You're reading the free online version of this book. If you'd like to support me, please considering purchasing the e-book.
Use Cases
When your feature flags implementation can store JSON variants, it means that there's no meaningful limitation as to what kind of state you can represent. Which means, the use cases for feature flags are somewhat unlimited as well. As we saw in the previous chapter, using Boolean-type flags to progressively build and release a feature is going to be your primary gesture; but, the area of opportunity will continue to expand in step with your experience.
To help jump-start your imagination, I'd like to touch upon some of my use cases. This isn't meant to be an exhaustive list, only a list of techniques with which I have proven, hands-on experience.
Product: Feature Development for the General Audience
Building new features safely and incrementally for your general audience is the bread-and-butter of feature flag use cases. This entails putting a new feature behind a feature flag, building the feature up in the background, and then incrementally rolling it out to all customers within your product. We've already seen this in the previous chapters; so, I won't go into any more detail here.
This type of product feature flag is intended to be removed from the application once the feature has been fully released.
Product: Feature Development for Priority Customers
In an ideal world, new features get used by all customers. But, in the real world, sometimes you have to build a feature that only makes sense for a handful of high-priority customers. At work, we identify these customers as, "T100". These are the top 100 customers in terms of both current revenue and potential expansion.
The T100 cohort may contain specific individuals (such as the "thought leaders" and "influencers" within your industry). But, more typically, the T100 cohort consists of enterprise customers that represent large teams and complex organizations.
To do this, you need to identify a property that allows for an elastic cohort of users. For example, you might use an email address suffix to identify all employees of, "Example, Inc.":
{
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "EndsWith",
input: "userEmail",
values: [ "@example.com" ],
distribution: [ 0, 100 ]
}
}Or, if each organization accesses your product through a unique URL subdomain, you might use this subdomain for your targeting:
{
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "IsOneOf",
input: "companySubdomain",
values: [ "example-inc" ],
distribution: [ 0, 100 ]
}
}In both cases, we're identifying containers not users. Meaning, instead of targeting a specific user email address or a specific user ID, we're targeting the organization that binds a group of users together. This way, as new users enter an organization—and, as old users exit an organization—these targeting rules will continue to identify the correct cohort of users without any additional maintenance.
This type of product feature flag is intended to be removed from the application if the feature is ever fully released (beyond the limited scope of the high-priority customers).
Product: Make-Shift Pay Wall
A feature flag may start out as a way to build a custom feature for a T100 organization. But, if the feature proves to be a significant value-add, you could treat this feature flag as a make-shift pay wall. That is, if other customers are willing to pay for access to said feature, you could honor those payments by adding those customers to the feature flag targeting.
This is an easy way to start experimenting with pay wall opportunities without having to build additional infrastructure or commit to architectural changes. This is especially true in an enterprise context where payments are often fulfilled through Purchase Orders; and, are decoupled from the application code.
In the long run, this approach probably won't scale—keeping two systems in sync (payments and feature flag targeting) is a cumbersome error prone process. But, accepting payments now, without any engineering overhead, should give you the runway you need to build a more permanent solution at some point in the future.
This type of product feature flag is intended to remain in the application while the relevant pay wall exists.
Product: Feature Optimization
As I mentioned in my introduction, the feature flag use case that really clicked for me was that of feature optimization. In my case, I needed to improve SQL query performance. But, "optimization" could refer to any number of product-related measurements: throughput, latency, open rates, conversion rates, bounce rates, error rates, memory usage, CPU usage, garbage collection, etc.
Using a feature flag to incrementally roll-out an optimization is a powerful strategy because we're never 100% sure how the code will perform once it reaches production. We hope that our optimization will improve things. But, sometimes, an optimization—made on faulty assumptions—will end up making matters worse.
Of course, we won't know one way or another unless we have metrics that correspond to each one of our control flow pathways. Depending on what we're optimizing, we may have an existing dashboard that we can use (such as one for CPU utilization); or, we may have to add new metrics ingestion as part of our application logic.
In my earlier look at SQL query optimization, I had code with this general intent (though slightly modified for this example):
var useOptimization = features.getVariant(
"faster-sql",
{
key: request.user.id
}
);
if ( useOptimization ) {
var data = getData_withOptimization();
} else {
var data = getData();
}With feature flag targeting, we can incrementally enable this optimization for our users and cautiously move traffic from the else block (old code) into the if block (new code). But, if we don't measure the relative execution times, the impact of our targeted users will be lost in the noise.
In order for our incremental roll-out to be effective, we need to update our application code to explicitly measure and record the different pathways. In the following version, we're recording the timestamp just before each call; and then, recording the execution delta right after each call.
var useOptimization = features.getVariant(
"faster-sql",
{
key: request.user.id
}
);
if ( useOptimization ) {
var startedAt = now();
var data = getData_withOptimization();
recordExecutionTime( "experiment", startedAt );
} else {
var startedAt = now();
var data = getData();
recordExecutionTime( "control", startedAt );
}Once we have metrics for each execution pathway, we can put those metrics on a graph. And, when we start rolling-out the feature optimization, we'll have incontrovertible evidence that our optimization is working (or, that it isn't working):
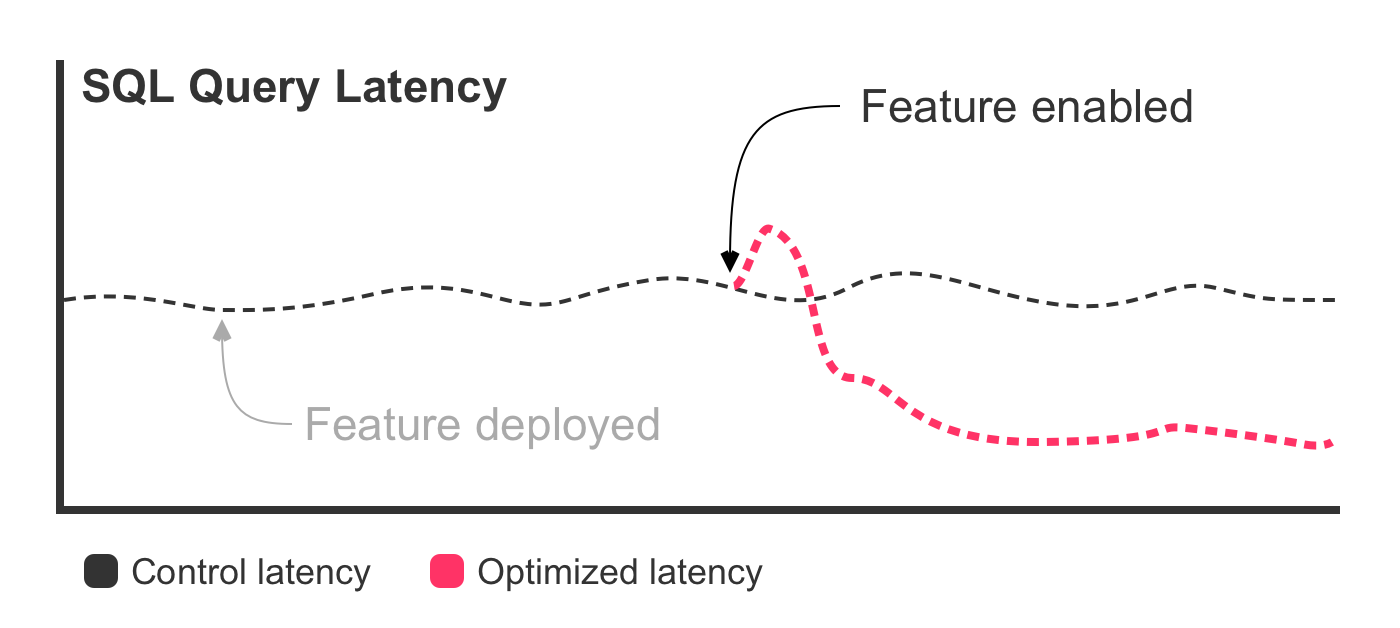
Notice, once again, that the deployment had no effect on the latency. That's because the deployment, in and of itself, didn't actually change the behavior of the application. We only see a change once we start releasing the new SQL query.
With database query optimizations, I like to take things extra slow, perhaps over the course of several hours. And, each time I increase the distribution of the true variant, I go back to this graph and watch the direct impact that my change has on the latency metrics.
Metrics are the driver of feature optimization. If you're using feature flags for optimization, you must put measurements in place.
This type of product feature flag is intended to be removed from the application once the feature optimization has been fully released.
Product: A/B Testing
A/B Testing is really just a form of feature optimization (see above); but, it varies from feature optimization in one critical way: the engineers doing the work are usually not the ones analyzing the outcomes. Instead, the data scientists are crunching the numbers in the background, looking for statistically significant changes in conversion rates. This can result in additional complexities regarding the overall feature flag workflow.
No one thing defines A/B testing; and, differentiating it from feature optimization is somewhat pedantic. But, as a use case, it feels different enough to be worth discussing.
Some of the lowest level A/B testing consists of copy changes. That is, rendering different words, phrases, and colors to see if they have an impact on user actions (such as submitting a form or clicking a button). With feature flags, we have two ways of implementing this test:
- Use the feature flag to define the copy.
- Use the feature flag to drive the control flow.
When using the feature flag to define copy, our feature variants hold the string data that we want rendered in the user-facing page. Consider a feature flag that holds the button text for a sign-up form:
{
"sign-up-button": {
variants: [
"Sign-Up Now!",
"Sign-Up - No credit card required!",
"Sign-Up Free!",
"Get Started Now!"
],
distribution: [ 25, 25, 25, 25 ]
}
}Here, we have four string-based variants getting spread equally among all customers. When rendering the user-facing page, our feature flag state then represents the button text that we render within our View template:
<cfscript>
buttonText = features.getVariant(
"sign-up-button",
{
key: request.client.ipAddress
}
);
</cfscript>
<cfoutput>
<button
type="submit"
name="submitText"
value="#encodeForHtmlAttribute( buttonText )#">
#encodeForHtml( buttonText )#
</button>
</cfoutput>As you can see, the variant returned from the feature flag evaluation is being rendered as the button text in the HTML output. I'm also including the variant as the value attribute on the submit button itself. This way, when the form is submitted, the selected variant value will also be submitted as part of the form data. This allows you to track the chosen variant in your analytics provider on the back-end.
As the data scientists monitor the conversion rates of this sign-up form, they can continue to iterate on the variants defined within the feature flag (both in terms of variant values and variant allocations). Any changes made to the variant values will be propagated automatically to the page rendering, no additional engineering efforts are required.
When using the feature flag to drive the control flow (instead of the copy), we're using the same A/B testing concepts; only, the logic around the variant consumption is deferred to the application layer. This means more work; but, it also means more flexibility.
Instead of putting button text in the feature flag configuration, we can define our variants as button versions:
{
"sign-up-button": {
variants: [
"VersionA",
"VersionB"
],
distribution: [ 50, 50 ]
}
}Then, we can use a switch statement (or any other type of control flow mechanism) to conditionally render HTML in our template based on the evaluated feature flag state:
<cfscript>
buttonVersion = features.getVariant(
"sign-up-button",
{
key: request.client.ipAddress
}
);
</cfscript>
<cfswitch expression="#buttonVersion#">
<cfcase value="VersionA">
<button
type="submit"
name="submitVersion"
value="#encodeForHtmlAttribute( buttonVersion )#">
Sign-Up Now
</button>
</cfcase>
<cfcase value="VersionB">
<button
type="submit"
name="submitVersion"
value="#encodeForHtmlAttribute( buttonVersion )#">
Sign-Up Now - No Credit Card Required!
</button>
</cfcase>
</cfswitch>Clearly, this is more work—we're duplicating more of the HTML. But, it allows us to create a much larger differentiation between the versions. In addition to changing the button copy (as we did in our first approach), we can also change the color, size, shape, and layout of the button. In fact, we can change far more than the button itself—we can swap-out the entire page rendering.
To create such a page-level variation, we can use the feature flag variant on the server-side to determine which View template to render in our response:
signUpVersion = features.getVariant(
"sign-up",
{
key: request.client.ipAddress
}
);
// Render the sign-up form template.
switch ( signUpVersion ) {
case "VersionA":
include "./views/sign-up.cfm";
break;
case "VersionB":
include "./views/sign-up-optimized.cfm";
break;
}We can even alter the overall cross-page workflow by using the feature flag variant to drive post-processing redirects:
// Process the form submissions.
newUserID = createAccount( form.username, form.password );
postSignUpVersion = features.getVariant(
"post-sign-up",
{
key: newUserID
}
);
// Redirect user to the appropriate post-creation page.
switch ( postSignUpVersion ) {
case "profile":
location( url = "./profile-setup.cfm" );
break;
case "team":
location( url = "./team-setup.cfm" );
break;
default:
location( url = "./home.cfm" );
break;
}Since every team is going to have its own way of recording metrics and tracking analytics, I won't bother showing such tracking in these examples. But, as I mentioned earlier, all feature optimization work must be backed by metrics.
This type of product feature flag is intended to be removed from the application once the variants have been evaluated and a top-performing variant has been chosen.
In my experience, it can be difficult to get your data science / analytics / growth teams to ever commit to a single variant. As a product engineer, it is therefore your responsibility to shepherd the A/B testing experiments from end-to-end, bringing them all to a reasonable close using a reasonable timeline.
Product: Labs Program
Most feature flag administration takes place behind a SaaS interface. But, as with all modern SaaS offerings, there's likely an API available for consumption as well. This API allows us to build custom tooling on top of the feature flags management system; which, in turn, allows us to delegate some of that control to our customers.
When building an experimental feature, instead of reaching out to a handful of customers and asking them if they want said feature enabled, we can list out the experimental features within the application UI and allow each user to opt into individual features as they see fit.
This subset of features is often referred to as a "Labs program" or a "Beta program". Not every user is going to be motivated to participate in such a program; but, those that do participate will appreciate the flexibility. And, if you provide some sort of a feedback loop, these early adopters can become a rich source of insight into the usability of the product.
The key to such a program relies on being able to both read from and write to the configuration of a feature flag from within the application context. In all of our previous examples, the application did nothing more than evaluate the rules engine in the context of a request. But, in this approach, our application logic becomes—in a very narrow sense—the administrator of the rules engine.
Typically, this will hinge on a user adding or removing themselves to and from a feature flag values collection, respectively. Let's consider a Dark Mode feature flag in which we use the IsOneOf operator to target users by email address:
{
"dark-mode": {
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "IsOneOf",
input: "userEmail",
values: [],
distribution: [ 0, 100 ]
}
}
}In order for a user to enable dark mode for themselves, they'd have to append their email address to the given values array. Obviously, we don't want users to have full access to the feature flag configuration. So, what we need is an HTML form that presents some sort of enable / disable call-to-action.
Let's assume that we have two methods—.getConfig(name) and .setConfig(name)—that expose programmatic access to a feature flag. The server-side processing of the HTML form submission might look like this:
param name="form.submitted" default=false;
param name="form.darkModeEnabled" default=false;
if ( form.submitted ) {
var email = request.user.email;
var config = features.getConfig( "dark-mode" );
// By default, let's remove the user email from the
// values collection. This prevents us from adding
// the same email twice (and also accounts for the
// opt-out case).
config.rule.values = config.rule.values.filter(
( value ) => {
return( value != email );
}
);
// If the user is OPTING INTO the feature, we have
// to add their email to the values being targeted.
if ( form.darkModeEnabled ) {
config.rule.values.append( email );
}
features.setConfig( "dark-mode", config );
}As you can see, the user is managing their own small slice of the larger feature flags system. And, they're doing so in a secure way: no user-provided data has to be trusted—all critical data is being provided directly by the application control flow.
Note: Replacing the entire
configobject can lead to race conditions between users. The code above is just a simple implementation for the sake of demonstration. Your feature flags API may have a more low-level semantic operation that can be used to manipulate individual targeting values.
Once the user adds their email address to this feature flag configuration, the rest of the application can consume this feature flag just as it would any other feature flag:
enableDarkMode = features.getVariant(
"dark-mode",
{
key: request.user.id,
userEmail: request.user.email
}
);
if ( enableDarkMode ) {
// ... whatever dark mode means in your application ...
}This type of product feature flag is intended to be removed from the application once the feature has been moved out of the labs program and has been fully released.
Product: Administrative Permissions
Internal administrative dashboards should be a first-class citizen of your application. But, they don't provide direct customer value; and, they aren't a differentiating feature for your product. In the early days of finding product-market-fit, you're going to be focusing most of your time on building customer features, not administrative features.
And so, instead of pouring time and effort into building a robust permissions system for your admins, we can use—or, perhaps, abuse—feature flags in order to short-cut some of that cost. Let's look at two different approaches.
In the first approach, we configure a feature flag that assigns an administrative role to the requesting user:
- Admin
- Customer Support
- Sales Associate
These roles will map onto our feature flag's string variants:
{
"admin-ui": {
variants: [ "none", "admin", "support", "sales" ],
distribution: [ 100, 0, 0, 0 ]
}
}So far in our use cases, I've only used feature flag configurations with a single rule. This is fine when we have a simple on/off context. But, now that we're exploring more complex scenarios, we need to swap the rule struct with the rules array such that we can have a series of rules evaluated in turn.
In the case of permissions, each rule looks at a specific role and then targets based on the user's email address. The first rule assigns the "admin" variant; the second rule assigns the "support" variant; and, the third rule assigns the "sales" variant:
{
"admin-ui": {
variants: [ "none", "admin", "support", "sales" ],
distribution: [ 100, 0, 0, 0 ],
rules: [
{
operator: "IsOneOf",
input: "userEmail",
values: [ "ben@bennadel.com" ],
distribution: [ 0, 100, 0, 0 ] // 100% admin.
},
{
operator: "IsOneOf",
input: "userEmail",
values: [ "molly@bennadel.com" ],
distribution: [ 0, 0, 100, 0 ] // 100% support.
},
{
operator: "IsOneOf",
input: "userEmail",
values: [ "sam@bennadel.com" ],
distribution: [ 0, 0, 0, 100 ] // 100% sales.
}
]
}
}Now, when processing a request within the admin subsystem, we can read the state of the admin-ui feature flag before allowing access. The control flow might look like this:
var role = features.getVariant(
"admin-ui",
{
key: request.user.id,
userEmail: request.user.email
}
);
// If the feature flag has not targeted the given user,
// deny access to the administrative dashboard.
if ( role == "none" ) {
throw(
type = "Unauthorized",
message = "User does not have access permissions."
);
}In addition to denying access to any users not targeted by the feature flag, you can also expose individual features within the admin interface based on the role that is returned when checking the feature flag state.
<a>List Users</a>
<cfif ( role == "admin" )>
<a>Manage User</a>
</cfif>In most scenarios, once a feature flag is created, the dynamic nature of the feature flag configuration pertains to its targeting. But, we can also change the variant values. This somewhat cuts against the grain of how feature flags work best; but, having dynamic variants unlocks even more potential.
In our second approach to building a simple permissions model, instead of treating the feature flag like a targeting system, we're going to treat it more like a key-value store.
In the following configuration, we define a single variant—a JSON payload—that maps user emails onto administrative roles:
{
"admin-ui": {
variants: [
{
"ben@bennadel.com": "admin",
"molly@bennadel.com": "support"
"sam@bennadel.com": "sales"
}
],
distribution: [ 100 ]
}
}As you can see, we only have a single variant and a single distribution allocation—100% of all users get the same one variant. This is because we're no longer leaning on the rules within the feature flag to target specific cohorts. Instead, we're leaning on the variant content itself to drive the differentiation.
Which means, instead of using the feature flag to serve the user-role, we're using it to serve an entire user-role dictionary:
var userRoles = features.getVariant(
"admin-ui",
{
key: request.user.id
}
);
// If the key-value store (variant) returned by the
// feature flag does not contain the requesting user's
// email address, the user cannot access the admin.
if ( ! userRoles.keyExists( request.user.email ) ) {
throw(
type = "Unauthorized",
message = "User does not have access permissions."
);
}We've moved the role check out of the feature flag evaluation and into the application logic, demoting the feature flags service from a rules engine to a data store. At this point, if you wanted to add or remove administrative permissions, you'd alter the variant itself, adding or removing a key-value entry, respectively.
Aside: Not all feature flag implementations allow for a single-variant configuration. In such a case, you can always define an empty object as the second variant, and then never serve it to your customers.
This is an uncommon use case for feature flags; and, hand-editing JSON payloads is cumbersome and error prone. But, if you're willing to deal with the friction, this bending of the feature flags paradigm can allow you to bypass a lot of boilerplate code in the early days of your company.
This type of product feature flag is intended to remain in the application until a more robust administrative system is put in place (if ever).
Product: Testing Payments in Production
If you accept payments within your product, your payments vendor almost certainly provides both a production environment and a sandbox environment. The sandbox environment allows you to test payments during development using fake credit cards (typically with different credit card numbers mapping onto different error codes).
This sandbox environment makes it easy to develop payment collection workflows. But, this sandbox environment has its own unique configuration; and, it doesn't actually communicate with a real world bank. Which means, even after a payment workflow is developed and deployed, it still needs to be tested in production using a valid credit card.
Feature flags won't allow us to circumvent this fact; but, they will allow us to minimize the cost. When a payment is collected within an application, the API call made to the payment processor includes the total value to be charged (usually defined as the number of cents). As such, we can use a feature flag to override the monetary value, at runtime, for specific users.
Assuming that all internal developers have an @example.com email address, we can create a feature flag, reduced-payment, that targets these developers:
{
"reduced-payment": {
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "EndsWith",
input: "userEmail",
values: [ "@example.com" ],
distribution: [ 0, 100 ]
}
}
}As you can see, this is going to serve the false variant to everyone by default; and then, serve the true variant to everyone with an @example.com email address. We can then check this feature flag state and override pricing in our payment processing workflow:
var isReducedPrice = features.getVariant(
"reduced-payment",
{
key: request.user.id,
userEmail: request.user.email
}
);
var priceInCents = ( 150 * 100 ); // $150.
// For internal developers, use lowest, non-zero
// price allowed by payments processor.
if ( isReducedPrice ) {
priceInCents = 100; // $1
}
processPayment( priceInCents );Note that the default price is $150. But, when the feature flag evaluates to true—as it will for developers—we're overriding that price to be $1. This is a price that most engineers should feel quite comfortable putting on their own credit card for an occasional test. And, it's a true bargain considering the peace-of-mind provided by a real world test with a real world credit card.
Anecdote: You might wonder why I advocate testing with a personal credit card and not a company credit card. There are two reasons for this:
First, there's bureaucracy. Using a company credit card means getting approval to use a company credit card. Which can take a while and likely means having to articulate what you need it for and how much it will cost ahead of time. A huge value-add of feature flags is being able to move quickly and reduce bureaucracy. You never need to seek approval for your own credit card.
Second, there's fraud detection. If you use a company credit card to pay for services provided by your company, and then subsequently
VOIDthis payment, the credit card company might view this activity as fraudulent. This is not theoretical—it happened to me.At the time, we were using Big Credit Co. (name changed to avoid libel) as our corporate card. And, when testing a payment collection in production, I used our corporate card to make a purchase, checked to make sure everything worked correctly, and then went into the system and voided the payment.
Big Credit Co. immediately suspended our account—the account on which our entire business was being run. And, not only was our account automatically suspended, our company was put into an automatic probationary period which meant that even if we appealed, we still wouldn't be able to activate another Big Credit Co. card for 12 months.
So, no, I never advocate for using a company card to test company-related payment processing.
This type of product feature flag is intended to remain in the application while payments are still part of an in-app workflow.
Product: Easter Egg
I've never actually put an Easter Egg or an April Fool's joke into a product. But, I've always wanted to. And, I think it's worth mentioning as a use case because I believe that feature flags can introduce whimsy in a way that wouldn't otherwise be possible with traditional product development.
A feature flag's dynamic nature provides psychological safety. In the rest of the book, I talk about this psychological safety in terms of building better, more inclusive products. But, this psychological safety can also create a safe space in which to create silly moments of wonder and joy.
This is especially true when all we need to do is inject a temporary <script> tag. Such as one that augments the existing user experience with an April Fool's joke:
<cfscript>
isAprilFools = features.getVariant(
"april-fools-2024",
{
key: request.user.id,
userEmail: request.user.email
}
);
</cfscript>
<cfif isAprilFools>
<script scr="./april-fools/2024.js" async></script>
</cfif>Whimsy doesn't always land well. And, depending on the leap-of-faith that we're taking, we can always limit the exposure of this whimsy to our internal team by using a rule that enables the feature flag for internal users only:
{
"april-fools-2024": {
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "EndsWith",
input: "userEmail",
values: [ "@example.com" ],
distribution: [ 0, 100 ]
}
}
}This type of product feature flag isn't about the product at all—it's about the team. And, about lettings humans be human; and, having fun; and, connecting with each other.
Operations: Maintenance Mode
As much as possible, we'd like to avoid downtime in our applications. But, this isn't always possible. And, sometimes we need to serve a temporary 503 Service Unavailable response while core features are being updated. We can use a feature flag to help with this service interruption.
Consider a feature flag named, OPERATIONS-maintenance:
{
"OPERATIONS-maintenance": {
variants: [ false, true ],
distribution: [ 100, 0 ]
}
}If we check the state of this feature flag very early in the request processing, we can use it to short-circuit the request and render a maintenance page instead of routing the request through the normal pathways of the request-response life-cycle:
var isInMaintenance = features.getVariant(
"OPERATIONS-maintenance",
{
key: request.client.ipAddress
}
);
if ( isInMaintenance ) {
include "/static-views/maintenance.cfm";
// Do NOT render the rest of the request.
abort;
}
// ... Normal request routing ...Now, if we update the feature flag to start serving the true variant for 100% of users, all incoming requests will be met with a maintenance page (which presumably responds with an HTTP status code of 503):
{
"OPERATIONS-maintenance": {
variants: [ false, true ],
distribution: [ 0, 100 ]
}
}Of course, once the disruptive updates are in place, we don't necessarily want to turn the site back on for everyone all at once. Instead, we can add a rule to the feature flag configuration which allows us to enable the "live" site for internal users only. This will give us a chance to vet the updates.
Since the feature flag state is being checked very early in the request processing, we may not yet know who the requesting user is. As such, we can use the IP address as the means of targeting. In the variant evaluation above, I'm already using the IP address as the key (for distribution calculations); so, we might as well use the key as our rule input as well:
{
"OPERATIONS-maintenance": {
variants: [ false, true ],
distribution: [ 0, 100 ],
rule: {
operator: "StartsWith",
input: "key",
values: [ "10." ],
distribution: [ 100, 0 ]
}
}
}Here, we're saying that any IP address that starts with 10. will receive the false variant of the feature flag. Which means, if the user is accessing the site over the local intranet (likely using a VPN), they will see the "live" site even when the rest of the world is continuing to see the maintenance site.
Aside: Certain IP address ranges are reserved for private use and cannot be accessed over the public internet. Addresses that start with
10.and192.168.are two such ranges.
Even after our internal users verify that the disruptive updates were applied properly and the site appears to be operating normally, we still might practice caution when enabling the live site for public users. So, instead of disabling the maintenance mode entirely, we can start to incrementally shift evaluation of the feature flag towards the false variant:
{
"OPERATIONS-maintenance": {
variants: [ false, true ],
distribution: [ 10, 90 ]
}
}Here, the feature flag is still evaluating as true—and the site is still in maintenance mode—for a consistent 90% of requesting users. But, for a consistent 10% of requesting users, the feature flag is now evaluating as false, allowing the live site to be rendered.
If the systems appear to be operating normally, this 10% can be moved to 25%; and then 50%; and so on, until all users are accessing the live site.
This gradual increase in live site traffic gives all of the integrated systems time to warm up: RAM gets allocated, modules get instantiated, caches get populated, elastic services get spun-up. In one sense, you avoid the thundering heard problem. But, in another sense, this approach gives you a window of opportunity in which to monitor the systems and make sure that your updated services can handle the increasing traffic volume before it arrives at full tilt.
A maintenance mode feature flag can also be helpful in cases of emergency. If malicious activity is detected, or someone deploys an update that accidentally exposes sensitive information, having a "kill switch" for the live site can help limit the blast radius of a problem.
This type of operations feature flag is intended to remain in the application while the maintenance mode is being handled at the application level.
Operations: IP-Banning
Similar to a maintenance mode feature flag, an IP-banning feature flag can be helpful in blocking site traffic for a specific set of malicious users. Only, instead of showing a maintenance page, we can just respond with a 403 Forbidden response.
Consider a feature flag named, OPERATIONS-ip-block. This Boolean-based feature flag will evaluate to false by default, allowing the vast majority of traffic to access the live site; but, it will have a rule that evaluates to true for a finite set of malicious IP addresses:
{
"OPERATIONS-ip-block": {
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "IsOneOf",
input: "key",
values: [ "1.2.3.4" ],
distribution: [ 0, 100 ]
}
}
}Since this feature flag is using the IP address for targeting, it can be checked very early in the request processing, allowing us to short-circuit the response before precious resources are consumed (such as databases and upstream APIs) :
var isBanned = features.getVariant(
"OPERATIONS-ip-block",
{
key: request.client.ipAddress
}
);
if ( isBanned ) {
// If banned, render a forbidden response and halt
// all further request processing.
header
statusCode = 403
statusText = "Forbidden"
;
abort;
}
// ... Normal request routing ...Now, as new suspicious IP addresses show up in your logs, you can add them to your rule configuration and immediately block subsequent activity.
This type of operations feature flag is intended to remain in the application while the IP-banning is being handled at the application level.
Operations: Rate-Limiting
With IP-banning (discussed above), finding and recording each malicious IP address becomes a frustratingly reactive process. It's nice to have in a pinch; but, it's a never-ending battle. A better approach is to create a more proactive blocking mechanism. That's where rate-limiting come into play.
Rate-limiting is the throttling of requests through a given access point in your application. It can be performed at multiple levels within a single request; and, is intended to protect an application against bad actors. I always find value in adding some degree of rate-limiting logic in my application's control flow. But, finding the right amount (with the right thresholds) is more art than it is science.
Rate-limiting is generally applied at three different points in the request processing, each of which provides an increasingly specific set of inputs to target:
- High-level: We don't know who the user is yet.
- Mid-level: We know who the user is.
- Low-level: We know which action the user is performing.
As we get lower down in these levels, we know more about who the user is and what they are doing. And, in turn, we can apply stricter rate-limiting controls.
At the high-level, we might only know the user's IP address and host name. However, we don't know if this is a single user operating on a single machine. Or, if this is 1,000 enterprise users all operating behind a single corporate IP address. As such, we have to be rather liberal in what we consider a "reasonable use of the system".
At the mid-level, we've associated the request with a known user. And, at this point, we can apply rate-limiting based on a user-specific identifier, which allows us to get quite a bit more conservative in what we consider a "reasonable use of the system".
At the low-level, we know who the user is and we know which action the user is performing (ex, creating a document, changing permissions, sending an invitation). At this point, we can be extremely aggressive in what we consider a "reasonable use of the system".
Unfortunately, at each one of these levels, there's no obvious measure as to what a "reasonable use of the system" actually is. Which is why threshold identification tends to be an iterative process. Which is also why feature flags are so helpful in this context: they allow us to fine-tune the settings in real-time without having to deploy code.
There are many ways to weave rate-limiting into your application. Generally speaking, you need some sort of fast cache in which to record request-counts in a rolling window. And, you need a way to short-circuit requests when a rate-limit threshold is exceeded. Feature flags are a mere implementation detail within this larger set of requirements.
For the sake of simplicity, I'm going to skip most of the details related to rate-limiting and focus solely on the feature flag touch-points. Let's assume that we have a method:
applyRateLimit( identifier, limit, duration )
This method takes the feature identifier, the maximum limit that is allowed per window of time, and the duration of said window. For example, if we only want to allow 5 accounts to be created per hour per IP address, we might have a call that looks like this in our sign-up form processing:
applyRateLimit( "create-account-#IP#", 5, ONE_HOUR )
Notice that our "feature identifier" is a composite value that contains the feature (create-account) and the request IP address. When rate-limiting, we almost always need a way to identify a context-specific window; otherwise, we end up bucketing all requests into the same window (which will cause our threshold limit to be hit prematurely).
When applyRateLimit() is invoked, this method will test the current window and throw an error as needed, halting the current request processing. Our job—in this exploration—is going to be to supply the appropriate limit using a feature flag evaluation.
Note: It's important to record rate-limit errors either as a metric and/or as a log entry. This way, you can determine when-and-if the limits are being hit. And, how you might need to adjust the limit, or reconfigure the feature flags, in order to better suit real-world access patterns.
At the high-level access-point, we know very little about the incoming request. Our inputs will be limited to those that we can pull out of the request context, such as the IP address and the host name. If possible, we want to avoid database access at this level so that this particular choke-point gives us an opportunity to protect the database (and other external systems) rather than relying on them in order to fulfill the request.
Our high-level control flow might look like this:
var limit = features.getVariant(
"OPERATIONS-request-rate-limit",
{
key: request.client.ipAddress,
host: request.server.host
}
);
var featureID = "request-#request.client.ipAddress#";
applyRateLimit( featureID, limit, MINUTE );As you can see, the feature flag evaluation gives us the rate limiting limit (ie, threshold) that we then supply to the applyRateLimit() method. The configuration for our feature flag should start out as a simple, global limit—we may not need the host input right away:
{
"OPERATIONS-request-rate-limit": {
variants: [ 1000 ],
distribution: [ 100 ]
}
}Here we've configured a global rate-limit that allows for 1,000 requests (per window).
Now, let's imagine that an account representative from "Acme, Inc" reaches out and complains that their users are seeing rate-limiting errors. It turns out, all of Acme, Inc's employees are behind the same corporate IP address; and so, they're quickly exceeding 1,000 calls across all of their users.
At this point, we can either:
- Add the IP address as a rule.
- Add the Acme, Inc host as a rule.
Since we're including the host in our feature flag evaluation inputs, let's use it in our rule as well. Assuming that Acme is accessing our product using the host, acme.example.com, we can update our feature flag configuration to include both a new variant and a new rule:
{
"OPERATIONS-request-rate-limit": {
variants: [ 1000, 5000 ],
distribution: [ 100, 0 ],
rule: {
operator: "StartsWith",
input: "host",
values: [ "acme." ],
distribution: [ 0, 100 ]
}
}
}As you can see, we've added a new variant, 5000. By default none of the requests will receive this variant—they will continue to receive the 1000 variant. However, if the request is accessing the application using the given host, acme.exmaple.com, then the rule distribution will start serving up the 5000 variant, thereby increasing the global rate limit for the Acme, Inc employees.
At the mid-level, once we've associated the incoming request with a given user, we can be stricter with our rate limits. Instead of an IP address—which may represent many users within a single organization—we can use a unique user identifier:
var limit = features.getVariant(
"OPERATIONS-user-rate-limit",
{
key: request.user.id
}
);
var featureID = "user-#request.user.id#";
applyRateLimit( featureID, limit, MINUTE );Note that we are using a different feature flag for the user-level rate-limiting (as opposed to the IP-level rate-limiting). This keeps our configuration simple and flexible:
{
"OPERATIONS-user-rate-limit": {
variants: [ 200 ],
distribution: [ 100 ]
}
}Now, in addition to constraining access to 1,000 requests per minute per IP address at the high-level, we're only allowing 200 requests per minute per user at the mid-level. And, of course, if we have a user that consistently runs into rate-limiting errors, we can always add a rule that allows for an exception case:
{
"OPERATIONS-user-rate-limit": {
variants: [ 200, 500 ],
distribution: [ 100, 0 ],
rule: {
operator: "IsOneOf",
input: "key",
values: [ 1234 ],
distribution: [ 0, 100 ]
}
}
}Here, we've added a new variant, 500, which is only served up to the user with ID 1234.
At the lowest level, we're rate-limiting specific actions not generic requests. As such, we can be extremely strict in what we allow. While we might accept 200 generic requests per minute per user, perhaps we only want to allow a Forgot Password email to be sent twice per hour (in order to prevent spam abuse).
Each low-level rate-limit depends on different inputs and adheres to different window constraints. As such, it's easiest to create a different feature flag for each action. To continue on with the Forgot Password example, our control flow might look like this:
var limit = features.getVariant(
"OPERATIONS-forgot-password-rate-limit",
{
key: request.client.ipAddress,
host: request.server.host
}
);
var featureID = "forgot-password-#request.client.ipAddress#";
applyRateLimit( featureID, limit, HOUR );Notice that our time frame is now HOUR, not MINUTE. And, that we're using a different feature flag—a feature flag with a much lower throughput configuration:
{
"OPERATIONS-forgot-password-rate-limit": {
variants: [ 2 ],
distribution: [ 100 ]
}
}Does 2 requests per HOUR per IP address make sense for a Forgot Password workflow? I have no idea. But, that's the point. There is no magic threshold when it comes to rate-limiting. Every application and every customer is going to be special. And, instead of having to hard-code and deploy loads of exceptions, rate-limiting by way of feature flags gives us a lot of flexibility. Though, even I'll admit that this example comes at the cost of some added complexity.
This type of operations feature flag is intended to remain in the application while rate-limiting is being handled at the application level.
Operations: Log Level Aggregation
Logs are an essential part of application observability. But, not all logs are valuable all the time. When a system is operating normally, we may only want to emit "error" logs. However, when a system becomes unhealthy—especially for unknown reasons—it can be helpful to start emitting lower-level "warn", "info", "debug", and "trace" logs.
To do this, we can create a feature flag that defines the lowest log level to be emitted from the application:
{
"OPERATIONS-log-level": {
variants: [ "error", "warn", "info", "debug", "trace" ],
distribution: [ 100, 0, 0, 0, 0 ]
}
}By default, 100% of all requests will use error as the lowest log level. Meaning, calls to emit warn, info, debug, and trace logs will all be ignored.
Of course, we don't want every part of our application to know about this; so, we'll need to encapsulate our feature flag consumption inside a logging abstraction. This abstraction will compare the feature flag state to the requested log level and then ignore log entries that fall below the given minimum.
Logging libraries are usually complex; so, we're not going to get into too much low-level detail here. But, most libraries do have methods that map to log levels (ex, .error() and .info()). Here's a heavily truncated example of a component that has one such info() method:
component {
public void function info( message, data ) {
if ( shouldEmitLogLevel( "info" ) ) {
emitLog( "info", message, data );
}
}
private boolean function shouldEmitLogLevel( level ) {
// In order to make it easy to compare log levels,
// let's map them onto a numeric scale that gives
// them a hierarchy.
var mapping = {
error: 500,
warn: 400,
info: 300,
debug: 200,
trace: 100
};
var minLevel = features.getVariant(
"OPERATIONS-log-level",
{
key: request.client.ipAddress,
host: request.server.host
}
);
// Only emit logs for a level that is GREATER THAN
// or EQUAL TO the minimum allowable log level.
return( mapping[ level ] >= mapping[ minLevel ] );
}
}As you can see, internally to the .info() method, we're calling the .shouldEmitLogLevel() method; and then, we're only emitting the log entry if info-level logging is enabled.
When the feature flag is configured to use the "error" variant, the return statement inside our shouldEmitLogLevel() method is tantamount to:
return( mapping[ "info" ] >= mapping[ "error" ] )
Which will evaluate as:
return( 300 >= 500 )
Which returns false. Meaning, the info-level log will not be emitted by the application when the feature flag is configured to serve the "error" variant.
But, since our minimum log-level is being controlled by a feature flag, it means that we can dynamically change the evaluation at runtime. For example, we might change all requests to use "info" as the minimum level:
{
"OPERATIONS-log-level": {
variants: [ "error", "warn", "info", "debug", "trace" ],
distribution: [ 0, 0, 100, 0, 0 ]
}
}When the feature flag is configured to use the "info" variant, the return statement inside our shouldEmitLogLevel() method is tantamount to:
return( mapping[ "info" ] >= mapping[ "info" ] )
Which will evaluate as:
return( 300 >= 300 )
Which returns true. Meaning, the info-level log will be emitted by the application when the feature flag is configured to serve the "info" variant.
Or, we might only change it for users accessing the application over an internal IP address (note that in the previous code, our key is the requesting IP address):
{
"OPERATIONS-log-level": {
variants: [ "error", "warn", "info", "debug", "trace" ],
distribution: [ 100, 0, 0, 0, 0 ],
rule: {
operator: "StartsWith",
input: "key",
values: [ "10." ],
distribution: [ 0, 0, 0, 100, 0 ]
}
}
}With this configuration, only the error-level logs are emitted by default. And, debug-level logs (and above) are emitted for internal users.
Feature flag targeting within a logging abstraction is a challenge because logging calls can be made anywhere in the application and at any point within the request processing. Which means, not all relevant targeting information is going to be available all of the time. As such, you may need to code defensively, providing fall-backs for inputs that don't exist.
For example, if the request hasn't been associated with a user, care must be taken if you're including the user identifier in the feature flag evaluation:
var minLevel = features.getVariant(
"OPERATIONS-log-level",
{
key: request.client.ipAddress,
host: request.server.host,
userID: ( request.user?.id ?: 0 ),
userEmail: ( request.user?.email ?: "" )
}
);Notice that we're using both the safe navigation operator (?.) and the Elvis operator (?:) in order to provide the necessary fallbacks when the request.user object has not yet been defined.
We've glossed over a lot of detail in this particular exploration; but, hopefully you can see just how powerful feature flags are. With a simple feature flag evaluation, we're able to dynamically change the runtime behavior of our logging mechanics throughout the entire application, making it much easier to debug production issues without having to deploy code.
This type of operations feature flag is intended to remain in the application forever since the need to emit logs will always exist.
Aside: Many logging libraries allow the minimum level of logging to be defined as an environment variable. While the intention here is honorable, the actual value-add is limited. This is because, in order to change an environment variable, the service has to be re-deployed (or, at the very least, restarted). This is a relatively slow process. And, may cause valuable runtime information to be lost.
Operations: Batch Processing
Eventually, if your application exists long enough, all of your team's naive choices and technical debt come to bear. And the application has to evolve in order to keep up with growing demand. This evolution often includes some sort of large-scale data transformation; such as migrating database records onto a new schema or moving files into a new storage system.
At a certain scale, transformations like this can no longer be performed in a single operation. Instead, a large volume of data must be segmented into smaller batches which are then processed in turn.
The size of each segmented batch is important to consider because an increase in load can easily create negative pressures on a production system:
- Network saturation.
- CPU saturation and throttling.
- File I/O contention.
- Database lock contention.
- Thrashing of working memory.
Instead of spending a lot of time, money, and effort trying to figure out the "right size" ahead of time, we can use a feature flag to dynamically adjust batch sizes at runtime. This way, we can start off small; and, then, slowly increase the batch size while closely monitoring system performance.
Imagine that we need to migrate database records from one table into another. We can create a feature flag that defines how many rows get moved in one operation. In an approach like this, I always have a 0 variant which is an indication to halt all processing:
{
"OPERATIONS-db-migration": {
variants: [ 0, 100 ],
distribution: [ 100, 0 ]
}
}Each application has its own way of running background tasks. For the sake of simplicity, let's assume that we have a workflow which is scheduled to run every 5 minutes. As such, we'll design our algorithm to continue processing batches in a loop while there's still time remaining within the current 5 minute task window.
var cutoffAt = ( getTickCount() + FIVE_MINUTES );
// Continue processing records for 5 minutes.
while ( getTickCount() < cutoffAt ) {
var batchSize = features.getVariant(
"OPERATIONS-db-migration",
{
key: "app"
}
);
// Short-circuit algorithm if "0" variant.
if ( ! batchSize ) {
break;
}
var rowsProcessed = processNextBatch( batchSize );
// Short-circuit algorithm if last batch was empty.
// We have no more data left to process.
if ( ! rowsProcessed ) {
break;
}
}As you can see, we're evaluating the feature flag at the top of each while loop iteration. This allows us to increase the batch-size mid-processing. And, it allows us to halt processing if the system appears to be struggling under the current load.
Aside: All of our previous operations feature flag examples have each targeted a segment of users. Which is why our
keyparameter—in the.getVariants()invocation—has either been a user ID or an IP-address. In this case, we're not really targeting a user since this feature flag is being consumed in a background process. However, sincekeyis a required input (as it is with many feature flag implementations), we're passing in a nonsense static value,"app".
As with all feature flags, this code is deployed in a deactivated state. Then, once the dormant code is in production, we can move from the 0 variant to the non-0 variant:
{
"OPERATIONS-db-migration": {
variants: [ 0, 100 ],
distribution: [ 0, 100 ]
}
}Now, the next time our task runs, it will process 100 records inside each while loop iteration. And, if the system appears to be running smoothly, we can try increasing the batch size to 1,000:
{
"OPERATIONS-db-migration": {
variants: [ 0, 1000 ],
distribution: [ 0, 100 ]
}
}Notice that in this case we're changing the variant value, not the variant distribution. This is not the most common consumption model for feature flags; but, as you can see with this use case (and with some of the previous examples), this can be a very effective way to apply feature flags.
As the batch processing runs, we continue to monitor the system both by checking the database performance directly and by checking any other services that are connecting to the database. And, if the system looks good, we can try increasing the batch size to 10,000:
{
"OPERATIONS-db-migration": {
variants: [ 0, 10000 ],
distribution: [ 0, 100 ]
}
}At this point, it becomes a balancing act between system performance, database performance, and safety. With an algorithm like this, the goal isn't simply to maximize the batch size—it's to find the "right" batch size. Which, may not be the same thing.
By making fewer calls to the database, using a larger batch size, we might increase the overall throughput. However, as the batch size increases, our opportunities to short-circuit the algorithm decrease (based on our while loop control flow). Which means, if the system were to start struggling under a very large batch size, we may not have an opportunity to disable the feature before the system becomes unresponsive. As such, a smaller batch size might be the "right" batch size, depending on the level of risk to the system.
This type of operations feature flag is intended to remain in the application until the batch processing is complete.
Are You Beginning to See the Possibilities?
This was not meant to be an exhaustive exploration of feature flags. These are simply the ways in which I have used feature flags in my own work. And, I'm sure that I'll continue to come up with even more ways in which to leverage feature flags in the future.
My hope here is that by sharing a few concrete examples, you'll start your feature flag journey with an inspired perspective. But, keep in mind that feature flag use-cases are only half the story—the transformation of your company cultural is yet to come.
Algorithm Caveats
Depending on your feature flags implementation, some of the use cases above may become more or less viable. For example, using a feature flag to change the batch size in the middle of a request is only possible if the lag time between a configuration change and the subsequent runtime change is near zero.
If the lag time is non-trivial, or if feature flags are read from an intermediary cache, we may not be able to respond immediately when we see a problem in production. We can still use the same techniques; but, we likely have to be much less aggressive in our roll-out. This way—with a slower roll-out—we'll have increased time to respond to early warning signs with the understanding that the production system may have to muscle through any degraded performance until the feature flag configuration changes are synchronized to the runtime.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4548
Copyright © 2025 Ben Nadel. All rights reserved. No portion of this book may be reproduced in any form without prior permission from the copyright owner of this book.