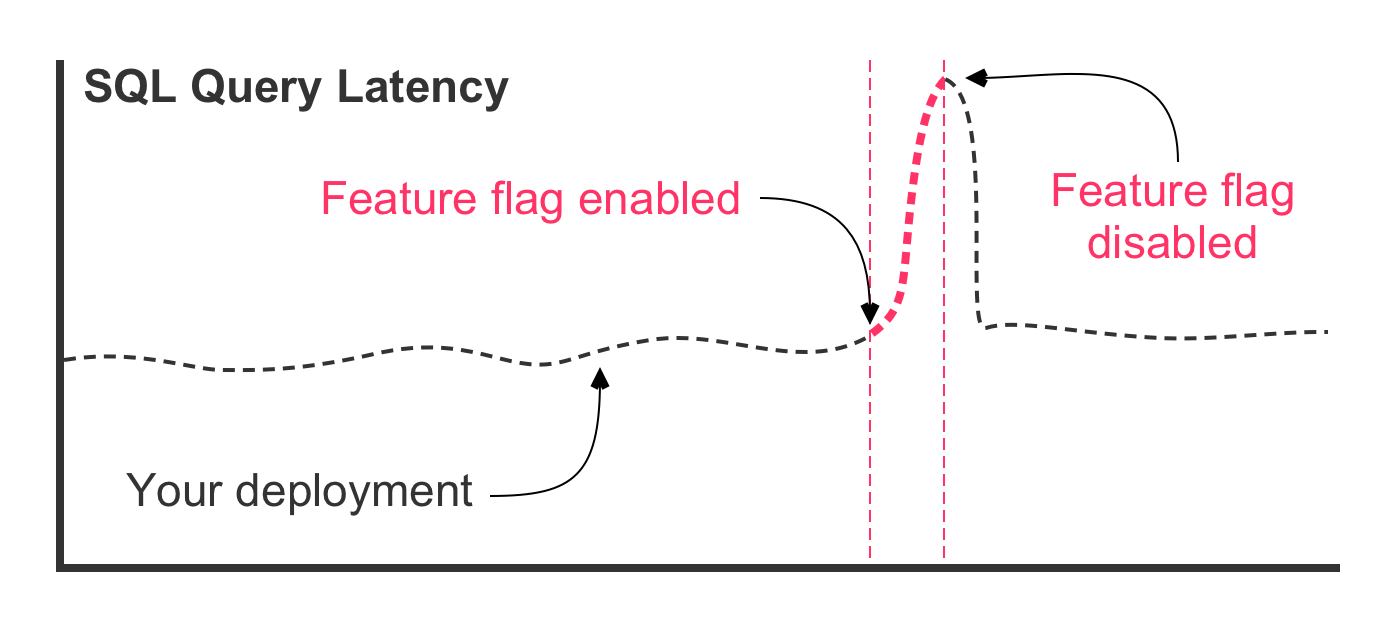
The same unexpected SQL performance issues exist in this scenario. However, the outcome is very different. First, notice (in the figure) that the deployment itself had no effect on the latency of the query. That's because the optimized SQL query was deployed in a dormant state behind the feature flag. Then, the feature flag was enabled, causing traffic to route through the optimized SQL query. At this point, that latency starts to go up. But, instead of the database crashing, the feature flag is turned off, immediately re-gating the code and diverting traffic back to the original SQL query.
You just avoided an outage. The dynamic runtime capability of your feature flag gave you the power to react without delay, before the database—and your application—became overwhelmed and unresponsive.
Are you beginning to see the possibilities?
Knowing that you can disable a feature flag in case of emergency is empowering. This alone creates a huge amount of psychological safety. But, it's only the beginning. Even better is to completely avoid an emergency in the first place. And, to do that, we have to dive deeper into the robust runtime functionality of feature flags.
In the previous thought experiment, our feature flag was either entirely on or entirely off. This is a vast improvement over the status quo; but, this isn't really how feature flags get applied. Instead, a feature flag is normally rolled-out incrementally in order to minimize risk.
But, before we can think incrementally, we have to understand a few new concepts: targeting and variants. Targeting is the act of identifying which users will receive a given a variant. A variant is the value returned by evaluating a feature flag in the context of a given request.
To help clarify these concepts, let's take the first if statement—from earlier in the chapter—and factor-out the featureIsEnabled() call. This will help separate the feature flag evaluation from the subsequent control flow and consumption:
var booleanVariant = featureIsEnabled();
if ( booleanVariant == true ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}In this example, our feature flag uses a Boolean data type, which can only ever represent two possible values: true and false. These two values are the variants associated with the feature flag. Targeting for this feature flag then means figuring out which requests receive the true variant and which requests receive the false variant.
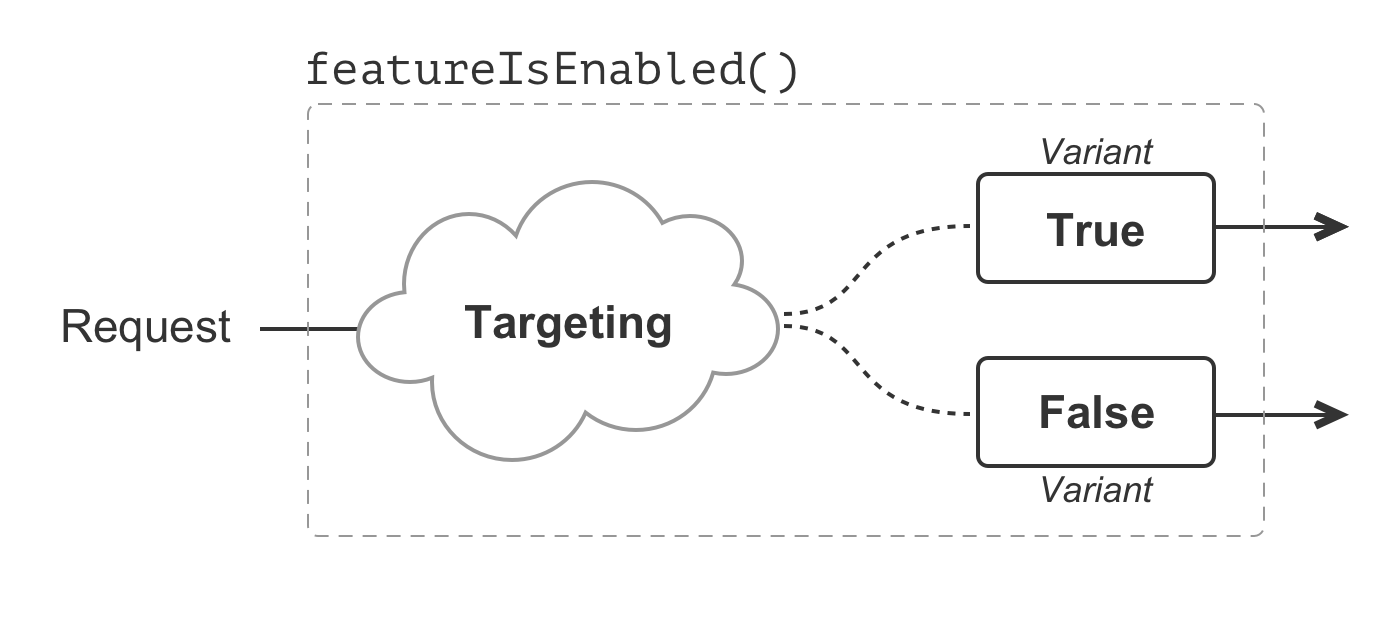
Boolean feature flags are, by far, the most common. However, a feature flag can represent any kind of data type: Booleans, strings, numbers, dates, JSON (JavaScript Object Notation), etc. The non-Boolean data types may compose any number of variants and can unlock all manner of compelling functionality. But, for the moment, let's stick to our Booleans.
Targeting—the act of funneling requests into a specific variant—requires us to provide identifying information as part of the feature flag evaluation. There's no "right type" of identifying information—each evaluation is going to be context-dependent; but, I find that User ID and User Email are a great place to start (for user-facing features).
Let's update our feature flag evaluation to include context about the current user:
var booleanVariant = featureIsEnabled(
userID = request.user.id,
userEmail = request.user.email
);
if ( booleanVariant == true ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}Throughout this book, I'm going to refer the request object as a means to access information about the incoming HTTP request. The request object has nothing to do with feature flags; and, is here only to provide the values that we need in order to illustrate targeting:
request.user- contains information about the authenticated user making the request. This will include properties likeidandemail(as shown above).request.client- contains information about the browser making the request. This will include properties likeipAddress.request.server- contains information about the server that is currently processing the request. This will include properties likehost.
Once we incorporate this identifying information into our feature flag evaluation, we can begin to differentiate one request from another. This is where things get exciting. Instead of our feature flag being entirely on for all users, perhaps we only want it to be on for an allow-listed set of User IDs. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
switch ( userID ) {
// Feature is enabled for these users only.
case 1:
case 2:
case 3:
case 4:
return( true );
break;
// Feature is disabled for everyone else by default.
default:
return( false );
break;
}
}Or, perhaps we only want the feature flag to be on for users with an internal company email address. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
if ( userEmail contains "@bennadel.com" ) {
return( true );
}
return( false );
}Or, perhaps we only want the feature flag to be enabled for a small percentage of users. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// Reduce all user IDs down to a value between [0..99].
var userPercentile = ( userID % 100 );
if ( userPercentile <= 5 ) {
return( true );
}
return( false );
}In this case, we're using the modulo operator to consistently translate the User ID into a numeric value. This numeric value gives us a way to consistently map users onto a percentile: each additional remainder represents an additional 1% of users. Here, we're enabling our feature flag for a consistently-segmented 5% of users.
Note: We go into more depth about %-based targeting in a future chapter. Don't worry if this concept is confusing. Just accept, for now, that we can consistently target a percentage of our users.
We can even combine several different targeting concepts at once in order to apply more granular control. Imagine that we only want to target internal company users; and, of those targeted users, only enable the feature for 25% of them:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// First, target users based on email.
if ( userEmail contains "@bennadel.com" ) {
var userPercentile = ( userID % 100 );
// Second, target users based on percentile.
if ( userPercentile <= 25 ) {
return( true );
}
}
return( false );
}User targeting, combined with a %-based rollout, is an incredibly powerful part of the feature flag workflow. Now, instead of enabling a risky feature for all users at one time, imagine a much more graduated rollout using feature flags:
- Deploy dormant code to production servers—no user sees any initial difference or impact within the application.
- Enable feature flag for your user ID.
- Test feature in production.
- Discover a bug.
- Fix bug and redeploy code (still only active for your user).
- Examine error logs.
- Enable feature flag for internal company users.
- Examine error logs and metrics.
- Discover bug(s).
- Fix bug(s) and redeploy code (still only active for internal company users).
- Enable feature flag for 10% of all users.
- Examine error logs and metrics.
- Enable feature flag for 25% of all users.
- Examine error logs and metrics.
- Enable feature flag for 50% of all users.
- Examine error logs and metrics.
- Enable feature flag for 75% of all users.
- Examine error logs and metrics.
- Enable feature flag for all users.
- Celebrate a successful feature release!
Few deployments will need this much rigor. But, when the risk level is high, the control is there; and, almost all of the risk associated with your deployment can be mitigated with a graduated rollout.
Are you beginning to see the possibilities?
So far, for the sake of simplicity, I've been hard-coding the dynamic logic within our featureIsEnabled() function. But, in order to facilitate the graduated rollout outlined above, this encapsulated logic must also be dynamic. This is, perhaps, the most elusive part of the feature flags mental model.
The feature flag evaluation process is powered by a rules engine. You provide inputs, identifying the request context (ex, User ID and User Email). And, the feature flag service then applies its rules to your inputs and returns a variant.
There is nothing random about this process—it's pure, deterministic, and repeatable. The same rules applied to the same inputs will always result in the same variant output. Therefore, when we talk about the dynamic runtime nature of feature flags, it is in fact the rules, within the rules engine, that change dynamically.
Consider the earlier version of our featureIsEnabled() function that ran against the userID:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
switch ( userID ) {
case 1:
case 2:
case 3:
case 4:
return( true );
break;
default:
return( false );
break;
}
}Instead of a switch statement, let's refactor this function to use a rule data structure that reads a bit more like a rule configuration. In this configuration, we're going to define an array of values; and then, check to see if the userID is one of the values contained within that array:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// Our "rule configuration" data structure.
var rule = {
input: "userID",
operator: "IsOneOf",
values: [ 1, 2, 3, 4 ],
variant: true
};
if (
( rule.operator == "IsOneOf" ) &&
rule.values.contains( arguments[ rule.input ] )
) {
return( rule.variant );
}
return( false );
}The outcome here is exactly the same, but the mechanics have changed. We're still taking the userID and we're still looking for it within a set of defined values; but, the static values and the resultant variant have been pulled out of the evaluation logic.
At this point, we can move the rule definition out of the featureIsEnabled() function and into its own function, getRuleDefinition():
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
var rule = getRuleDefinition();
if (
( rule.operator == "IsOneOf" ) &&
rule.values.contains( arguments[ rule.input ] )
) {
return( rule.variant );
}
return( false );
}
public struct function getRuleDefinition() {
return({
input: "userID",
operator: "IsOneOf",
values: [ 1, 2, 3, 4 ],
variant: true
});
}Here, we've completely decoupled the consumption of our feature flag rule from the definition of our feature flag rule. Which means, if we wanted to change the outcome of the featureIsEnabled() call, we wouldn't change the logic in the featureIsEnabled() function. Instead, we'd update the getRuleDefinition() function.
But, everything is still hard-coded. In order to make our feature flag system dynamic, we need to replace the hard-coded data-structure with something to the effect of:
- A database query.
- A Redis
GETcommand. - A reference to a shared in-memory cache (being updated in the background).
Which creates an application architecture like this:
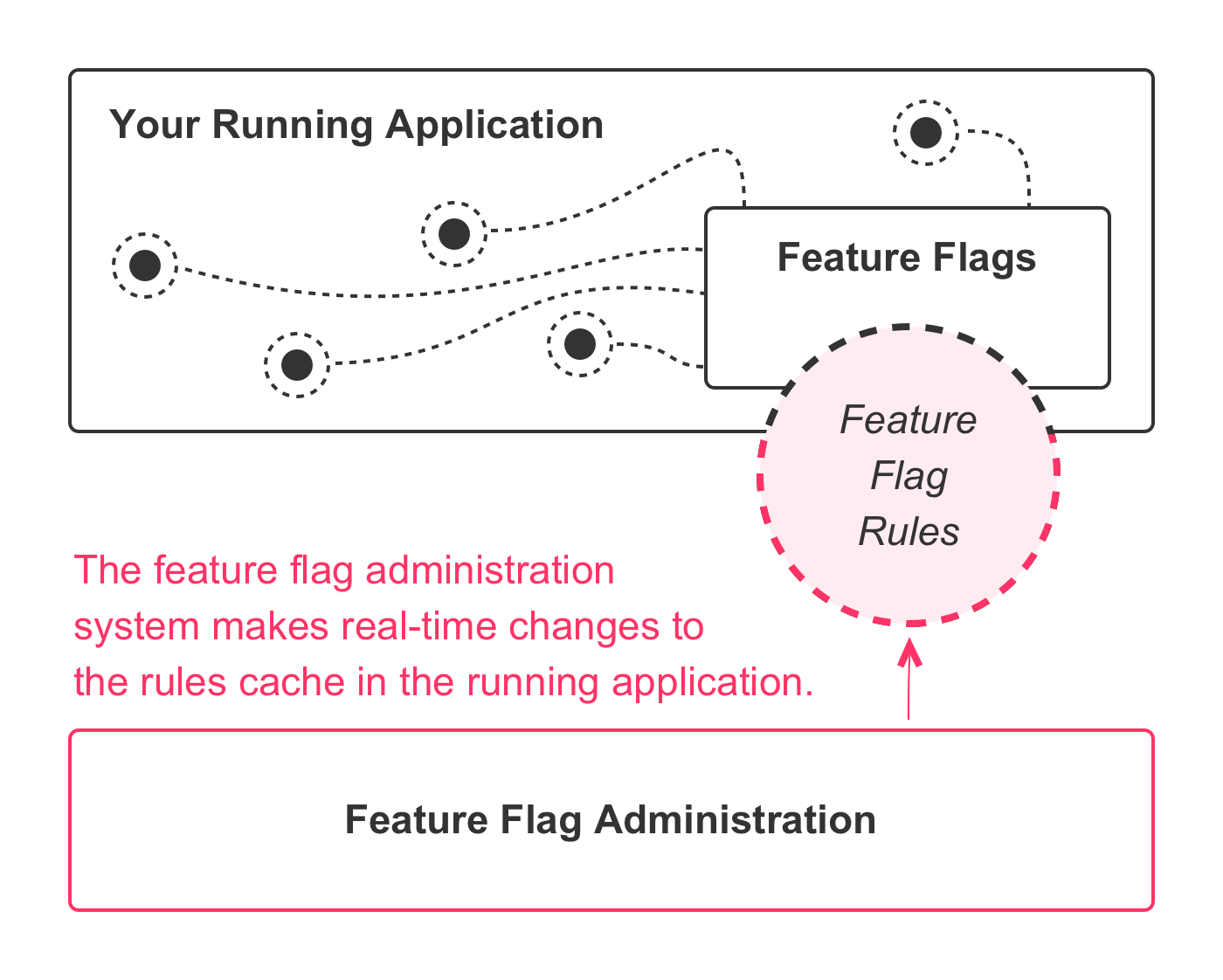
The implementation details will depend on your chosen solution. But, each approach reduces down to the same set of concepts: a feature flag administration system that can update the active rules being used within the feature flag rules engine that is currently operating in a given environment. This is what makes the dynamic runtime behavior possible.
At first blush, it may seem that integrating feature flags into your application logic includes a lot of low-level complexity. But, don't be put-off by this—you don't actually have to know how the rules engine works in order to extract the value. I only step down into the weeds here because having a cursory understanding of the low-level mechanics can make it easier to understand how feature flags fit into your product development ecosystem.
In reality, any feature flags solution that you choose will abstract-away most of the complexity that we've discussed. All of the variants and the user-targeting and the %-based rollout configuration will be moved out of your application and into the feature flags administration, leaving you with relatively simple code that looks like this:
var useNewWorkflow = featureFlags.getVariant(
feature = "new-workflow-optimization",
context = {
userID: request.user.id,
userEmail: request.user.email
}
);
if ( useNewWorkflow ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}This alone will have a meaningful impact on your product stability and uptime. But, it's only the beginning—the knock-on effects of a feature-flag-based development workflow will echo throughout your entire organization. It will transform the way you think about product development; it will transform the way you interact with customers; and, it will transform the very nature of your company culture.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4542
Copyright © 2025 Ben Nadel. All rights reserved. No portion of this book may be reproduced in any form without prior permission from the copyright owner of this book.