
Reflecting On Data Persistence, Transactions, And Leaky Abstractions
CAUTION: This post is mostly me just thinking out-loud, trying to refine the way I think about application architecture.
I think, perhaps, that I've been using database Transactions all wrong. When I was using nothing but SQL to manage data persisted by a single, monolithic application, it was just transactions all the way down; and it worked fine (when it wasn't locking up the database). But, now that I'm using additional non-SQL technologies and I'm moving more towards a microservices architecture, I'm beginning to see that my mental model for the use of transactions and data-layer abstractions is rather incomplete.
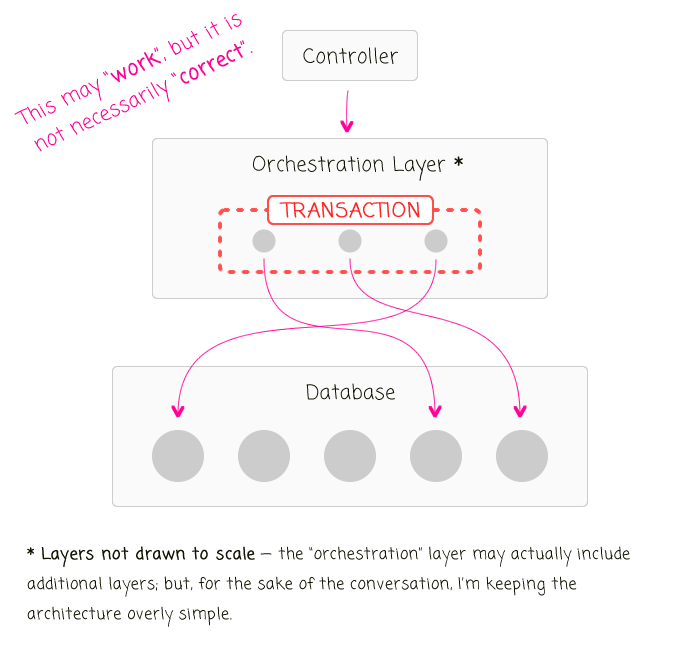
Historically, I've defined my Transactions in the "orchestration layer" of my application, somewhere between the controller and the concrete data persistence implementation. And, since the data was all stored in one place, using SQL, wrapping a transaction around loosely-related entities just "worked", regardless of whether or not it was "correct."
| |
|
|
||
| |
 |
|
||
| |
|
|
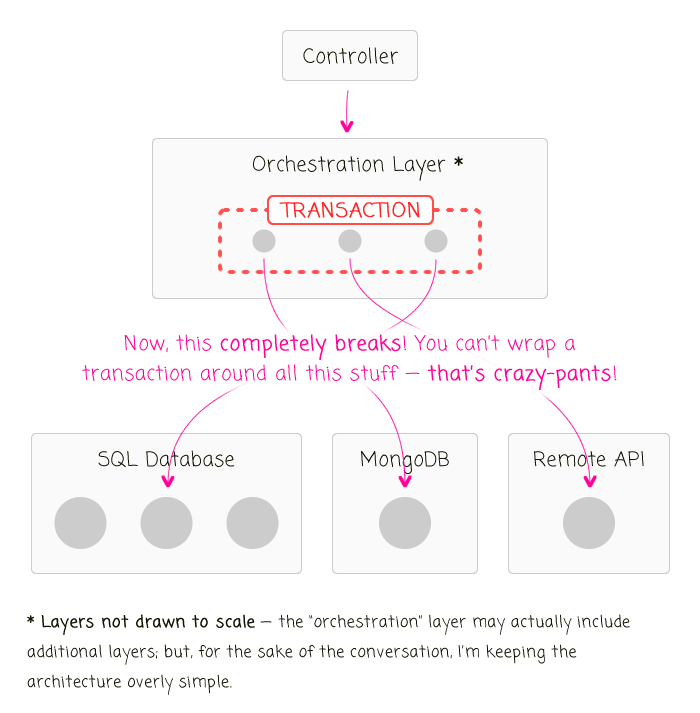
I think this approach was wrong for a variety of reasons. But, the most pressing reason to me is that it lets the data persistence implementation leak out into the outer layers of the application. After all, Transactions only work if the database supports transactions ( and, if the data is all in one local schema). The second you introduce additional data-sources, or use a non-SQL storage mechanism, or move storage to a remote API, this approach completely fails.
| |
|
|
||
| |
 |
|
||
| |
|
|
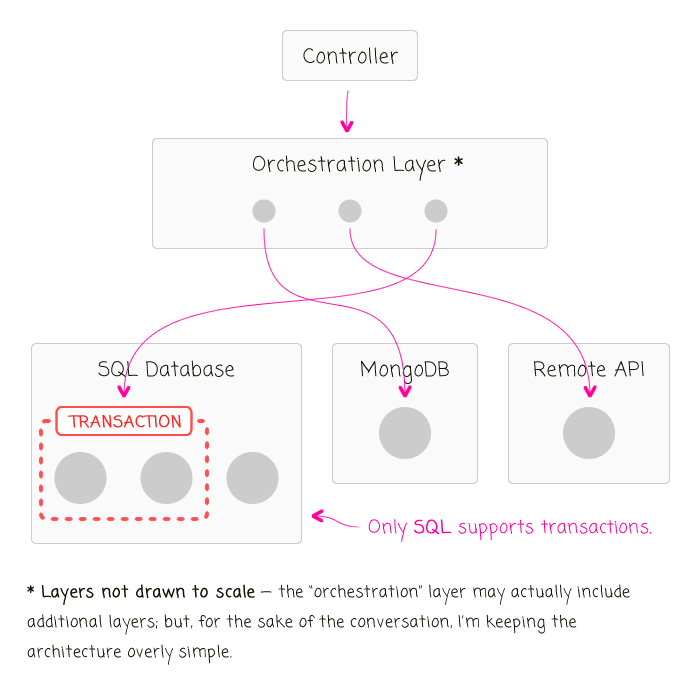
Clearly, it's not good for the concept of transactions to leak out of the data persistence abstraction. But, if the transactions can only be inside the data persistence abstraction, it basically means that a transaction can only wrap around the data being passed into a single persistence method.
| |
|
|
||
| |
 |
|
||
| |
|
|
This constraint drastically changes how I think about what it means for data to "change together". Rather than thinking about all of the data that can change due to a particular workflow, I believe I have to start thinking more about the invariants in the data structures, using transactions only to ensure that the invariants aren't violated.
This starts to minimize the differences between SQL and non-SQL persistence mechanisms. What would be an atomic change in a No-SQL database may become a Transaction in a SQL database (in which the "atomic" change is made across more than one table). This refocuses the level of "changes together" from the workflow down to the entity.
Half of me thinks that this change in outlook actually negates many of the benefits of using SQL in the first place. But, I think much of that fear is based on the understanding that this puts more of the burden around data reconciliation into my code, rather than into the database. Which feels scary; but, I think it's actually much more scalable and transferable in the long-term.
Programming is hard. I'm happy it's Friday.
Reader Comments
Check out the book data intensive applications by Martin Kleppmann. He has a great chapter in that book about transactions also some solutions to some of the themes in your article.
@Sandy,
Ha ha, I actually have that opened up in a browser tab (since it was announced some weeks ago). After trying to tackle High Performance MySQL (from the Percona team), though, I'm hesitant to dive into another 600+ page book :P
Sounds like you would recommend it? How are you reading it? Cover to cover? Or, looking for bits that are interesting. I was hoping that the book would also cover things like lock-free code (leaning on constraints in the database as opposed to distributed locking).
It has a lot of good and interesting stuff. I have not been reading it cover to cover but picking out chapters here and there. I have already consumed and used some of the streaming stuff and other Microservices ideas, so I wasn't starting from ground zero. But the transaction stuff was enlightening because many of the things that are talked about in that chapter I have experienced first hand in trying to get good performance out of SQL databases. Things like write and read skew, race conditions, issues with MVCC. That at high transaction and concurrency levels to get good performance out of your SQL database, transactions can give you a false sense of security. here is a talk he gave https://martin.kleppmann.com/2015/09/26/transactions-at-strange-loop.html about some of the ideas in the book.
@Sandy,
Thanks for the link, I'll check it out. I finally committed to the book, purchased it last night. Now, time to dive in and start consuming. The rest of our "Data team" is currently reading it, so I'll have to catch up to them (I'm an honorary data-team member for historic reasons).
@All,
While not necessary directly on point, I was just doing some more noodling on database abstractions, in particular around the enforcement of uniqueness constraints:
www.bennadel.com/blog/3321-considering-uniqueness-constraints-and-database-abstractions-in-application-business-logic.htm
... it kind of forced me to think more clearly about how I see the role of the abstraction layer (ie, as the _thing_ providing the uniqueness constraint enforcement). But, I am not sure if it has changed my mind on the location of Transactions.... but it could.