
Experimenting With Virtual Indexed Columns In MySQL 5.7.32 And Lucee CFML 5.3.7.47
As I mentioned in an earlier post, InVision is upgrading some of its MySQL servers to 5.7.32 (for Long-Term Support, LTS). This upgrade brings with it some excited features like the JSON column type. It also unlocks the ability to add virtual columns to a table which can be derived from existing columns; and, as needed, get stored in a secondary index on said table. When I read about this feature, I immediately thought of the ability to derive email domain from a user's email address. This is something that our data scientists and product teams are always asking about. As such, I wanted to sit down and see what a virtual "email domain column" might look like in MySQL 5.7.32 and Lucee CFML 5.3.7.47.
To lay the foundation for this exploration, let's create a super simple user_account table that contains basic login information for a set of users. To start with, we're just going to include email and password:
CREATE TABLE `user_account` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`email` varchar(75) NOT NULL,
`password` varchar(35) NOT NULL,
`createdAt` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `byEmail` (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Now, let's jam some data all up in this table using ColdFusion! When doing this, we're going to randomly generate a bunch of email addresses based on a combination of example. base domains:
<cfscript>
// NOTE: These domains are reserved by the Internet Engineering Task Force to be
// special domains used in documentation.
// --
// https://en.wikipedia.org/wiki/Example.com
baseDomains = [ "example.com", "example.net", "example.org", "example.edu" ];
// Some random subdomains to make a larger pool of unique domains.
subDomains = [
"app", "www", "admin", "personal", "root", "demo", "test", "projects", "data",
"teams", "internal", "accounts", "support", "control", "secure", "westeros"
];
// Generate random records in our user_account table.
loop times = 1000 {
baseDomain = baseDomains[ randRange( 1, baseDomains.len() ) ];
subDomain = subDomains[ randRange( 1, subDomains.len() ) ];
email = "user-#createUniqueId()#@#subDomain#.#baseDomain#";
// CAUTION: Obviously, this is just a DEMO, which means I don't care about the
// password security. In production, you would NEVER want to use a UUID as a
// randomly-generated password because it is somewhat predictable. You would need
// to use a SECURE pseudo-random generator.
password = createUuid();
```
<cfquery>
INSERT INTO
user_account
SET
email = <cfqueryparam value="#email#" sqltype="varchar" />,
password = <cfqueryparam value="#password#" sqltype="varchar" />,
createdAt = <cfqueryparam value="#now()#" sqltype="timestamp" />
;
</cfquery>
```
}
</cfscript>
At this point, we have 1,000 users in our user_account table with random email addresses. However, many of these users will share a domain with other users, possibly because they work at the same company. This is the kind of information that our data scientists want to know about: how many people look like they work at the same company?
To help answer this question, we could run a SQL query like this that extracts that data on-the-fly:
SELECT
SUBSTRING_INDEX( a.email, '@', -1 ) AS emailDomain,
COUNT( * ) AS userCount
FROM
user_account a
GROUP BY
SUBSTRING_INDEX( a.email, '@', -1 )
ORDER BY
userCount DESC
LIMIT
10
;
This gets the us the information that we are looking for:
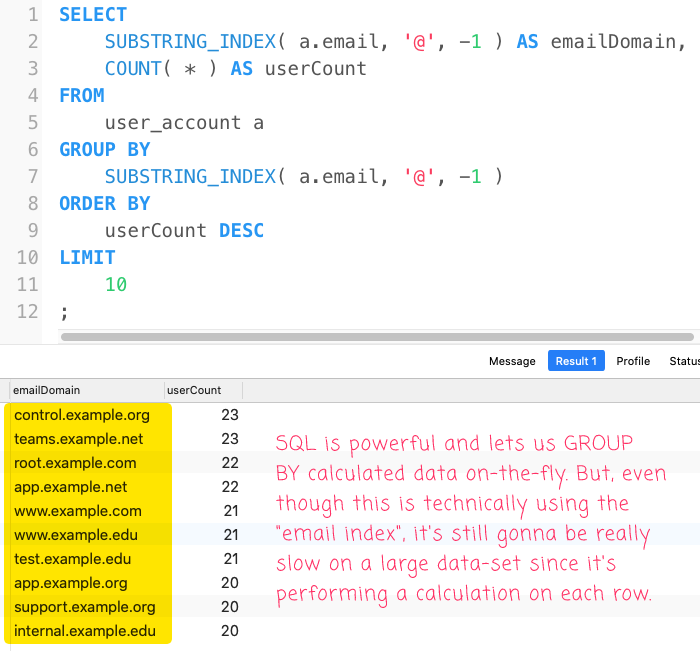
However, this is going to be slooooow since it has to run the calculation on every row, twice: once in the GROUP BY and once in the SELECT. Which is where our virtual column can come into play.
To try this out, let's take our on-the-fly calculation from above:
SUBSTRING_INDEX( a.email, '@', -1 ) AS emailDomain
... and add to the user_account table using an ALTER statement. In the following SQL script, I've added some line-breaks to make the code a bit more readable:
-- Let's add a VIRTUAL column that contains the DOMAIN of each email address. We can
-- calculate this value by taking the SUBSTRING of everything that comes after the last
-- occurrence of the list-delimiter, '@'. And, on top of that, we're going to index it
-- using a SECONDARY INDEX so that we can quickly search and aggregate email domains.
ALTER TABLE
`user_account`
ADD COLUMN
`emailDomain` varchar(75)
GENERATED ALWAYS AS (SUBSTRING_INDEX( `email`, '@', -1 ))
VIRTUAL
AFTER `email`,
ADD INDEX
`byEmailDomain` (`emailDomain`)
;
As you can see, this ALTER is doing two things:
First, it's adding a virtual column,
emailDomain, based on our on-the-fly calculation from above.Second, it's adding a secondary index on that virtual column which means that the on-the-fly calculation will be manifested and stored in the secondary index.
Now, with the new virtual column, we can greatly simplify - and hopefully speed-up - our original SQL query:
SELECT
a.emailDomain,
COUNT( * ) AS userCount
FROM
user_account a
GROUP BY
a.emailDomain
ORDER BY
userCount DESC
LIMIT
10
;
... which gives us the same output as our on-the-fly version:
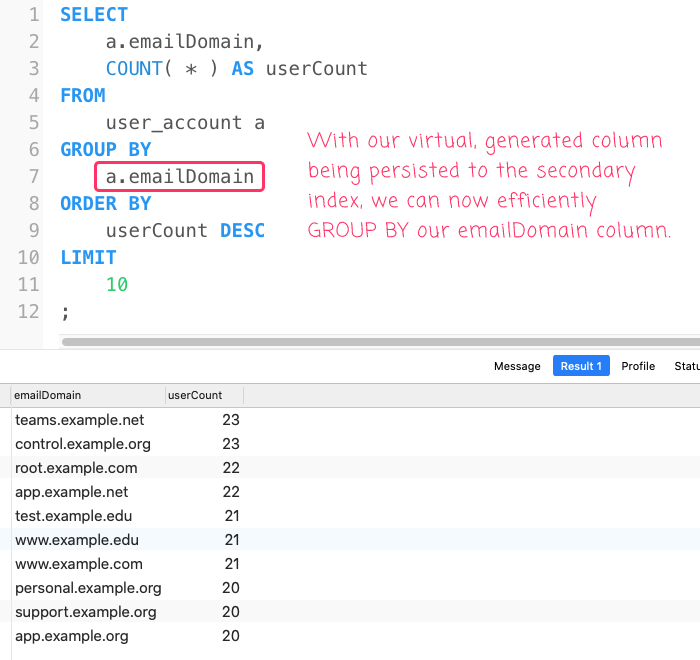
But, hopefully with much better performance!
Not to mention that we can now query for all the user accounts that have a given domain. This is where the difference between the two approaches is doing to be even more magnified! For example, let's try to look up the users that have the email domain, projects.example.net, using the on-the-fly calculation:
NOTE: I have to use the
LIKEclause here for the demo because any attempt to use theSUBSTRING_INDEX()approach and the MySQL query optimizer will end-up using our virtual, generated column. Go optimizer!
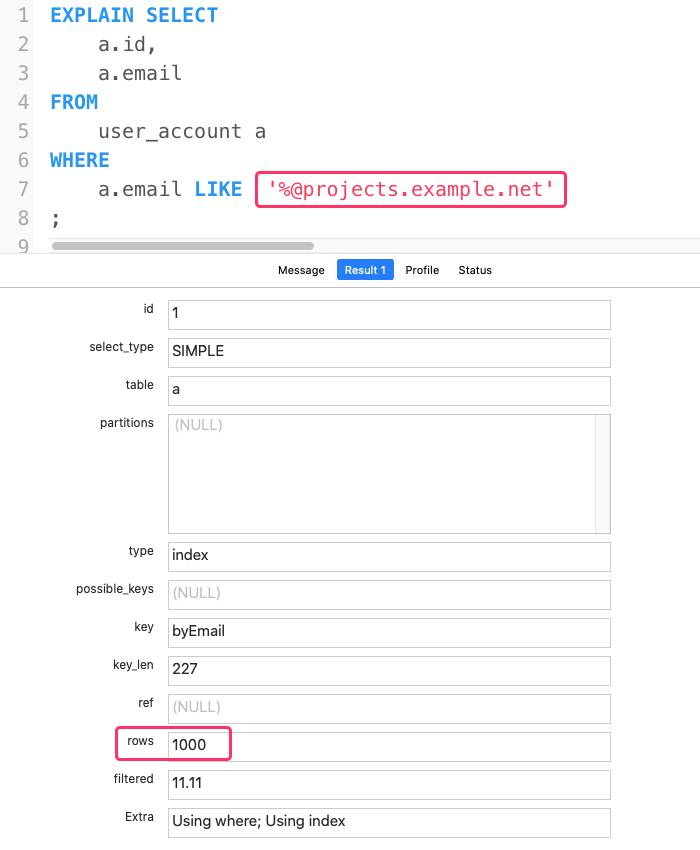
As you can see, the query still has to perform a full table scan - all 1,000 rows - before it returns the 5 matching records.
Let's now compare that to our virtual column:
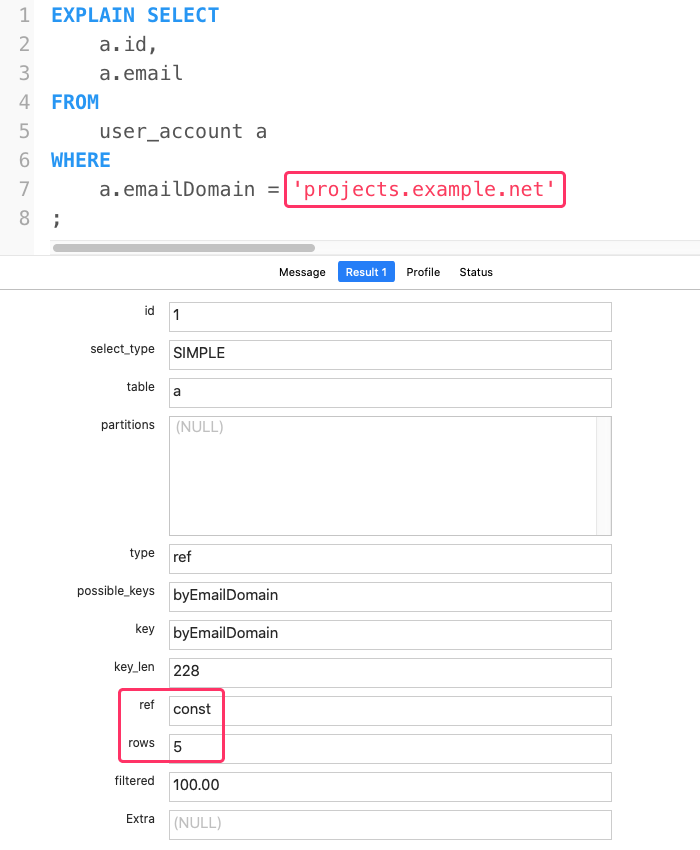
As you can see, this is way better - the MySQL database now looks up a constant 5-rows! No more full table scans!
Virtual columns in MySQL 5.7.32 seem kind of cool. And, when added to a secondary index, it looks like they can really speed things up nicely. Using a virtual column to pluck-out email domains was the first thing that popped into my mind; and to be honest, I am not quite sure what else I might user it for. But, I love having the option for it in my ColdFusion applications.
Want to use code from this post? Check out the license.
Reader Comments
These posts you do about databases... they always show me how I know nothing about DBMS...
Thanks for sharing and making me a little smarter everytime :-)
@Frédéric,
My pleasure, good sir! As we like to say at work, it takes team work to make the dream work :D I'm glad we all get to help each other!
Plus, I love talking about SQL as often as anyone will listen to me :D
I'd be interested to see what your current solution is for INNODB table scans when it comes to using COUNT().... any tips?
@Tom,
Yeah, that's a tough one. It's shocking how slow a
COUNT(*)on a massive table can be. In the past, I'll do one of two things:First, I just try to get the highest
pkeyin the table by sorting the table by thepkeywith aLIMIT:This will run instantly. But, of course, it does not account for every row you've deleted -- only the highest auto-incrementing value. That said, this can give you a really rough estimation of the order of magnitude that might be in the table.
The other thing I might try to do is query the information-schema tables:
This is also instant, but these values can be way off since they are statistics about the table, and not hard values. I think I read somewhere that the row-counts can be as much as 50% inaccurate.
So, there's no easy answer here.
Sometimes, you gotta just crank up the timeout on your SQL connection and run a
COUNT(*)- ha ha.I had no idea a derived virtual column was possible in MySQL. Consider my mind blown! Thanks so much!
@Chris,
:D I think it was added in 5.7.8. But, I've been on 5.6.x for years. So, I'm learning-up on some of the new features I'll be able to use soon when we do a minor bump at work.
@Ben,
Upgrades are hard :D
@Chris,
Yo, for realz! I am 100% sure that 5.7 is the last upgrade we'll see on this database. I doubt anyone will ever dare to upgrade to MySQL 8 :D