
Conditionally Updating Columns When Using ON DUPLICATE KEY UPDATE In MySQL
A couple of weeks ago, I talked about the lessons I learned while sending 7M emails using ColdFusion. In that post, I mentioned that I needed to store a cache of email validation codes in order to avoid sending an email to any address that was known to be invalid. But, an invalid email address isn't the only reason to skip a given send. If a user explicitly unsubscribes from a broadcast stream, I need to omit the given user in the next send (or my SMTP provider—Postmark—will mark the email as bounced).
When a user explicitly unsubscribes from the broadcast stream, I update their email validation record to store the value, suppressed. But, of course, their email address is technically valid. Which means, if we ever run their email through the validation process again (such as via NeverBounce or Email List Verify), it may come back as ok or valid.
In order to treat the suppressed assignment as a one-way door, I needed to make sure that once an email validation was marked suppressed, it will never be marked as anything else. To do this, I had to update my SQL statement to conditionally store the new value if and only if the current value was not suppressed.
To explore this logic, let's first look at the database table structure:
| CREATE TABLE `email_verification` ( | |
| `email` varchar(255) NOT NULL, | |
| `textCode` varchar(50) NOT NULL, | |
| `updatedAt` datetime NOT NULL, | |
| PRIMARY KEY (`email`) | |
| ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; |
Here, we're using the email as the primary key and the textCode as the email verification value. Populating this table was going to be an iterative process; and, the verification codes were going to change over time. As such, my INSERT needed to handle updates on email duplication (ie, on primary key collision).
The SQL for such a multi-pass INSERT looks like this:
| SET @email = 'ben@bennadel.com'; | |
| SET @textCode = 'ok'; | |
| INSERT INTO | |
| email_verification | |
| SET | |
| email = @email, | |
| textCode = @textCode, | |
| updatedAt = UTC_TIMESTAMP() | |
| ON DUPLICATE KEY UPDATE | |
| textCode = VALUES( textCode ), | |
| updatedAt = VALUES( updatedAt ) | |
| ; |
In this SQL statement, I'm using the ON DUPLICATE KEY UPDATE clause in order to update any existing row with a matching email address (which, remember, is being used as the primary key). In the context of the ON DUPLICATE KEY UPDATE clause, the VALUES() function returns the value that would have been used within the INSERT had there been no key-collision.
With this SQL, I can run the INSERT...ON DUPLICATE KEY UPDATE as many times as I like; and the textCode column will keep getting updated for the given email address:
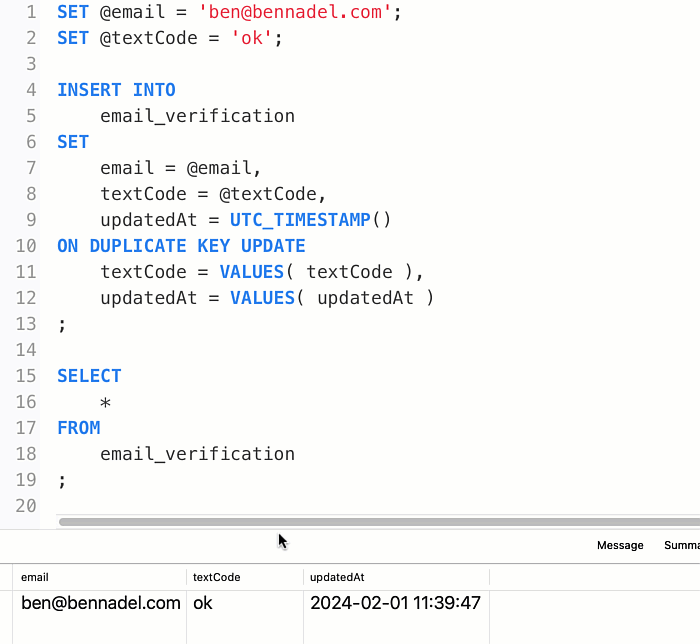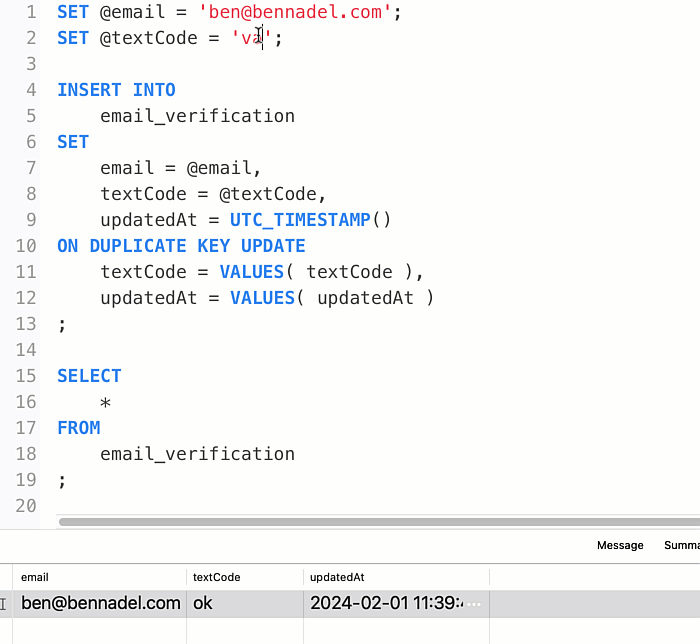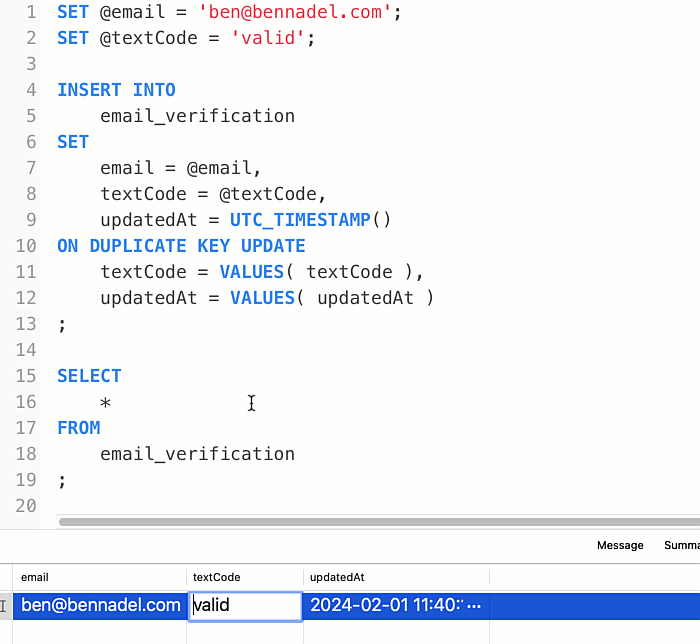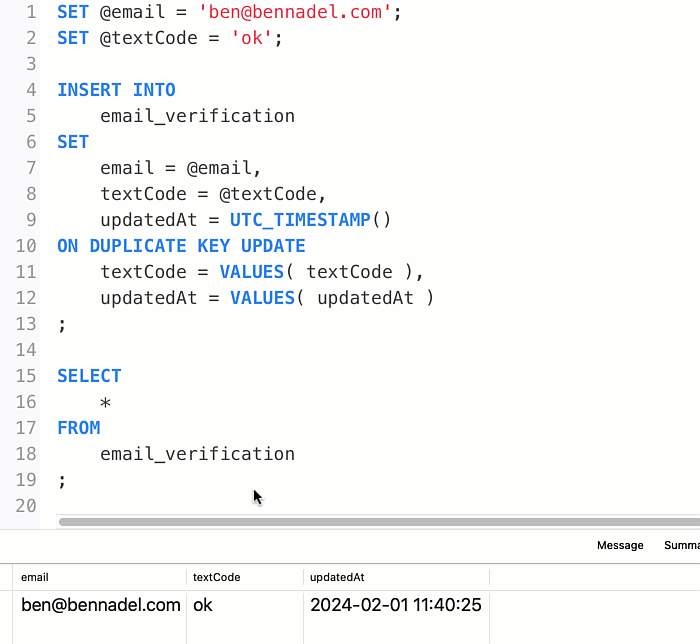
Of course, once the textCode column is designated as suppressed, I never want it to change. In order to do this, my UPDATE assignment has to look at the existing value and conditionally override it. Thankfully, the UPDATE clause can reference any existing column value within the existing row by name. Which means, I can use the IF() function to return the existing value if it is currently suppressed; or, to return the VALUES() value if it is anything else.
| SET @email = 'ben@bennadel.com'; | |
| SET @textCode = 'ok'; | |
| INSERT INTO | |
| email_verification | |
| SET | |
| email = @email, | |
| textCode = @textCode, | |
| updatedAt = UTC_TIMESTAMP() | |
| ON DUPLICATE KEY UPDATE | |
| textCode = IF( | |
| ( textCode = 'suppressed' ), | |
| textCode, -- Return the existing value (suppressed) | |
| VALUES( textCode ) -- Return the new value. | |
| ), | |
| updatedAt = VALUES( updatedAt ) | |
| ; |
To be clear, within the ON DUPLICATE KEY UPDATE clause, the expression textCode refers to the existing value within the existing row. But, the expression VALUES(textCode) refers to the new value that would have been inserted. And, once the textCode column is set to suppressed, it can never go back to anything else:
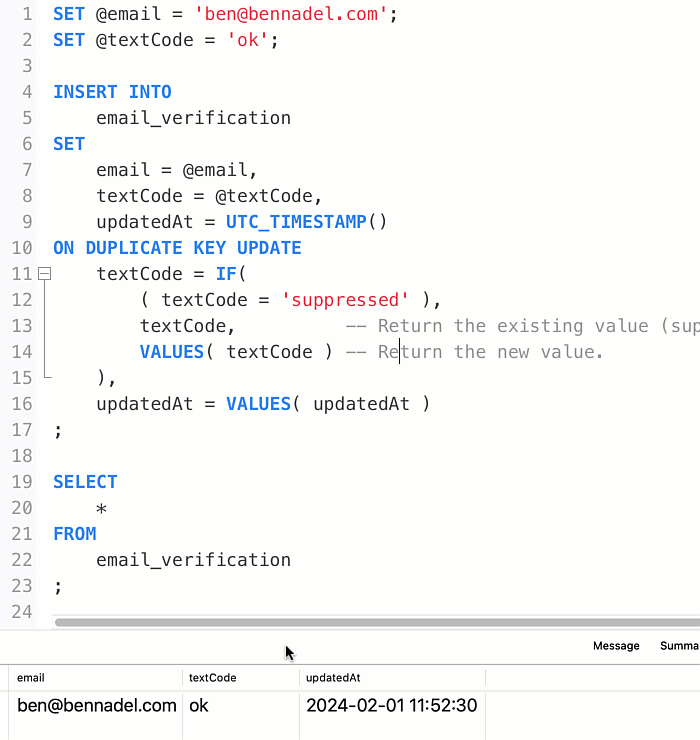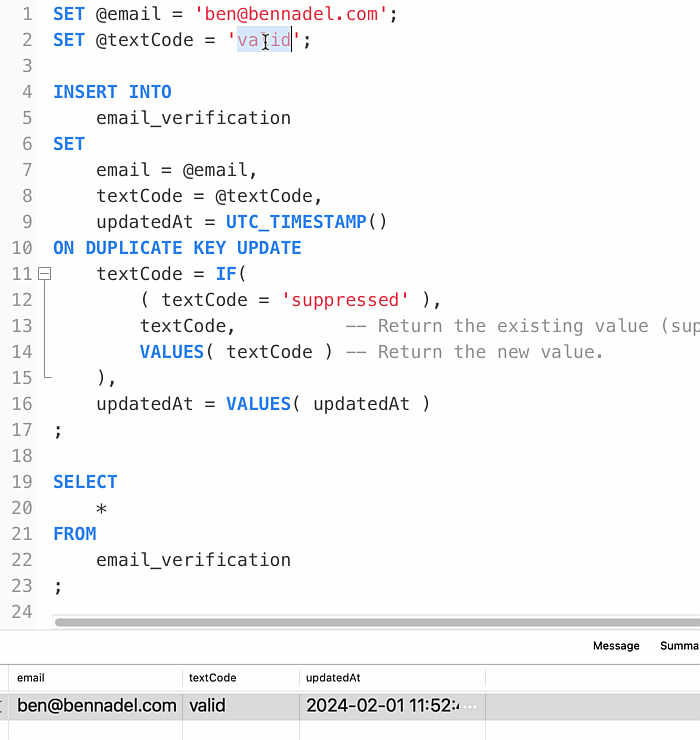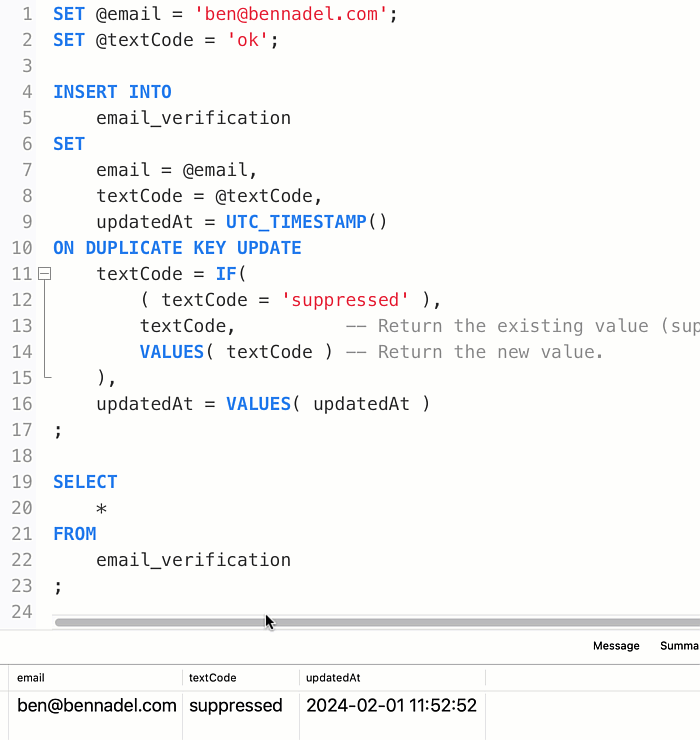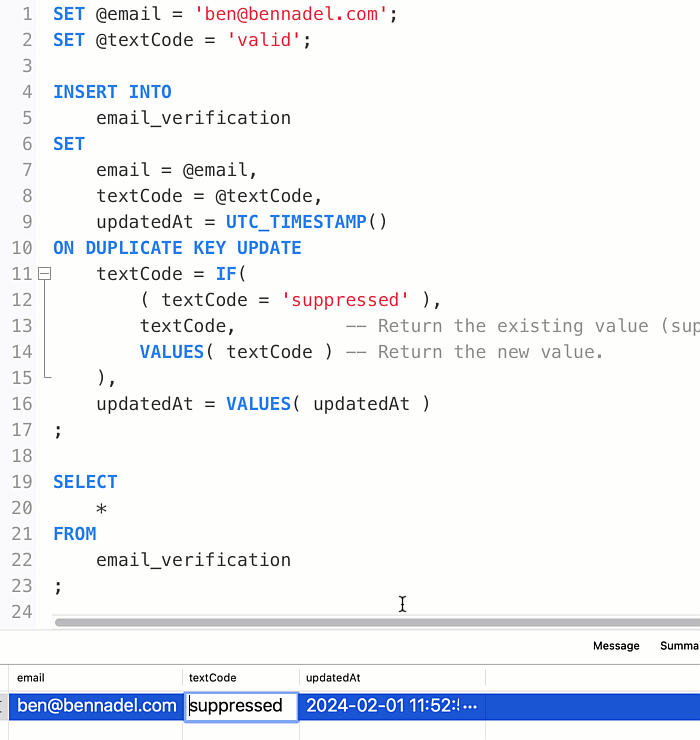
By using the IF() function within the ON DUPLICATE KEY UPDATE clause, I can ensure that once the textCode column is "suppressed", any subsequent execution of this query will become a no-op. That said, I'm electing to always update the updatedAt column on every execution as a means to provide internal feedback to our team.
I could have broken this whole algorithm up into two separate SQL queries: a SELECT query followed by a conditional INSERT or UPDATE query. However, this bit of workflow operates over millions of email address. And, if I can cut the number of SQL queries in half (from 2 to 1), this has a very meaningful impact on how fast the overall workflow can execute.
Want to use code from this post? Check out the license.
Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →