
Creating A Group-Based Incrementing Value Using LAST_INSERT_ID() In MySQL 5.7.32 And Lucee CFML 5.3.7.47
Yesterday, I took inspiration from Jira's ticketing system and explored the idea of creating a group-based incrementing value in MySQL. In my approach, I used a SERIALIZABLE transaction to safely "update and read" a shared sequence value across parallel threads. In response to that post, my InVision co-worker - Michael Dropps - suggested that I look at using LAST_INSERT_ID(expr) to achieve the same outcome with less transaction isolation. I had never seen the LAST_INSERT_ID() function used with an expression argument before. So, I wanted to revisit yesterday's post using this technique.
View this code in my Jira-Inspired Ticketing Scheme project on GitHub.
To quickly recap the problem context, I want to maintain a secondary sequence within a table that repeats itself based on another value. To explore this, I created a Jira-inspired ticketing system that has a board table and a ticket table. Within the ticket table, we have two relevant columns:
boardID- The board in which the ticket is assigned.localID- The secondary sequence that increments based on theboardID. This value is used to define the "slug" that uniquely identifies the ticket (ex,MYBOARD-1, where1is thelocalIDvalue for that ticket, within that board).
In this database schema, the localID values are only unique to a given boardID; and, need to be safely incremented with each new ticket that is added to the system. In order to reduce the amount of locking that has to be performed in this workflow, I created a third table, board_ticket_incrementer, that keeps track of the largest localID for each board.
The entire MySQL database schema looks like this:
CREATE TABLE `board` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`companyID` int(10) unsigned NOT NULL,
`slug` varchar(10) NOT NULL,
`title` varchar(255) NOT NULL,
`createdAt` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `IX_bySlug` (`companyID`,`slug`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `board_ticket_incrementer` (
`boardID` int(10) unsigned NOT NULL,
`maxTicketID` int(10) unsigned NOT NULL,
PRIMARY KEY (`boardID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `ticket` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`boardID` int(10) unsigned NOT NULL,
`localID` int(10) unsigned NOT NULL, /* <=== !! Repeating Sequence. !! */
`title` varchar(255) NOT NULL,
`description` varchar(3000) NOT NULL,
`createdAt` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `IX_byLocalID` (`boardID`,`localID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Now, in yesterdays post, I was creating thread-safety around the board_ticket_incrementer table by putting it inside a SERIALAIZABLE transaction. As part of my "Create Ticket" workflow, I had a service-level method, incrementAndGetMaxTicketID(), that looked like this:
/**
* I increment the maxTicketID for the given board and return the incremented value.
*/
public numeric function incrementAndGetMaxTicketID( required numeric id ) {
// Since we need to atomically UPDATE a row and then READ the isolated result,
// we need to run this within a SERIALIZABLE transaction. This will LOCK the row
// with the given boardID for update ensuring that we read the incremented
// maxTicketID without having to worry about competing threads.
transaction isolation = "serializable" {
// WHY NOT USE A COUNT()? WHY STORE THE MAXTICKETID? If we were to use a
// COUNT() aggregate to calculate the next maxTicketID value on-the-fly, we
// wouldn't be able to account for historical records. As such, we might end
// up re-using old values as rows are deleted from the database. This could
// cause all sorts of referential integrity problems once ticket IDs make it
// out "into the wild". By persisting the maxTicketID, we make sure that it
// only ever contains historically-unique values.
boardGateway.incrementMaxTicketID( id );
return( boardGateway.getMaxTicketID( id ) );
}
}
The resultant value of this method call would then be used as the localID value in the pending ticket record (which has a UNIQUE KEY index constraint on (boardID,localID)).
In order to prevent dirty reads across parallel threads, the SERIALIZABLE transaction locks the UPDATE row in the first gateway (Data Access Object) call such that the SELECT in my subsequent call can safely read the modified value before it is altered by any parallel query. This approach has overhead in that:
- It locks the row in question for the duration of the transaction.
- It has to make two network calls to complete the transaction.
This is where Michael Dropps' suggestion to use LAST_INSERT_ID(expr) comes into play. According to the MySQL documentation, when used without an argument, the LAST_INSERT_ID() function returns:
.... the first automatically generated value successfully inserted for an
AUTO_INCREMENTcolumn as a result of the most recently executedINSERTstatement.
This is the only way that I've ever seen this function used - to return the new primary key value of an inserted row. Similar to returning @@Identity after an INSERT statement.
If you pass an expression to the LAST_INSERT_ID() function, it will take on two properties:
It will return the expression as part of the evaluation.
It will return the same expression the next time the function is called without an argument.
Furthermore, the MySQL documentation states that this is safe to call in a multi-user environment:
You can generate sequences without calling
LAST_INSERT_ID(), but the utility of using the function this way is that theIDvalue is maintained in the server as the last automatically generated value. It is multi-user safe because multiple clients can issue theUPDATEstatement and get their own sequence value with theSELECTstatement (ormysql_insert_id()), without affecting or being affected by other clients that generate their own sequence values.
What this means is that instead of breaking the "update" and "get" actions across two different database queries - as I've done above - we can combine the two gestures into a single query:
/**
* I increment the maxTicketID value for the given board and return the resultant
* value.
*/
public numeric function incrementAndGetMaxTicketID( required numeric boardID ) {
```
<cfquery name="local.results">
UPDATE
board_ticket_incrementer
SET
maxTicketID = LAST_INSERT_ID( maxTicketID + 1 )
WHERE
boardID = <cfqueryparam value="#boardID#" sqltype="integer" />
;
SELECT
LAST_INSERT_ID() AS maxTicketID
;
</cfquery>
```
return( results.maxTicketID );
}
To break this orchestration down, this UPDATE statement:
SET maxTicketID = LAST_INSERT_ID( maxTicketID + 1 )
Both increments the column value and saves the resultant, incremented value into the LAST_INSERT_ID() function such that it is returned in this SELECT statement within the same database query:
SELECT LAST_INSERT_ID() AS maxTicketID
Now, I can go back into my BoardService.cfc ColdFusion component and use this new method to "increment and get" the next localID value:
/**
* I increment the maxTicketID for the given board and return the incremented value.
*/
public numeric function incrementAndGetMaxTicketID( required numeric id ) {
// NOTE: Using LAST_INSERT_ID() to safely increment-and-get the maxTicketID with
// reduced locking and network calls while still being thread-safe.
return( boardGateway.incrementAndGetMaxTicketID( id ) );
// --
// SHORT-CIRCUITED - this OLDER approach no longer executes:
// --
// Since we need to atomically UPDATE a row and then READ the isolated result,
// we need to run this within a SERIALIZABLE transaction. This will LOCK the row
// with the given boardID for update ensuring that we read the incremented
// maxTicketID without having to worry about competing threads.
transaction isolation = "serializable" {
// WHY NOT USE A COUNT()? WHY STORE THE MAXTICKETID? If we were to use a
// COUNT() aggregate to calculate the next maxTicketID value on-the-fly, we
// wouldn't be able to account for historical records. As such, we might end
// up re-using old values as rows are deleted from the database. This could
// cause all sorts of referential integrity problems once ticket IDs make it
// out "into the wild". By persisting the maxTicketID, we make sure that it
// only ever contains historically-unique values.
boardGateway.incrementMaxTicketID( id );
return( boardGateway.getMaxTicketID( id ) );
}
}
This method is then used in my create ticket workflow / use-case to increment the localID for a given board such that it can subsequently create a ticket with a unique (boardID,localID) combination:
component
accessors = true
output = false
hint = "I provide workflow methods for boards."
{
// Define properties for dependency-injection.
property boardService;
property ticketService;
// ---
// PUBLIC METHODS.
// ---
/**
* I create a new board and return the ID of the board.
*/
public numeric function createBoard(
required numeric companyID,
required string slug,
required string title
) {
var boardID = boardService.createBoard(
companyID = companyID,
slug = slug,
title = title
);
return( boardID );
}
/**
* I create a new ticket within the given board and return the ID of the new ticket.
*/
public numeric function createTicket(
required numeric boardID,
required string title,
required string description
) {
var board = boardService.getBoardByID( boardID );
// Each ticket will have a board-specific (local) ID. This allows a ticket to be
// uniquely identified by a combination of the board SLUG and the LOCAL ID such
// that two tickets with the same local ID, ex: "MYBOARD-1" and "YOURBOARD-1",
// can peacefully coexist.
// --
// NOTE: We're using the LAST_INSERT_ID() function, under the hood, to safely
// increment this value across parallel requests.
var localID = boardService.incrementAndGetMaxTicketID( board.id );
var ticketID = ticketService.createTicket(
boardID = board.id,
localID = localID,
title = title,
description = description
);
return( ticketID );
}
}
Of course, we still want to make sure that this actually works. And, if it had any impact on performance. So, I took my load-test from the previous post and I updated it to include a CFTimer tag. Now, when we generate 10,000 tickets in parallel across two different board records, we can see how the two different approaches fare:
<cfscript>
ninjaBoardID = application.boardWorkflow.createBoard(
companyID = 1,
slug = "NINJA",
title = "Ninja Board"
);
rockstarBoardID = application.boardWorkflow.createBoard(
companyID = 1,
slug = "ROCK",
title = "Rockstar Board"
);
// Create competing, sibling threads for the both the ROCKSTAR and NINJA boards -
// each thread is going to try and create a large number of tickets, competing with
// the sibling threads for localID ticket values.
loop times = 10 {
// LOOP will end up spawning 10 parallel threads and 10,000 tickets for ROCKSTAR.
loadTestBoard( rockstarBoardID, 1000 );
// LOOP will end up spawning 10 parallel threads and 10,000 tickets for NINJA.
loadTestBoard( ninjaBoardID, 1000 );
}
timer
type = "outline"
label = "Load Test Execution"
{
thread action = "join";
dump( cfthread );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I spawn an asynchronous thread that creates the given number of tickets on the
* given board.
*/
public void function loadTestBoard(
required numeric boardID,
required numeric ticketCount
) {
thread
name = "load-test-#createUniqueId()#"
boardID = boardID
ticketCount = ticketCount
{
loop times = ticketCount {
application.boardWorkflow.createTicket(
boardID = boardID,
title = "Ticket #createUniqueId()#",
description = "Never gonna give you up, never gonna let you down."
);
}
}
}
</cfscript>
First, I ran this about 10 times with the old approach and selected the 5 longest execution times:
Old Method: Using SERIALIZABLE transaction:
- Load Test Execution: 99,978 ms
- Load Test Execution: 92,423 ms
- Load Test Execution: 89,788 ms
- Load Test Execution: 94,659 ms
- Load Test Execution: 88,517 ms
Then, I updated the workflow code to use the new LAST_INSERT_ID() approach and used the same strategy - running it 10 times and selected the 5 longest execution times:
New Method: Using LAST_INSERT_ID():
- Load Test Execution: 52,441 ms
- Load Test Execution: 40,282 ms
- Load Test Execution: 45,239 ms
- Load Test Execution: 47,421 ms
- Load Test Execution: 46,509 ms
Oh my chickens! The LAST_INSERT_ID() method is about twice as fast! Of course, some performance gain is to be expected since the new approach is making half the network calls (one query instead of two); and, it's not using a SERIALIZABLE transaction.
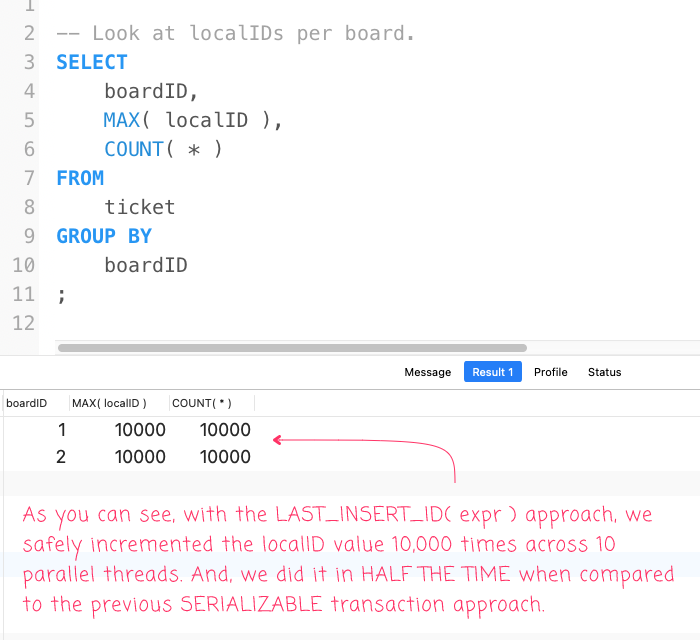
But, is it "correct"? To verify, I ran the same SQL statement from the previous post:
-- Look at localIDs per board.
SELECT
boardID,
MAX( localID ),
COUNT( * )
FROM
ticket
GROUP BY
boardID
;
And, I got the same exact outcome!
For this look at the LAST_INSERT_ID() approach, I've only reproduced part of the code from my previous post. If you want to see the entirety of the demo code, check out my GitHub project:
View this code in my Jira-Inspired Ticketing Scheme project on GitHub.
A huge shout-out to Michael Dropps for pointing me in this direction (and to Marc Fruchter who shared this technique with Michael). I love that this reduces the complexity and improves the performance of generating a group-based, incrementing value in MySQL and Lucee CFML.
Epilogue on LAST_INSERT_ID() FUD (Fear, Uncertainty, Doubt)
I should add that in my old post on the comparison between LAST_INSERT_ID() and @@Identity, many people in the comments section railed against the use of LAST_INSERT_ID(), in general, because it can become "confused" if a table has triggers that are executing SQL statements in the background. Triggers can cause other INSERT statements to run in between your INSERT statement and the subsequent LAST_INSERT_ID() call, which can lead to an unexpected outcome.
That said, I'm not a fan of triggers because (I believe) they violate the "Principle of Least Surprise". As such, I've never run into this issue; and, I have no instinct as to whether or not that issue even applies to the use-case we are discussing in this post.
Want to use code from this post? Check out the license.

Reader Comments
Oh nice! I had no idea LAST_INSERT_ID() could be seeded, I assumed it was always read only. Very clever trick, thanks for posting!
@Kurt,
Heck yeah! This was news to me as well; and will much welcomed into my SQL strategies.
I love this approach so much! At first I was like (wha 🤔) as you described the technical aspects of the
LAST_INSERT_ID(expr)but it all came together for me with your example. Thanks for being you, Ben! Much appreciated!@Chris,
Ha ha, that's the exact same reaction I had when Michael was describing it to me -- I was like, "Umm, what?!". I really had to see it in action before it clicked.