
Considering Uniqueness Constraints And Database Abstractions In Application Business Logic
Historically, in my web application development, I've used distributed locking as a synchronization method around my business logic that enforces uniqueness constraints. For example, if I had to allocate a "username" that is meant to be unique within the system, I'd acquire a distributed lock, check to make sure that the given username doesn't exist, create it, and then release the lock. This works, but incurs a cost, increases complexity, and may not necessarily guarantee correctness.
Recently, I've been thinking about moving away from distributed locks and migrating towards idempotent algorithms that lean more heavily on the database implementation in order to enforce uniqueness constraints. My biggest concern about leaning more heavily on the database, however, is that my database implementation may end up leaking into the greater application context. As such, I wanted to take some time and noodle specifically on uniqueness constraints, data persistence, and the layer of abstraction for said persistence.
First, I just wanted to see what kind of support was provided for uniqueness constraints in different databases. I don't have a wide range of database experience - I live mostly in the SQL world; and, I live mostly in the MySQL world as far as relational databases are concerned. As such, I did some Googling to see how uniqueness contraints are implemented in some of the more popular databases.
MySQL / Microsoft SQL Server / PostgreSQL / Percona Server - SQL Variations
All of the SQL variations that I looked at support some sort of secondary index that can impose a uniqueness constraint. Of course, they all support a unique Primary Key index as well; however, I'm concentrating on secondary indices since the primary key doesn't always represent a true business constraint.
MongoDB
MongoDB allows you to specify an index as being unique, which enforces a uniqueness constraint on the indexed fields. Like the SQL variations, you can have multiple unique indices on a single collection.
Redis / Firebase / CouchDB / PouchDB
These databases all seem to provide key-based uniqueness constraints; but, they don't really have a simple way to impose uniqueness constraints on non-keys. That said, there are tutorials (CouchDB example, Firebase example) on how to implement arbitrary uniqueness constraints by, essentially, maintaining your own secondary indices using denormalized data.
Clearly, within the set of databases that I Googled, the SQL and Mongo databases provide the most natural means for arbitrary uniqueness enforcement. Redis, Firebase, and the others have ways to implement such strategies; but, they seem to greatly increase the complexity of the workflow and may even require additional workflows to clean-up the demoralized data as it falls out of sync due to bugs and network partitions.
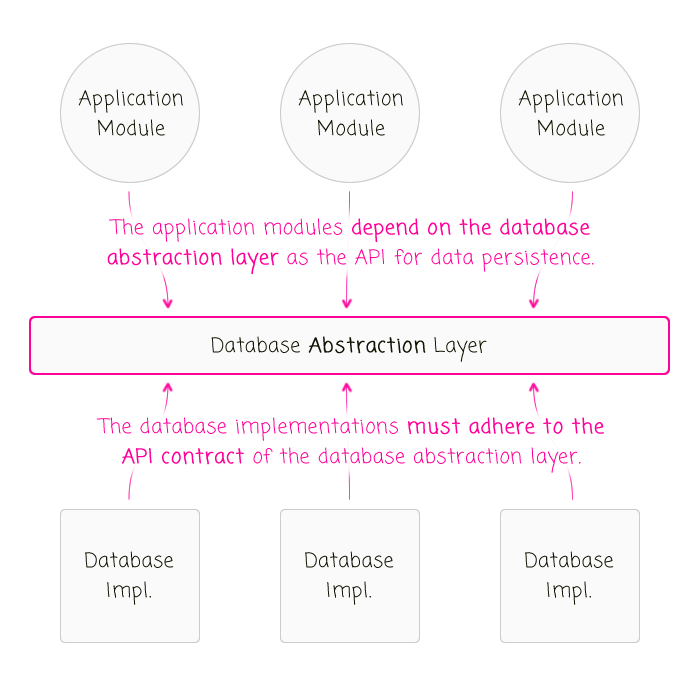
With the various levels of support for uniqueness constraints in different persistence implementations, I wanted to step back and consider the role of the database abstraction layer itself? The incomplete answer is that it allows for different database implementations to be swapped in-and-out of an application. This is certainly true; but, it doesn't sufficiently speak to the role of the abstraction: the database abstraction layer drives the API contract between the application and the underlying persistence mechanism. It is not the responsibility of the abstraction to find a common-ground between various databases. Rather, it is the responsibility of the various databases to adhere to the API of the abstraction layer.
| |
|
|
||
| |
 |
|
||
| |
|
|
This dependency direction is important because it speaks to the interoperability of different persistence mechanisms. Instead of trying to create an API that works for both MySQL and - for example - Firebase, you have to start thinking about whether or not a given persistence mechanism - like Firebase - is actually compatible with the API of your abstraction. This allows us to reconcile an abstraction layer with the basic need to choose the right tool for the job.
Now that we've thought about the role of the abstraction layer, we can circle back to the idea of uniqueness constraints. Initially, I had framed this thought experiment as leaning on the "database" to enforce uniqueness constraints. But, now, I think we can see this was a mistake. Instead, the discussion should be framed as leaning on the "abstraction layer" to enforce uniqueness constraints. That is, that the abstraction layer should, as part of its contract, state that some methods will throw errors if uniqueness constraints are violated. Then, it's up to the data persistence implementations to uphold that contract.
Ultimately, what this means is that if we want to lean on the database to enforce uniqueness constraints, we're not running the risk of creating a leaky abstraction - the database implementation doesn't "leak" into the application. Instead, we're creating a more restrictive abstraction layer API that must propagate down into the various implementations. This may reduce the number of database implementations that can be used with our application; but, it does so in a clean, decoupled way.
Reader Comments
Just a heads up, mongodb unique constraints get tricky with sharded collections.
https://docs.mongodb.com/manual/core/sharding-shard-key/#unique-indexes
@Ben D.,
I can imagine all kinds of things start to get more "interesting" when things are sharded. Unfortunately, sharding is not something I've had to deal with yet... or perhaps that is "fortunately" :)
I was talking to Brad Brewer the other day, and the topic of sharding came up, and he was like, "You don't need sharding." He was feeling pretty strongly that most people will never need sharding if they architect their applications correctly. Not to say that sharding is irrelevant -- only that you should try to put it off for as long as humanly possible (and most applications will never need it in the long run).
Couldn't agree more, the longer you can go without sharding the better. And if you feel like you have to shard there are usually better approaches than having your DB handle it for you, like microservices or logical partitioning of data by customer and so on.