
Performance Of Struct vs. Ordered Struct In ColdFusion
Yesterday, in the Working Code podcast Discord, Sean Corfield and I were discussing the trade-offs of various data structures. The conversation started from a code-comment that I had made about using an ordered struct. To which, Sean mentioned that ordered structs were slower than regular structs due to the fact that they have to maintain insertion order in addition to the key-value pairs. This has never occurred to me before; especially since the size of my standard data structure makes any difference inconsequential. But, I thought it would be an interesting things to test more explicitly in ColdFusion.
To test this, I created a script that populates a struct, iterates over all the keys, and then deletes all the entries. Each execution of the script runs this test a number of times for both an ordered struct and regular struct. I record the execution time of each phase; and then, output the average of all the execution times.
Each iteration computes a struct key by combining a character prefix and a number suffix, ex: a10, _43, and M100. At the start of each experiment, the order of the prefix characters is shuffled since I figured it might have an impact on the performance.
The duration of the test can be tweaked in two different ways: number of iterations and number of struct keys. I've opted for a larger key-space over the number of iterations as I figure the performance is going to degrade more with key-space size.
Case-insensitive keys: As you'll see in the code below, I'm using both lower-case and upper-case letter ranges (
a..zandA..Z). Of course, structs in ColdFusion are case-insensitive by default. As such, I am going to have key-collisions (ex,a30andA30). At first, I felt like this was a mistake in the experiment design; but then, on reconsideration, I thought maybe this is a real-world aspect to the test.
I'm going to run this in both the latest Lucee CFML (6) and Adobe ColdFusion (2023):
<cfscript>
cfsetting( requestTimeout = 300 );
// We're going to iterate over these tests, and perform high(ish) volume operations
// ( write / read / delete ) on the two types of Structs (normal, ordered). Each
// iteration will record a run-time; then, the average of the run-times will computed
// at the end.
tests = [
{
target: {}, // NORMAL struct.
readings: {
write: [],
read: [],
delete: []
}
},
{
target: [:], // ORDERED struct.
readings: {
write: [],
read: [],
delete: []
}
}
];
pageStartedAt = getTickCount();
letters = shuffleChars( "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_" );
// This is the number of times each struct will be populated, read, and then reset.
totalIterations = 50;
// This is the number of keys that will be inserted PER LETTER.
totalSubIterations = 10000;
for ( test in tests ) {
// In each iteration, the struct will be fully populated and then fully cleared.
for ( iteration = 0 ; iteration <= totalIterations ; iteration++ ) {
// Phase: WRITE ----- //
startedAt = getTickCount();
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
test.target[ "#c##i#" ] = false;
}
}
test.readings.write.append( getTickCount() - startedAt );
// Phase: READ ----- //
startedAt = getTickCount();
temp = false;
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
// All the struct values are FALSE, so this always evaluates the
// right-hand operand.
temp = ( temp || test.target[ "#c##i#" ] );
}
}
test.readings.read.append( getTickCount() - startedAt );
// Phase: DELETE ----- //
startedAt = getTickCount();
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
test.target.delete( "#c##i#" );
}
}
test.readings.delete.append( getTickCount() - startedAt );
} // END: Iterations.
// Overwrite the full set of run-times with an average.
test.readings.write = fix( test.readings.write.avg() );
test.readings.read = fix( test.readings.read.avg() );
test.readings.delete = fix( test.readings.delete.avg() );
} // END: Tests.
writeDump( tests );
writeOutput( "<br />" );
writeOutput( "Total Test Time: #numberFormat( getTickCount() - pageStartedAt )#" );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I split the given input into an array and randomly shuffle it.
*/
public array function shuffleChars( required string input ) {
var chars = input.listToArray( "" );
createObject( "java", "java.util.Collections" )
.shuffle( chars )
;
return( chars );
}
</cfscript>
When I ran this, the results surprised me. In Lucee CFML, the ordered struct is consistently faster than the regular struct on all operations (read, write, delete)! And, in Adobe ColdFusion, both types of structs operated at roughly the same speed.
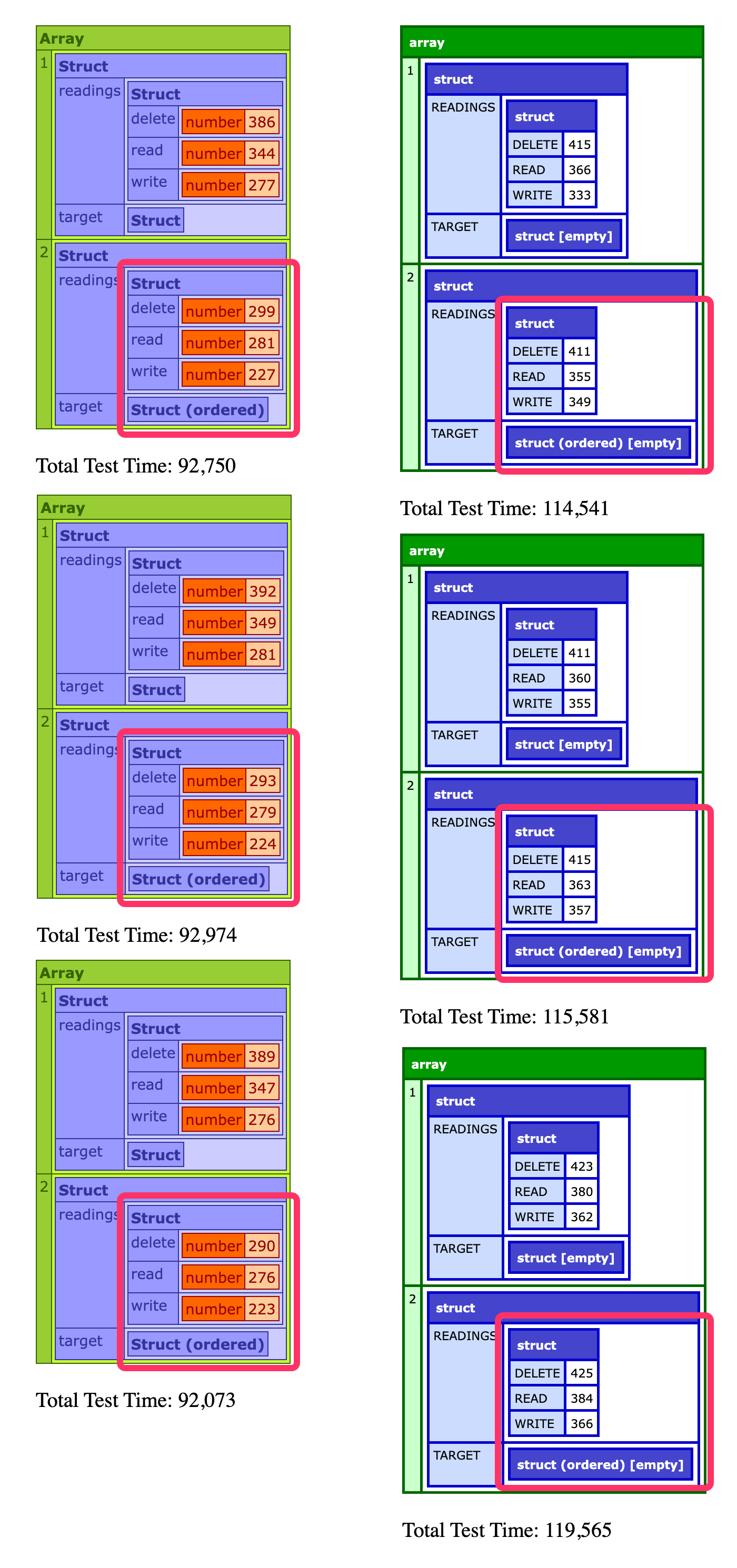
I'll ping Sean to see if maybe he can spot a logical error in my test methodology that would lead to these surprising results.
Just out of curiosity, I tried to run the tests again with fewer iterations (5 vs. 50) and more sub-iterations (100,000 vs. 10,000). I wanted to see how increasing the number of keys would affect the relative outcomes:
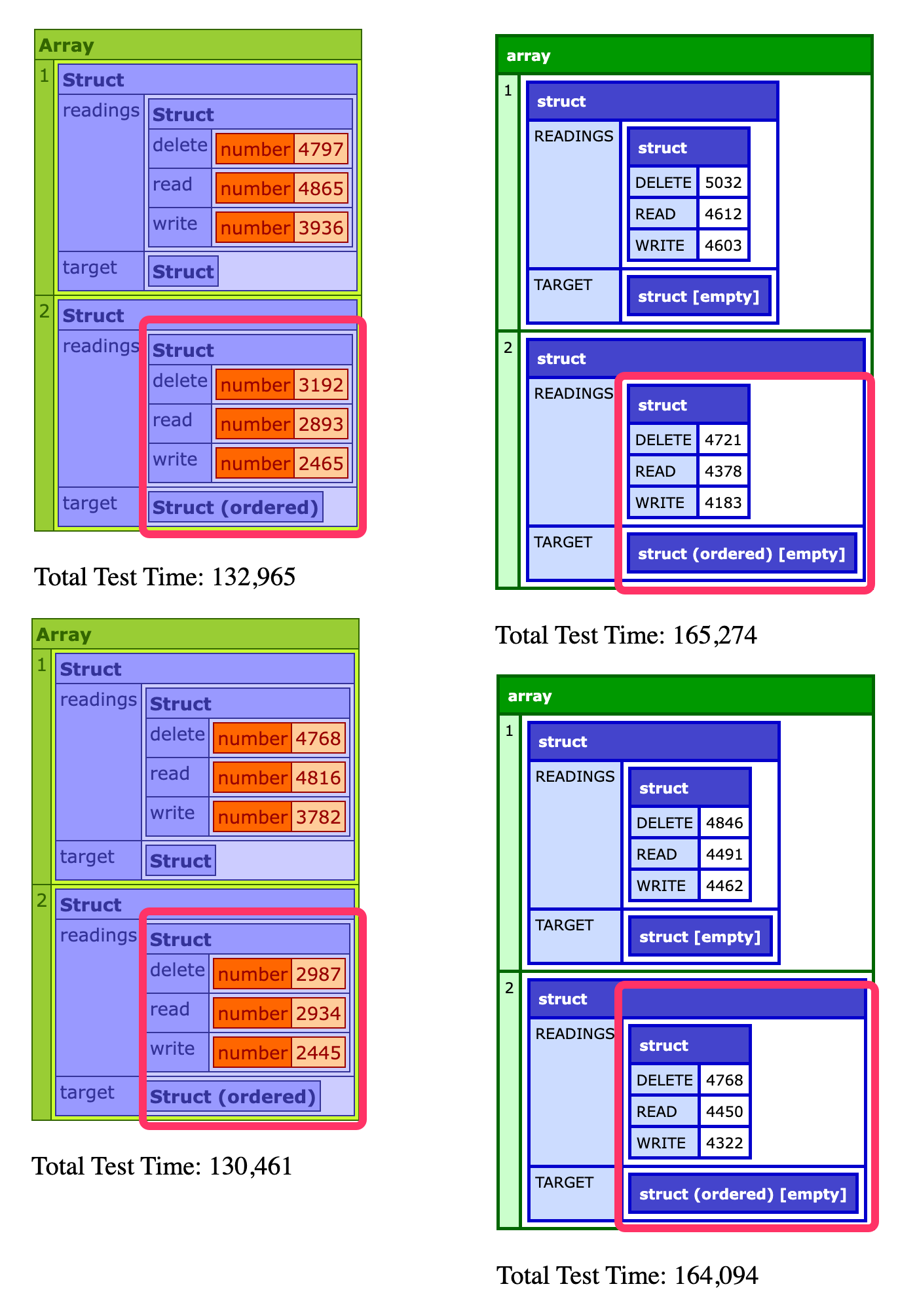
Increasing the number of keys by an order of magnitude didn't seem to have an impact on the output. In Lucee CFML, the ordered struct continues to be noticeably faster. And, in Adobe ColdFusion, both types of structs continue to be roughly equivalent.
Very curious information! Of course, this is all strictly academic (for me) since the size of my data structures is so small, on balance, that the different types of structs won't make any meaningful difference. But, the results were definitely unexpected. And, hopefully not because I have some terrible flaw in my logic.
Update: Focusing On Smaller Data Structures
After Sean took a look at the above experiment, his critique was that the large number of keys in the structure wasn't representative of a real-world scenario. Instead of performing fewer operations on a relatively large data structure, I should be performing more operations on a relatively small data structure.
Also, instead of calculating the average of the operations, I should be recording the total time for each operation across all the iterations.
I have created a second version of the code to try and address this feedback. It iterates 50,000 times and uses a sub-iteration of only 10 (keeping the data structure smaller).
<cfscript>
cfsetting( requestTimeout = 300 );
// We're going to iterate over these tests, and perform high(ish) volume operations
// ( write / read / delete ) on the two types of Structs (normal, ordered). The total
// of each operation will be recorded.
tests = [
{
target: {}, // NORMAL struct.
readings: {
write: 0,
read: 0,
delete: 0
}
},
{
target: [:], // ORDERED struct.
readings: {
write: 0,
read: 0,
delete: 0
}
}
];
pageStartedAt = getTickCount();
letters = shuffleChars( "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_" );
// In this version of the test, we're emphasizing MORE OPERATIONS on a SMALLER STRUCT
// in order to reflect a more realistic real-world data structure.
totalIterations = 50000;
totalSubIterations = 10;
for ( test in tests ) {
// Phase: WRITE ----- //
startedAt = getTickCount();
for ( iteration = 0 ; iteration <= totalIterations ; iteration++ ) {
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
test.target[ "#c##i#" ] = false;
}
}
}
test.readings.write = ( getTickCount() - startedAt );
// Phase: READ ----- //
startedAt = getTickCount();
temp = false;
for ( iteration = 0 ; iteration <= totalIterations ; iteration++ ) {
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
// All the struct values are FALSE, so this always evaluates the
// right-hand operand.
temp = ( temp || test.target[ "#c##i#" ] );
}
}
}
test.readings.read = ( getTickCount() - startedAt );
// Phase: DELETE ----- //
startedAt = getTickCount();
for ( iteration = 0 ; iteration <= totalIterations ; iteration++ ) {
for ( c in letters ) {
for ( i = 0 ; i <= totalSubIterations ; i++ ) {
test.target.delete( "#c##i#" );
}
}
}
test.readings.delete = ( getTickCount() - startedAt );
} // END: Tests.
writeDump( tests );
writeOutput( "<br />" );
writeOutput( "Total Test Time: #numberFormat( getTickCount() - pageStartedAt )#" );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I split the given input into an array and randomly shuffle it.
*/
public array function shuffleChars( required string input ) {
var chars = input.listToArray( "" );
createObject( "java", "java.util.Collections" )
.shuffle( chars )
;
return( chars );
}
</cfscript>
When we run this version, the relatively large difference I was seeing in Lucee CFML is gone. At this scale (of large iterations and smaller data structures), the write operation is a bit faster in the ordered struct, and the read and delete operations are a bit faster in the regular struct.
I ran it 4 times for Lucee CFML and 2 times for Adobe ColdFusion:

In my original test, Lucee CFML was faster (on the larger struct). But, with the smaller struct, Adobe ColdFusion seems faster.
Want to use code from this post? Check out the license.
Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →