
Parallel Iteration vs. Chunked Parallel Iteration In Lucee CFML
One of the most exciting features in ColdFusion is the ability to iterate over collections using parallel threads. When consuming large amounts of data, parallel threads can have a dramatic impact on performance. But, spawning threads isn't free—and, in some cases, spawning threads is even more expensive than you realize. Because of this cost, one thing that I've always wanted to test is the performance of straight parallel iteration compared chunked parallel iteration in Lucee CFML.
Update on 2024-05-30
I had a fatal flaw in the code that was skewing the results. In my original target.cfm, I was param'ing the url.i value to be numeric. This was actually throwing an error in the test-2.cfm scenario; but, because I wasn't validating the fileRead() results, I didn't see the error until I start dump()'ing out more data and could see the error in the fileContent.
This error was causing many of the requests to fail before the sleep(25) command. Which allowed them to execute extremely fast in the test-2 scenario. Which threw off the overall results in a massive way.
I have updated the article to be more accurate; and, I've added some additional testing for a clearer picture.
Consider an array that has 100 elements in it. If we use ColdFusion's parallel iteration to iterate over this array using a maximum of 10 threads, ColdFUsion will still spawn 100 threads; but, only allow 10 of them to exist at the same time.
Now, consider taking that same array and first splitting into 10 chunks of 10 elements. If we use ColdFusion's parallel iteration to iterate over the chunks using a maximum of 10 threads, ColdFusion will only end up spawning 10 threads. But, within each thread, we'll have to use synchronous, blocking iteration to process each element.
So the question is, which is faster: spawning 100 threads and performing all work asynchronously? Or, spawning 10 threads and performing a lot of the work synchronously (in parallel chunks)?
I'm sure that this question is actually quite a bit more complicated than I realize. And, I'm sure that there's a lot of "it depends" that one might apply to real-world implications of a test like this. But, I just want to get a general "ball park" sense of how these two approaches compare. Take my results as nothing more than an anecdote.
To test this, I created a small CFML page (target.cfm) that sleeps for 25 milliseconds and then returns a parameterized text value:
<cfscript>
param name="url.i" type="string";
sleep( 25 );
cfcontent(
type = "text/plain; charset=utf-8",
variable = charsetDecode( "World #i#", "utf-8" )
);
</cfscript>
This page will be consumed via an HTTP request using ColdFusion's virtual file system (VFS) behavior. That is, I'll be using the built-in fileRead() function to access this file using a path with an http:// scheme:
http://#cgi.http_host#/parallel-strategy/target.cfm
In my first test, I'm going to make 10,000 requests to this target.cfm page using 10 parallel threads:
<cfscript>
include "./utilities.cfm";
values = generateValues( "Hello", 10000 );
stopwatch variable = "durationMs" {
// In Test-1, we're going to use parallel iteration to loop over the entire values
// collection. This will cause Lucee CFML to spawn a thread for each element in
// the array.
results = values.map(
( value, i ) => {
return fileRead( "#targetUrl#?i=#i#" ); // HTTP (sleep 25).
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = results, top = 10 );
</cfscript>
This test generally completed in around 80 seconds.
In my second test, I'm also making 10,000 requests to target.cfm; however, this time, I'll first split the array into 10 chunks, each with 1,000 element. Then, I'll use 10 parallel threads—one per chunk—in which I make 1,000 synchronous HTTP requests inside each thread context:
<cfscript>
include "./utilities.cfm";
values = generateValues( "Hello", 10000 );
stopwatch variable = "durationMs" {
// In Test-2, we're going to first split the values array into chunks. Then, we'll
// use parallel iteration to loop over the chunks; but, we'll use synchronous,
// blocking iteration to loop over the values within each chunk. This will reduce
// the number of threads that Lucee CFML has to spawn.
// --
// Note: I'm using a chunk-size that results in a number of chunks that matches
// the max-thread configuration in the parallel iteration.
results = splitIntoChunks( values, 1000 ).map(
( chunk, c ) => {
// Synchronous iteration / mapping all within the current thread.
return chunk.map(
( value, i ) => {
return fileRead( "#targetUrl#?i=#c#:#i#" ); // HTTP (sleep 25).
}
);
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Chunked Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = results, top = 10 );
</cfscript>
This test generally completed in around 80 seconds.
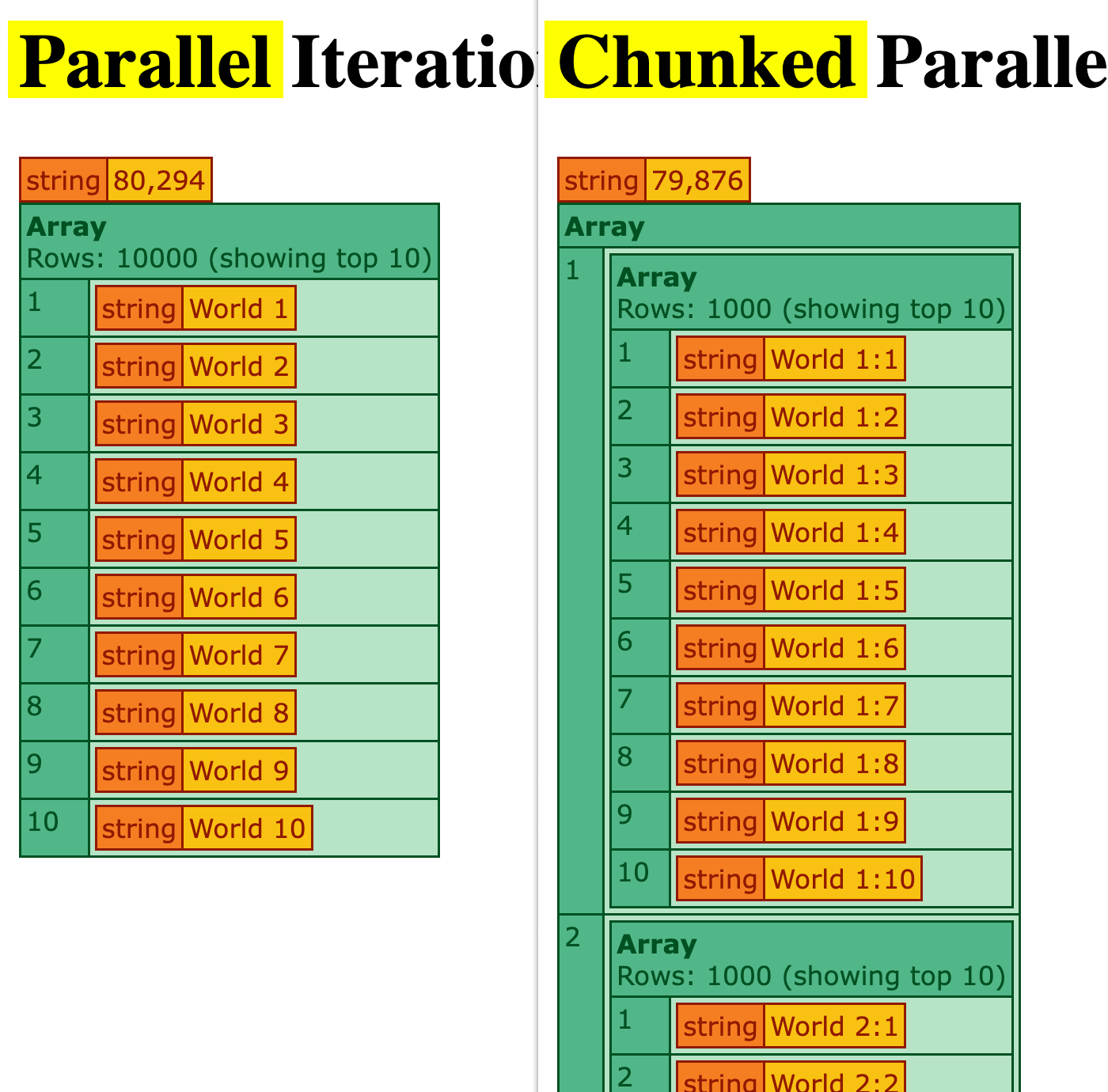
In this particular context, there's no meaningful difference between the two approaches—the chunked parallel iteration and the plain parallel iteration both completed in almost exactly the same time.
Removing the sleep(25) Bottleneck
In the above test, I wonder if the cost of the sleep(25) statement in the target.cfm page is much larger than the cost of spawning a new thread. Which could mean that the cost of the underlying HTTP request drowns-out any perceivable difference between the two tests.
Let's try this again; but, this time, remove the sleep() command on the target page. The underlying HTTP request will still add overhead; but, it will be much smaller now.
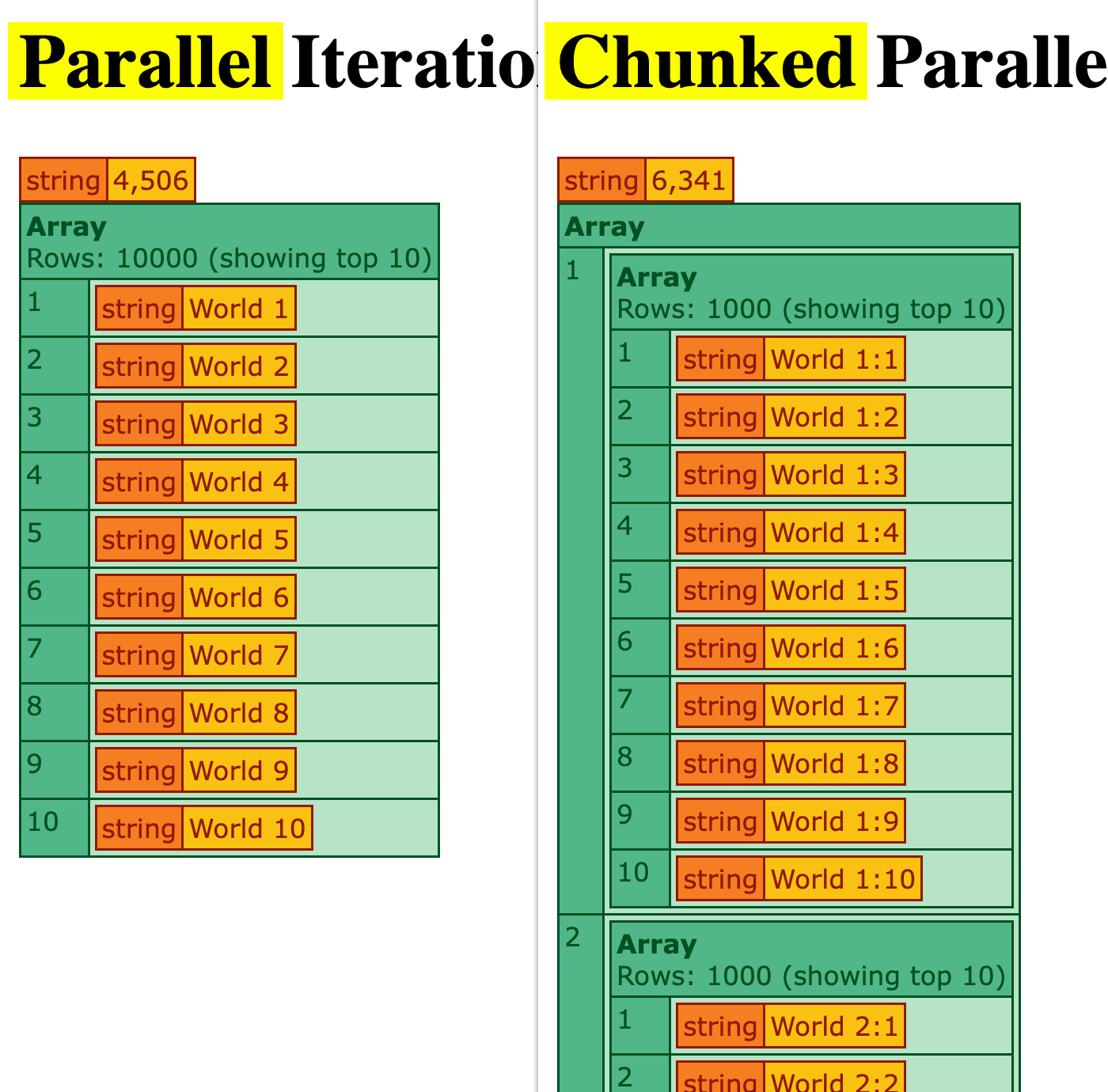
Without the sleep(25) statement, the plain parallel iteration now completes in about 4.5 seconds and the chunked parallel iteration now completes in about 6 seconds. I have to admit, I'm kind of shocked by this—that the plain parallel iteration is faster. I would have assumed that as the cost of the HTTP request came down, the relative expense of spawning new threads would have become more meaningful.
Aside: I'm testing this in Lucee CFML 6.0.1.83 - I wonder if Lucee 6 made any significant changes to the way in which it spawns threads? Perhaps a lot of the overhead was improved since v5.
As a final test, I wanted to see if the chunk size would have any impact on the performance. So, I played around with a few different values (running a few iterations at each value):
- 10 (1,000 chunks) → 4.2 - 5.7 seconds.
- 50 (200 chunks) → 3.7 - 5.5 seconds.
- 100 (100 chunks) → 2.8 - 5.8 seconds.
- 200 (50 chunks) → 3.7 - 6.5 seconds.
The results were all over the place - no clear difference between chunk size.
Removing the HTTP Request
I'm wondering now if the cost of the HTTP request is still so large, relatively speaking, that it drowns-out the cost of spawning threads. As such, let's try a new test in which we remove the HTTP request entirely.
Here's the revamped first ColdFusion file:
<cfscript>
include "./utilities.cfm";
values = generateValues( "Hello", 10000 );
stopwatch variable = "durationMs" {
// In Test-1, we're going to use parallel iteration to loop over the entire values
// collection. This will cause Lucee CFML to spawn a thread for each element in
// the array.
results = values.map(
( value, i ) => {
return "World #i#"; // No more HTTP request!
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = results, top = 10 );
</cfscript>
This test generally completed in around 175 milliseconds.
Here's the revamped ColdFusion code with the chunked iteration:
<cfscript>
include "./utilities.cfm";
values = generateValues( "Hello", 10000 );
stopwatch variable = "durationMs" {
// In Test-2, we're going to first split the values array into chunks. Then, we'll
// use parallel iteration to loop over the chunks; but, we'll use synchronous,
// blocking iteration to loop over the values within each chunk. This will reduce
// the number of threads that Lucee CFML has to spawn.
// --
// Note: I'm using a chunk-size that results in a number of chunks that matches
// the max-thread configuration in the parallel iteration.
results = splitIntoChunks( values, 1000 ).map(
( chunk, c ) => {
// Synchronous iteration / mapping all within the current thread.
return chunk.map(
( value, i ) => {
return "World #c#:#i#"; // No more HTTP request!
}
);
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Chunked Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = results, top = 10 );
</cfscript>
This test generally completed in around 25 milliseconds. That's about 7 times faster than the plain parallel iteration.
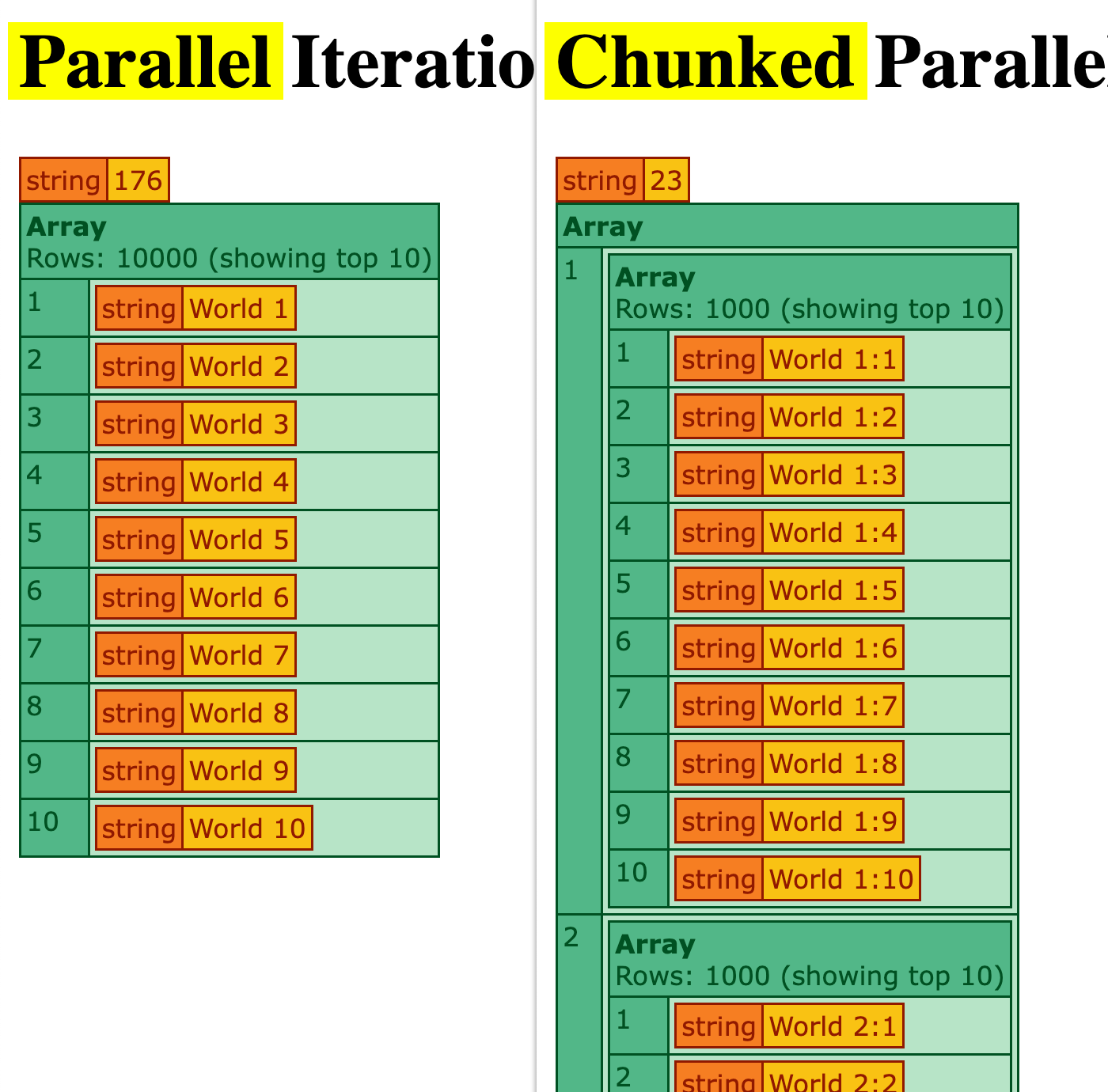
Now that the relative cost of each iteration is next-to-nothing, the cost of spawning new threads can be seen more clearly.
Performance Take-Away
What I think we can see here from the various tests is that spawning new threads in Lucee CFML does incur a cost. But, that cost is relatively small. Which means, the moment the cost of each iteration outweighs the cost of spawning threads, plain iteration vs. chunked iteration makes no meaningful difference.
In the end, the calculation that one needs to make in their ColdFusion code isn't plain iteration vs. chunked iteration but rather synchronous iteration vs. asynchronous iteration. And, it seems that the moment asynchronous iteration is an improvement, chunking the iteration makes no difference.
For completeness, here's the code for the utilities.cfm CFML template that I was including at the top of each test:
<cfscript>
setting
requestTimeout = ( 5 * 60 )
;
targetUrl = "http://#cgi.http_host#/parallel-strategy/target.cfm";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I generate an array of the given size.
*/
public array function generateValues(
required string value,
required string count
) {
var values = [].set( 1, count, value );
return values;
}
/**
* I split the given array into chunks of a maximum size.
*/
public array function splitIntoChunks(
required array values,
required numeric maxSize
) {
var chunks = [];
var chunk = [];
var chunkSize = 0;
for ( var value in values ) {
chunk.append( value );
if ( ++chunkSize >= maxSize ) {
chunks.append( chunk );
chunk = [];
chunkSize = 0;
}
}
if ( chunkSize ) {
chunks.append( chunk );
}
return chunks;
}
</cfscript>
Also, why doesn't CFML have a flatMap() function?! I'd love to see ColdFusion just bulk-up the number of methods available in the standard library.
Want to use code from this post? Check out the license.
Reader Comments
Your splitIntoChunks function actually gives you 1000 rows of 10, not 10 rows of 1000.
A slight modification gets you what I think you were looking for:
Note the addition of
elementsPerChunk@Denard,
D'oh, you're totally right! You can even see it in the screenshot (showing
Rows: 1000). Let me fix the method call to pass-in1000and not10, and I'll see what happens to the results.@Denard,
Oh man, I'm so glad you made me stop and think about this post because it turns out there was a huge problem in my logic. I originally had the
cfparamtag forcing the target value to be numeric, which was actually causing an error in many of the requests. Since this error was being swallowed in the underlyinghttprequest, I didn't see it until I started dumping-out more data.And, once I fixed the underlying error, it turns out there's no meaningful difference at all in between the two approach. At least, not while the cost of each iteration is high relative to the cost of spawning threads.
The only difference starts to appear when you reduce the cost of each iteration to, essentially, nothing. Then, the cost of spawning threads can finally be seen.
Anyway, I've revamped the blog post and added some additional tests. Thank you so much for helping me figure this out 🙌 I know it was not your intention, but you were the trigger for a better investigation!
Happy to help in some small, indirect way lol and glad it lead to more investigation that altered the conclusions.
I actually started playing with chunked parallelism in some of my code and came to the same conclusion you did - there doesn't seem to be much of a performance gain unless finely tuned for the task at hand.
One thing I haven't tried (yet) is what happens if you run parallel for both the inner and outer map() - not sure there's much performance benefit to be gained doing that, and the risks of doing it wrong (using too many threads, not being thread safe in the inner map(), etc.) probably outweigh any benefit... but my mind doth still wonder lol
That said... the chunking algorithm is something I've used plenty in the past to break large datasets into smaller, bite sized chunks for processing through multiple requests (e.g. a scheduled task that chunks on first pass and iterates chunks on each additional pass) and is genuinely just a cool function to have in the toolbelt when its needed.
Thanks, as always, for keeping my brain lubricated with your posts!
@Denard,
I've run into some strange edge-cases when trying to process large amounts of data. For example, let's say that I pull 100,000 rows back from a database and I need to transform each of them in some way (and write data back to the database).
If I try to just run them all in parallel and lean on the CFML engine to queue them up in the background:
... I find that the CPU gets cranked way up and this runs really slowly. I think the CFML engine has trouble managing the threads across so many rows?
But, if I do the same thing but split the rows up into chunks and then process each chunk in parallel:
This seems to run much faster and the CPU stays under control. In the end, it still spawns 100,000 threads to process 100,000 rows. But, the CFML engine seems to be much better about managing threads across an isolated 1,000 entries, and then repeating that 100 times.
I don't pretend to know how these two approaches are substantively different. But, they seem to have different performance profiles. Though, I have no evidence to show -- this is just from at-work experience. Perhaps this is something I should try to demonstrate.
Hmmm... I have some understanding of ParallelStreams in Java, but not enough to suggest a concrete reason for the performance discrepancy.
I suspect it becomes a matter of memory management when trying to process large datasets that is the underlying cause of the CPU spikes. Keeping 100,000 rows, plus all the pointers, in memory and then operating on that data... might that lead to things like page swapping in the underlying OS? And might multiple threads increase the likelihood that page swapping can become contentious (e.g. keeping the CPU core busy 'waiting' for a swap to its page)? 🤔
Perhaps by chunking the dataset into bite sized pieces the memory consumption is better controlled and threads die quicker so GC can reclaim memory faster?
I should have partied less and paid attention more in my CS courses, I guess. :grumbles something about hindsight: 🤣
@Denard,
Yeah, it's a strange one. Especially because I pull all the rows (100,000) into memory regardless of the approach. The only difference is how many of those rows need to be managed by any given parallel iteration.
But, I really have to see if I can demonstrate this in a blog post, so that I can confirm that I'm not just making this all up :)
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →