
Creating A Group-Based Incrementing Value In MySQL 5.7.32 And Lucee CFML 5.3.7.47
UPDATE: After posting this, I was told to look at the use of LAST_INSERT_ID(expr) as a way to build thread-safe sequences in MySQL. I have written a follow-up post that revisits this demo using LAST_INSERT_ID() instead of the SERIALIZABLE transaction.
In the past few weeks, I've been learning a lot about how I can leverage SERIALIZABLE transactions in MySQL, the scope of said transactions, and some hidden gotchas around locking empty rows. As a means to lock (no pun intended) some of that information in my head-meat, I thought it would be a fun code kata to create a Jira-inspired ticketing system in Lucee CFML 5.3.7.47 that uses an application-defined, group-based incrementing value in MySQL 5.7.32.
View this code in my Jira-Inspired Ticketing Scheme project on GitHub.
Jira is a massively flexible product. And, I honestly don't know it very well. At InVision, I only use the Kanban style workflow in which there are Boards and Tickets. Each Ticket is represented by a globally unique slug that is a combination of the Board slug and Board-local, increment ID value.
NOTE: "Globally unique" in this case is unique to the "organization" that owns the boards - not to the entirety of Jira itself.
So, if you can imagine two boards with the slugs, MINE and YOURS, the first ticket in each board would be represented by MINE-1 and YOURS-1, respectively. Then, the second ticket in each board would be MINE-2 and YOURS-2; and so on, with each board having a board-specific incrementing value starting at 1 and going up with each newly-created ticket.
Normally, with a relational database, I would lean on the AUTO_INCREMENT property of an id column to manage an incrementing value. However, in this case, our sequence of IDs is not globally unique - it's locally unique to a given board. As such, these "local IDs" need to be managed by the ColdFusion code, not by the database schema.
NOTE: I'm using MySQL for this exploration, which doesn't include any mechanics for multiple auto-incrementing values in a single table. Other relational databases may have something that handles this kind of requirement out of the box. If you know of one, please drop a comment below - I'd be curious to hear about it.
What this means is that we have to store a board-specific ticket ID offset in the database - something that we can manually increment whenever we create a new ticket. And, we have to manage it in a way that doesn't accidentally create dirty reads or colliding values.
Historically, I'd use something like a distributed-lock in order to synchronize access to a piece of data. Distributed locks can be messy; and, I've been trying to lean on low-level MySQL database locks for idempotent workflows. As such, I think we can use SERIALIZABLE transaction isolation to drive our synchronization without any application-level locking.
The next question then becomes where to store this board-specific, local ticket ID? Earlier in my career, I would have stored this as some sort of maxTicketID within the board table itself. The problem with this approach, as I've learned over the years, is that we can end-up creating a lot of contention around the rows in the board table. Since we're going to be using SERIALIZABLE transactions to lock access to our manually-incremented value, it means that if this value were in the board table, we'd end-up applying a lot of locks to the board table - a table which is likely to have high-read volume.
A more performant approach would be to split high-read and high-write data into separate tables. In this case, we might have a table for the boards and a separate table specifically for tracking the board-local ticket ID. This way, even if we're constantly locking our secondary table, the board table will continue to allow for high-read throughput.
Ultimately, here's the MySQL database schema that I'm using for this exploration:
CREATE TABLE `board` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`companyID` int(10) unsigned NOT NULL,
`slug` varchar(10) NOT NULL,
`title` varchar(255) NOT NULL,
`createdAt` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `IX_bySlug` (`companyID`,`slug`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `board_ticket_incrementer` (
`boardID` int(10) unsigned NOT NULL,
`maxTicketID` int(10) unsigned NOT NULL,
PRIMARY KEY (`boardID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `ticket` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`boardID` int(10) unsigned NOT NULL,
`localID` int(10) unsigned NOT NULL,
`title` varchar(255) NOT NULL,
`description` varchar(3000) NOT NULL,
`createdAt` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `IX_byLocalID` (`boardID`,`localID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
As you can see, I've created a board_ticket_incrementer table that does nothing but manage our board-local ticket IDs. We can apply SERIALIZABLE transaction-locks to this table until the cows come home and we won't negatively impact the throughput of either our board or our ticket tables.
In addition to this utility table, this small database schema is also leaning heavily on unique keys to enforce data integrity:
UNIQUE KEY `IX_bySlug` (`companyID`,`slug`)- This ensures that every board record has a unique slug within the context of an organization.UNIQUE KEY `IX_byLocalID` (`boardID`,`localID`)- This ensures that every ticket record has a uniquelocalIDwithin a given board. So, not only are we going to synchronize access to themaxTicketID, we're also preventinglocalIDcollisions just in case something goes wrong with our synchronization logic (ie, "developer error").
Building robust ColdFusion applications is complex. The database schema and the application code are not islands unto themselves - they have to work hand-in-hand to enforce data integrity while also trying to optimize throughput and, when possible, provide for idempotent operations. It's not always clear where certain responsibilities lie. My understanding of application layering continues to evolve; and, at this time, I'm using a "Workflow" (ie, "Use Case") layer to organize cross-entity coordination:
Workflow layer - Implements the "commands" / use-cases into the system, coordinating actions across entities and infrastructure services.
Service layer - Implements the entity-level business logic and constraints. This layer does not care about other entities within the system; and, cannot enforce constraints within unrelated entities.
Data access layer - Implements the data-persistence for the entities.
For this exploration, I ended up representing layering with the following ColdFusion components - the indentation here conceptually represents the inversion-of-control (IoC) / dependency-injection (DI):
BoardWorkflow.cfc- The "workflow" component that manages commands / use-cases for the concept of "boards". It will coordinate / orchestrate calls across the Board and Ticket entity services.BoardService.cfcBoardGateway.cfc- Data access object (DAO) for boards.
TicketService.cfcTicketGateway.cfc- Data access object (DAO) for ticket.
When a new ticket is created within the system we have to do two things:
Increment and read the local ID within
board_ticket_incrementer.Create a
ticketrecord using the aforementioned local ID.
The first item is a responsibility tightly coupled to the "board" concept. The second item is a responsibility of the "ticket" concept. Since the BoardService.cfc doesn't know about the TicketService.cfc, and vice-versa, it's up to the BoardWorkflow.cfc to make sure that both of these happen in the correct order. Here's my BoardWorkflow.cfc:
component
accessors = true
output = false
hint = "I provide workflow methods for boards."
{
// Define properties for dependency-injection.
property boardService;
property ticketService;
// ---
// PUBLIC METHODS.
// ---
/**
* I create a new board and return the ID of the board.
*/
public numeric function createBoard(
required numeric companyID,
required string slug,
required string title
) {
var boardID = boardService.createBoard(
companyID = companyID,
slug = slug,
title = title
);
return( boardID );
}
/**
* I create a new ticket within the given board and return the ID of the new ticket.
*/
public numeric function createTicket(
required numeric boardID,
required string title,
required string description
) {
var board = boardService.getBoardByID( boardID );
// Each ticket will have a board-specific (local) ID. This allows a ticket to be
// uniquely identified by a combination of the board SLUG and the LOCAL ID such
// that two tickets with the same local ID, ex: "MYBOARD-1" and "YOURBOARD-1",
// can peacefully coexist.
// --
// CAUTION: The following method uses a SERIALIZABLE transaction under the hood
// in order to lock the board-row for the increment-and-get operation. DO NOT try
// to include this operation in a larger, multi-statement transaction as
// extending the serializable transaction to include different tables may cause
// unexpected deadlocks (especially if the ticket table has no rows associated
// with a given board ID). Read more at:
// --
// https://www.bennadel.com/blog/4133-the-scope-of-serializable-transaction-row-locking-is-larger-when-rows-dont-yet-exist-in-mysql-5-7-32.htm
// https://bugs.mysql.com/bug.php?id=25847
// https://stackoverflow.com/questions/17068686/how-do-i-lock-on-an-innodb-row-that-doesnt-exist-yet
var localID = boardService.incrementAndGetMaxTicketID( board.id );
var ticketID = ticketService.createTicket(
boardID = board.id,
localID = localID,
title = title,
description = description
);
return( ticketID );
}
}
As you can see, the workflow calls into the BoardService.cfc to generate a new localID value. It then takes this value and uses it when calling the TicketService.cfc. Conceptually, I think this makes sense. The ticketing system understands that the board/local ID combination has to be unique, hence the underlying UNIQUE KEY in the database. But, it doesn't need know how that local ID itself is generated - that's beyond its domain of responsibility.
The incrementAndGetMaxTicketID() method is probably the most interesting part of this entire demo. It needs to update a value and then read the result without creating race-conditions. It does this using SERIALIZABLE transaction isolation:
component
accessors = true
output = false
hint = "I provide entity methods for boards."
{
// Define properties for dependency-injection.
property boardGateway;
// ---
// PUBLIC METHODS.
// ---
/**
* I create a new board and return the ID of the generated record.
*/
public numeric function createBoard(
required numeric companyID,
required string slug,
required string title
) {
if ( ! slug.len() ) {
throwEmptySlugError( arguments );
}
if ( ! title.len() ) {
throwEmptyTitleError( arguments );
}
var existingBoards = boardGateway.getBoardsByFilter(
companyID = companyID,
slug = slug
);
// NOTE: The underlying database enforces a UNIQUE KEY on the companyID / slug
// combination. However, by explicitly checking for a conflict prior to creation,
// it gives us a chance to throw a more consumable error (instead of bubbling-up
// a key-constraint violation error from the database).
if ( existingBoards.len() ) {
throwSlugConflictError( arguments );
}
transaction {
var id = boardGateway.createBoard(
companyID = companyID,
slug = slug,
title = title,
createdAt = dateConvert( "local2utc", now() )
);
// NOTE: We are keeping track of the board-local maxTicketID in an isolated
// table since incrementing and reading the maxTicketID will require a
// SERIALIZABLE transaction row-lock in the future. And, we don't want to
// have locks on the main board table affect other parts of the application.
boardGateway.createTicketIncrementer(
boardID = id,
maxTicketID = 0
);
}
return( id );
}
/**
* I return the board with the given ID.
*/
public struct function getBoardByID( required numeric id ) {
var boards = boardGateway.getBoardsByFilter( id = id );
if ( ! boards.len() ) {
throwBoardNotFoundError( arguments );
}
return( boards.first() );
}
/**
* I increment the maxTicketID for the given board and return the incremented value.
*/
public numeric function incrementAndGetMaxTicketID( required numeric id ) {
// Since we need to atomically UPDATE a row and then READ the isolated result,
// we need to run this within a SERIALIZABLE transaction. This will LOCK the row
// with the given boardID for update ensuring that we read the incremented
// maxTicketID without having to worry about competing threads.
transaction isolation = "serializable" {
// WHY NOT USE A COUNT()? WHY STORE THE MAXTICKETID? If we were to use a
// COUNT() aggregate to calculate the next maxTicketID value on-the-fly, we
// wouldn't be able to account for historical records. As such, we might end
// up re-using old values as rows are deleted from the database. This could
// cause all sorts of referential integrity problems once ticket IDs make it
// out "into the wild". By persisting the maxTicketID, we make sure that it
// only ever contains historically-unique values.
boardGateway.incrementMaxTicketID( id );
return( boardGateway.getMaxTicketID( id ) );
}
}
// ---
// PRIVATE METHODS.
// ---
/**
* I throw a not-found error for the given context.
*/
private void function throwBoardNotFoundError( required struct errorContext ) {
throw(
type = "Board.NotFound",
message = "Board not found",
extendedInfo = serializeJson( errorContext )
);
}
/**
* I throw an empty-slug error for the given context.
*/
private void function throwEmptySlugError( required struct errorContext ) {
throw(
type = "Board.EmptySlug",
message = "Board cannot have an empty slug",
extendedInfo = serializeJson( errorContext )
);
}
/**
* I throw an empty-title error for the given context.
*/
private void function throwEmptyTitleError( required struct errorContext ) {
throw(
type = "Board.EmptyTitle",
message = "Board cannot have an empty title",
extendedInfo = serializeJson( errorContext )
);
}
/**
* I throw a slug conflict error for the given context.
*/
private void function throwSlugConflictError( required struct errorContext ) {
throw(
type = "Board.SlugConflict",
message = "Slug value already being used",
extendedInfo = serializeJson( errorContext )
);
}
}
As you can see, within the boundary of the SERIALIZABLE transaction, this service layer is making two calls into the data access layer:
incrementMaxTicketID()getMaxTicketID()
Due to the way that transaction locking works in MySQL, the SERIALIZABLE isolation locks any row touched by an UPDATE statement. As such, our incrementMaxTicketID() call causes our board_ticket_incrementer row to be locked for the duration of the transaction. This ensures that no other processes can alter that row before our subsequent SELECT in the getMaxTicketID() call. This prevents dirty reads.
The data access layer for boards is fairly simple. I'm using the same Gateway (DAO) to manage both the board and board_ticket_incrementer tables since they feel like concepts that cannot exist independently of one another. Note that I'm using Tag Islands in Lucee CFML to seamlessly leverage the awesome CFQuery tag inside my script-based component:
component
output = false
hint = "I provide data-access methods for boards."
{
/**
* I create a new board and return the ID of the generated record.
*/
public numeric function createBoard(
required numeric companyID,
required string slug,
required string title,
required date createdAt
) {
```
<cfquery result="local.insertResults">
INSERT INTO
board
SET
companyID = <cfqueryparam value="#companyID#" sqltype="integer" />,
slug = <cfqueryparam value="#slug#" sqltype="varchar" />,
title = <cfqueryparam value="#title#" sqltype="varchar" />,
createdAt = <cfqueryparam value="#createdAt#" sqltype="timestamp" />
;
</cfquery>
```
return( insertResults.generatedKey );
}
/**
* I create a new board ticket incrementer row to keep track of local IDs.
*/
public void function createTicketIncrementer(
required numeric boardID,
required numeric maxTicketID
) {
```
<cfquery name="local.results">
INSERT INTO
board_ticket_incrementer
SET
boardID = <cfqueryparam value="#boardID#" sqltype="integer" />,
maxTicketID = <cfqueryparam value="#maxTicketID#" sqltype="integer" />
;
</cfquery>
```
}
/**
* I return the boards that match the given filter criteria.
*/
public array function getBoardsByFilter(
numeric id = 0,
numeric companyID = 0,
string slug = ""
) {
```
<cfquery name="local.results" returntype="array">
SELECT
b.id,
b.companyID,
b.slug,
b.title,
b.createdAt
FROM
board b
WHERE
TRUE
<cfif id>
AND
id = <cfqueryparam value="#id#" sqltype="integer" />
</cfif>
<cfif companyID>
AND
companyID = <cfqueryparam value="#companyID#" sqltype="integer" />
</cfif>
<cfif slug.len()>
AND
slug = <cfqueryparam value="#slug#" sqltype="varchar" />
</cfif>
;
</cfquery>
```
return( results );
}
/**
* I get the maxTicketID value for the given board.
*/
public numeric function getMaxTicketID( required numeric boardID ) {
```
<cfquery name="local.results">
SELECT
i.maxTicketID
FROM
board_ticket_incrementer i
WHERE
i.boardID = <cfqueryparam value="#boardID#" sqltype="integer" />
;
</cfquery>
```
return( val( results.maxTicketID ) );
}
/**
* I increment the maxTicketID value for the given board.
*/
public void function incrementMaxTicketID( required numeric boardID ) {
```
<cfquery name="local.results">
UPDATE
board_ticket_incrementer
SET
maxTicketID = ( maxTicketID + 1 )
WHERE
boardID = <cfqueryparam value="#boardID#" sqltype="integer" />
;
</cfquery>
```
}
}
Each of these application layers so far is, conceptually, fairly simple. The Gateway components perform basic CRUD (Create, Read, Update, Delete) operations; the Service components perform come low-level validation; and, the Workflow components just coordinate calls across services. But, bring this all together, we can build a fairly sophisticated system.
That said, let's make sure this actually works! Meaning, does this configuration of ColdFusion components and database keys actually enforce constraints and prevent dirty data under load? To test the code, I created a simple load-test that generates two different board records and then spawns 5 asynchronous CFThread tags for each board that each attempt to insert 1,000 ticket records in parallel:
<cfscript>
ninjaBoardID = application.boardWorkflow.createBoard(
companyID = 1,
slug = "NINJA",
title = "Ninja Board"
);
rockstarBoardID = application.boardWorkflow.createBoard(
companyID = 1,
slug = "ROCK",
title = "Rockstar Board"
);
// Create competing, sibling threads for the both the ROCKSTAR and NINJA boards -
// each thread is going to try and create a large number of tickets, competing with
// the sibling threads for localID ticket values.
loop times = 10 {
// LOOP will end up spawning 10 parallel threads and 10,000 tickets for ROCKSTAR.
loadTestBoard( rockstarBoardID, 1000 );
// LOOP will end up spawning 10 parallel threads and 10,000 tickets for NINJA.
loadTestBoard( ninjaBoardID, 1000 );
}
thread action = "join";
dump( cfthread );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I spawn an asynchronous thread that creates the given number of tickets on the
* given board.
*/
public void function loadTestBoard(
required numeric boardID,
required numeric ticketCount
) {
thread
name = "load-test-#createUniqueId()#"
boardID = boardID
ticketCount = ticketCount
{
loop times = ticketCount {
application.boardWorkflow.createTicket(
boardID = boardID,
title = "Ticket #createUniqueId()#",
description = "Never gonna give you up, never gonna let you down."
);
}
}
}
</cfscript>
With this load test, we have two sets of 5 threads that are all competing for the same database resources. And, when this load test finishes, we can check the state of the system using the following query:
-- Look at localIDs per board.
SELECT
boardID,
MAX( localID ),
COUNT( * )
FROM
ticket
GROUP BY
boardID
;
What we're hoping to see is two records, each of which has 10,000 for both the count and the maximum localID. And, when we run this in MySQL, we get the following output:
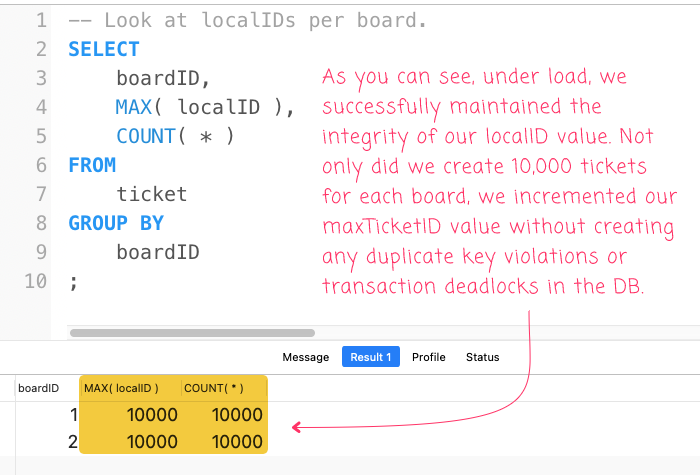
As you can see, it worked! Even under load, with 5 parallel threads per board, we were able to generate 10,000 tickets (for each board) without causing any transaction deadlocks or violating the uniqueness constraint of the localID within each board. And, we did so without any application-level locking! All we had to do was lean a little on the SERIALIZABLE transaction isolation provided by the MySQL database.
I'm not going to bother showing the the TicketService.cfc or the TicketGateway.cfc - they don't really do anything interesting above and beyond what the "Board" ColdFusion components are doing. You can always look in the GitHub project if you want more detail:
View this code in my Jira-Inspired Ticketing Scheme project on GitHub.
At first, I thought this exploration was going to be fairly straightforward. I assumed creating a group-based incrementing value in MySQL wouldn't be that interesting. But, it ended-up taking me about 4-mornings to put together. And, I found myself thinking a lot about ColdFusion application layering, separation of concerns, database throughput, synchronization, and schema constraints. I wound up getting way more out of this than I even intended to. That's a code kata for-the-win right there!
Want to use code from this post? Check out the license.

Reader Comments
Nice post Ben!
One other thing to mention that can also keep transaction/locking/latency low is to either do multiple queries in your CFQUERY tag (if your DB connection settings are setup to allow it), or create and call stored proc. That way you don't incur the network latency betwen the separate CFQUERY blocks to update/select the maxID.
Basically select maxID into local var, increment local var, update table using local var, return the local var (I'd include the actual code but the comment won't let me)
@Kurt,
I'm pro-multi-queries. When I create a datasource, one of the first things I always do is make sure
allowMultiQueries=trueis in the connection-string. Though, I'll admit that over the years, I've started to simplify the SQL that I write. Things used to get so complex; now, I try to keep things smaller and more straightforward (when I can - doing so doesn't always make sense).That's a good point, though about contention and network latency - I hadn't really considered it from that perspective before; but, it makes total sense.
Someone at work was just showing me a trick with
LAST_INSERT_ID(), which I had never seen before (in relation to this post). I'll hopefully have a follow-up in the morning.@Kurt,
Oh, and sorry it wasn't letting you post the comment with the sql. I'll see if I can find any error logs about it.
@All,
I just posted a follow-up exploration of this same workflow (ticketing system); but, using
LAST_INSERT_ID()instead of aSERIALIZABLEtransaction:www.bennadel.com/blog/4136-creating-a-group-based-incrementing-value-using-last-insert-id-in-mysql-5-7-32-and-lucee-cfml-5-3-7-47.htm
This is great! It reduces the complexity of the code and doubles the performance of the load-test in my demo. I've never seen this function used this way before; but, it's documented right there in the MySQL documentation: