
Using fetch(), AbortSignal, And setTimeout() To Apply Retry Mechanics In JavaScript
After learning to abort fetch() requests with the AbortController, I started to wonder what else I could abort. And when I realized that I could abort a setTimeout() timer with AbortContoller, I understood that I now had all the ingredients that I needed in order to create retry mechanics in my fetch()-based API client. For my first implementation, all I'm going to do is take my poor man's exponential backoff logic in ColdFusion and apply it to JavaScript using async and await.
The first question I had to answer was where to put the retry logic? My API client only has one public method at this time:
async makeRequest( config )
So, it would be a reasonable thought to simply shoe-horn the retry logic right into the existing makeRequest() method with some sort of {retry:true} option. However, I believe such an implementation would be a mistake - it would commingle two related but completely separate responsibilities:
- Making HTTP requests.
- Catching errors, inspecting them, and retrying requests.
If we tried to cram both of these responsibilities into the same method, that method would become much more complex than it is today. And, as the needs of the retry mechanics evolved over time, this method would continue to become even more complex in the future.
In much the same way that we separate our asynchronous thread logic from our business logic in ColdFusion, I think we should make the "retryable request" a completely separate method that does nothing but handle the retry logic and then defers to the existing makeRequest() method for the actual HTTP transport. This way, the makeRequest() method can remain unchanged even as we continue to evolve and tweak our retry logic.
Essentially, we're going to separate the parts of the code that change at different rates.
What I ended-up with was an API client that has two public methods that - at least for now - have the same signature:
async makeRequest( config )async makeRequestWithRetry( config )
The makeRequestWithRetry() method utilizes the makeRequest() method under the hood; but, it layers the retry logic on top of it. By separating this into two different methods, not only do we keep each method simple and easy to maintain, we end-up pushing the decision about retries up to the calling-context. The calling-context has more high-level information about why the API request is being made in the first place; and, will likely have a better sense of when it is safe to apply retry logic idempotently.
The retry logic itself has several different requirements:
We need to have some sort of backoff so that we don't hammer the remote system; and, so that the remote system (or the network between the client and the remote system) has time to recover.
We need to differentiate a retryable error from a non-retryable error.
We need a way to "sleep" the algorithm so that our backoff actually, well, backs-off making HTTP requests.
For the first requirement, I'm just going to use a hard-coded collection of millisecond-duration values that we'll supply to a setTimeout() call. I'm sure there's loads of thinking and maths that could go into this; but, I'm not smart enough to get that kind of logic in my head.
For the second requirement, I'm going to use the HTTP status code of the failed response. Some status codes, like 0 and 500, mean that a retry might help where as other status codes, like 422 and 404, mean that a subsequent request will yield the same exact result.
And, for the third requirement, I'm going to take the same AbortSignal that we're passing to fetch() and use it to abort the setTimeout() mentioned above.
Let's look at the lower-level methods first so that we see how we can take simple ideas and wire them together to create complex algorithms. First, let's look at our error inspection. To understand how this works, we have to remember (from my previous post) that part of why I recommend creating an API Client in the first place is so that you can imbue it with your strong opinions. And, one of my strong opinions is that the error emitted from an API client has a guaranteed shape. Currently, at a minimum, my API client errors have the following properties:
data.typedata.messagestatus.codestatus.textstatus.isAbort
We're going to be using the error.status object to determine if the request is retryable:
export class ApiClient {
/**
* I try to determine if the given request-error object indicates that the original
* request can be retried.
*/
isRetryableError( error ) {
// If the error was triggered by an explicit Abort, we don't want to retry it -
// it was terminated early on purpose by the calling context.
if ( error.status.isAbort ) {
return( false );
}
// Short-hand for the HTTP status code of the error response.
var code = error.status.code;
return(
( code === -1 ) || // Various network failures.
( code === 0 ) || // Various network failures.
( code === 408 ) || // Request timeout.
( code === 429 ) || // Too many requests (ie, rate limiting).
( code >= 500 ) // Basically all unexpected server errors.
);
}
}
Obviously, we don't want to retry any status code in the 2xx-range - it was a success request. And, most of the 4xx-range is probably not retryable. But, "Request Timeout" and "Rate Limiting" might work on a subsequent request, so we'll include those in our logic. There's no reason to think that a 5xx response can be fixed on a retry; but, there's no reason to not think that a 5xx response can be fixed on a retry. So, we'll include it as well.
To be clear, this is not a perfect approach - it's just a best initial guess as to what might be helpful. We can continue to evolve this over time.
ASIDE: You might be wondering why I don't inspect the HTTP method? For example, it might make sense to exclude
POSTandPUTrequests from retry eligibility. Remember, however, that I'm pushing the retry decision, in part, up to the calling-context. As such, it's up to the calling-context to decide if it should be using themakeRequest()ormakeRequestWithRetry()method. As such, that decision has already been made - there's no point to then also worrying about what HTTP verb we're using.That said, see the Epilogue on Inverting the Make-Request Methods for further discussion.
Next, let's look at our ability to sleep the retry algorithm so that we back-off the HTTP calls. Obviously, JavaScript has no native sleep() method; but, it does have a setTimeout() method. setTimeout() doesn't sleep the request; but, we can use it to power a Promise that can "block and wait" if used in conjunction with the await directive.
To this end, I've created a blockAndWait() method that take a millisecond duration and an AbortSignal and returns a Promise that resolves after the given duration. The AbortSignal, in this case, is the same AbortSignal that is passed to the fetch() call such that if the calling context aborts the request, it will implicitly abort any pending retry logic as well.
NOTE: The
blockAndWait()method is not anasyncmethod because it doesn't need to be - it's already returning aPromise. Making itasyncwouldn't make any sense.
export class ApiClient {
/**
* I return a Promise that is resolved after the given timeout. The internal timer can
* be canceled with an optional AbortSignal. If the internal timer is aborted, the
* returned Promise will never resolve.
*/
blockAndWait( durationInMilliseconds, signal ) {
var promise = new Promise(
( resolve ) => {
// When the calling context triggers an abort, we need to listen for it so
// that we can turn around and clear the internal timer.
// --
// NOTE: We're creating a proxy callback for our resolve function in order
// to remove this event-listener once the timer executes. This way, our
// event-handler never gets invoked if there's nothing for it to actually
// do. Also note that the "abort" event will only ever get emitted once,
// regardless of how many times the calling context tries to invoke
// .abort() on its AbortController.
signal?.addEventListener( "abort", handleAbort );
// Setup our internal timer that we can clear-on-abort.
var internalTimer = setTimeout( internalResolve, durationInMilliseconds );
// -- Internal methods. -- //
function internalResolve() {
signal?.removeEventListener( "abort", handleAbort );
resolve( durationInMilliseconds );
}
function handleAbort() {
clearTimeout( internalTimer );
}
}
);
return( promise );
}
}
Now that we've seen the low-level methods, let's look at how these can be combined to create the retry logic that wraps the HTTP request:
export class ApiClient {
/**
* I make the API request with the given configuration options. If the request rejects
* with a retryable error, an "exponential" back-off will be applied to retry the
* request several times before giving up.
*
* GUARANTEE: This method has all the same guarantees as the makeRequest() method - it
* is nothing more than a proxy in front for the underlying result and error values.
*/
async makeRequestWithRetry( config ) {
// Rather than relying on the maths to do back-off calculations, this collection
// provides an explicit set of back-off values (in milliseconds). This collection
// also doubles as the number of attempts that we should execute against the
// underlying makeRequest() method.
// --
// NOTE: Some randomness will be applied to these values as execution time.
var backoffDurations = [
200,
700,
1000,
2000,
4000,
8000,
16000,
0 // Indicates that the last timeout should be recorded as an error.
];
// CAUTION: We must use a FOR-OF loop (not a .forEach() loop) so that we can
// leverage await inside the loop and make the overall workflow block-and-wait.
for ( var retryDelay of backoffDurations ) {
try {
return( await this.makeRequest( config ) );
} catch ( error ) {
// NOTE: In some cases, we would want to inspect the HTTP METHOD in order
// to see if it is retryable (and perhaps only allow GET requests to be
// retried). However, since this API Client has a separate method designed
// specifically for retries, we are going to assume that the calling
// context understands when it IS OK and IS NOT OK to retry. Therefore, we
// are only going to look at the returned error as a means to to determine
// if retry is the best next step.
if ( ! retryDelay || ! this.isRetryableError( error ) ) {
throw( error );
}
console.warn( `API request failed, retrying in ${ retryDelay }ms.` );
await this.blockAndWait( this.applyJitter( retryDelay ), config.signal );
}
}
}
}
First, can we just take a moment and acknowledge how freakin' bad-ass async/await is in JavaScript?! Remember, this code is all completely asynchronous. But, by using async/await, it reads exactly like its synchronous, blocking, ColdFusion counterpart. Just amazing!
Hopefully, when you look at this, you can see that it was a wise choice to separate out the HTTP request logic from the retry logic. This method isn't crazy complicated; but, it's also not that simple. And, by separating it out from the rest of the control-flow, we - I hope - have managed to keep it maintainable.
Basically, what this code is doing is iterating over the backoffDurations collection and using each value as the "sleep" call after each retrying request. This way, the "sleep" becomes increasingly long (it backs-off) after each failure.
Now, if we open up the Network activity in Chrome Dev Tools, turn off the network, and then try to make an API request, we can see it failing and retrying with an increasingly long delay:
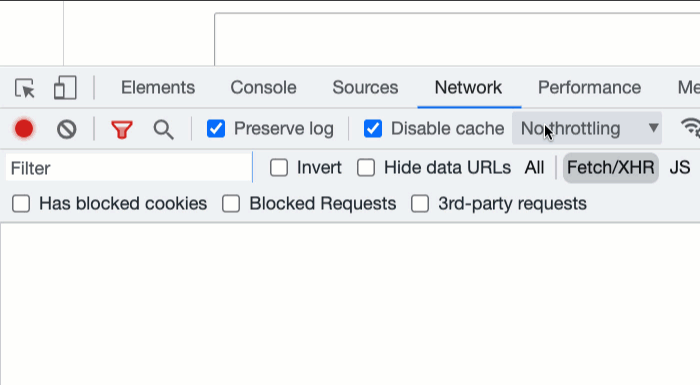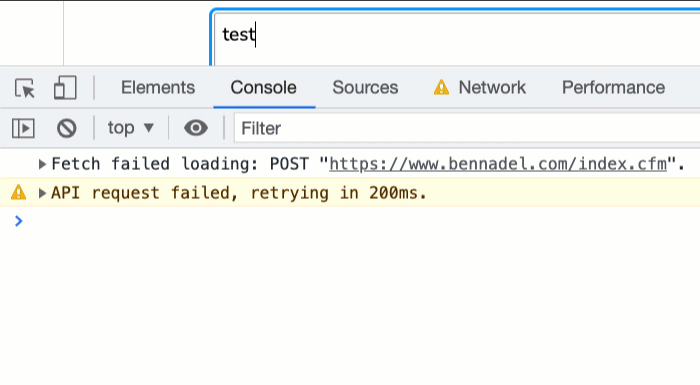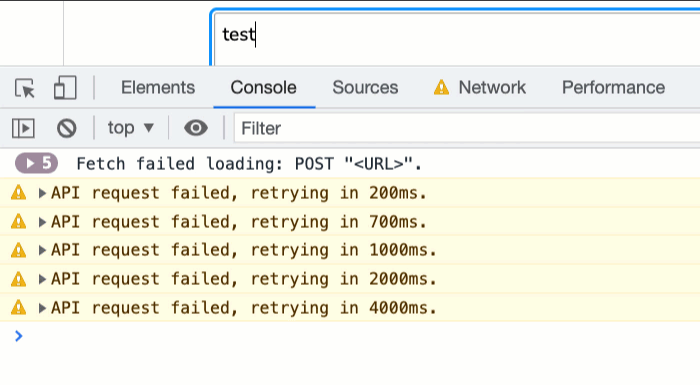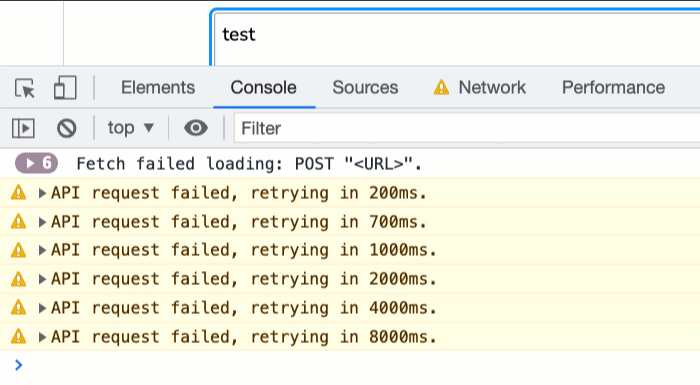
This approach isn't perfect; and, it won't necessarily apply to all situations; but, at least now I have some retry logic in my API client that I can begin to evolve. And, since the retry logic is a separate method on the ApiClient class, it means that I can slowly roll this logic out to different places within my blog - yet another "happy accident" of the separation of concerns.
Epilogue on Inverting the Make-Request Methods
In my approach to this API client, I've made the "base method" the one without the retry. Meaning, a calling-context has to explicitly call the new method in order to add retry mechanics to their API request. However, there's no reason you couldn't invert this relationship if it made more sense for your application. Meaning, your public methods could look like this:
async makeRequest( config )async makeRequestWithoutRetry( config )
Here, the "base method" is the one with the retry. Meaning, all API calls would have retry logic baked-in unless the calling-context explicitly opted-out of the retry by calling the other method. In such an approach, you might want to add some logic that inspects the HTTP method/verb as part of the isRetryableError() implementation.
This is the same approach, just a change in precedence.
Epilogue on Current ApiClass Implementation
In order to make this article more consumable, I used a number of snippets to illustrate the discussion. But, sometimes it's nice to see the whole thing. So, here is my current highly opinionated API client:
// Regular expression patterns for testing content-type response headers.
var RE_CONTENT_TYPE_JSON = new RegExp( "^application/(x-)?json", "i" );
var RE_CONTENT_TYPE_TEXT = new RegExp( "^text/", "i" );
// Static strings.
var UNEXPECTED_ERROR_MESSAGE = "An unexpected error occurred while processing your request.";
export class ApiClient {
/**
* I initialize the API client.
*/
constructor() {
// Nothing to do at this time. In the future, I could add things like base
// headers and other configuration defaults. But, I don't need any of that stuff
// at this time.
}
// ---
// PUBLIC METHODS.
// ---
/**
* I make the API request with the given configuration options.
*
* GUARANTEE: All errors produced by this method will have consistent structure, even
* if they are low-level networking errors. At a minimum, every Promise rejection will
* have the following properties:
*
* - data.type
* - data.message
* - status.code
* - status.text
* - status.isAbort
*/
async makeRequest( config ) {
// CAUTION: We want the entire contents of this method to be inside the try/catch
// so that we can guarantee that all errors occurring during this workflow will
// be caught and transformed into a consistent structure. NOTHING HERE SHOULD
// throw an error - but, bugs happen and people pass-in malformed parameters and
// I want the error-handling guarantees in place.
try {
// Extract options, with defaults, from config.
var contentType = ( config.contentType || null );
var headers = ( config.headers || Object.create( null ) );
var method = ( config.method || null );
var url = ( config.url || "" );
var params = ( config.params || Object.create( null ) );
var form = ( config.form || null );
var json = ( config.json || null );
var body = ( config.body || null );
var signal = ( config.signal || null );
// The fetch* variables are the values that we'll actually use to generate
// the fetch() call. We're going to assign these based on the configuration
// data that was passed-in.
var fetchHeaders = this.buildHeaders( headers );
var fetchMethod = null;
var fetchUrl = this.mergeParamsIntoUrl( url, params );
var fetchBody = null;
var fetchSignal = signal;
if ( form ) {
// NOTE: For form data posts, we want the browser to build the Content-
// Type for us so that it puts in both the "multipart/form-data" plus the
// correct, auto-generated field delimiter.
delete( fetchHeaders[ "content-type" ] );
// ColdFusion will only parse the form data if the method is POST.
fetchMethod = "post";
fetchBody = this.buildFormData( form );
} else if ( json ) {
fetchHeaders[ "content-type" ] = ( contentType || "application/x-json" );
fetchMethod = ( method || "post" );
fetchBody = JSON.stringify( json );
} else if ( body ) {
fetchHeaders[ "content-type" ] = ( contentType || "application/octet-stream" );
fetchMethod = ( method || "post" );
fetchBody = body;
} else {
fetchMethod = ( method || "get" );
}
var fetchRequest = new window.Request(
fetchUrl,
{
headers: fetchHeaders,
method: fetchMethod,
body: fetchBody,
signal: fetchSignal
}
);
var fetchResponse = await window.fetch( fetchRequest );
var data = await this.unwrapResponseData( fetchResponse );
if ( fetchResponse.ok ) {
return( data );
}
// The request came back with a non-2xx status code; but may still contain an
// error structure that is defined by our business domain.
return( Promise.reject( this.normalizeError( data, fetchRequest, fetchResponse ) ) );
} catch ( error ) {
// The request failed in a critical way; the content of this error will be
// entirely unpredictable.
return( Promise.reject( this.normalizeTransportError( error ) ) );
}
}
/**
* I make the API request with the given configuration options. If the request rejects
* with a retryable error, an "exponential" back-off will be applied to retry the
* request several times before giving up.
*
* GUARANTEE: This method has all the same guarantees as the makeRequest() method - it
* is nothing more than a proxy in front for the underlying result and error values.
*/
async makeRequestWithRetry( config ) {
// Rather than relying on the maths to do back-off calculations, this collection
// provides an explicit set of back-off values (in milliseconds). This collection
// also doubles as the number of attempts that we should execute against the
// underlying makeRequest() method.
// --
// NOTE: Some randomness will be applied to these values as execution time.
var backoffDurations = [
200,
700,
1000,
2000,
4000,
8000,
16000,
0 // Indicates that the last timeout should be recorded as an error.
];
// CAUTION: We must use a FOR-OF loop (not a .forEach() loop) so that we can
// leverage await inside the loop and make the overall workflow block-and-wait.
for ( var retryDelay of backoffDurations ) {
try {
return( await this.makeRequest( config ) );
} catch ( error ) {
// NOTE: In some cases, we would want to inspect the HTTP METHOD in order
// to see if it is retryable (and perhaps only allow GET requests to be
// retried). However, since this API Client has a separate method designed
// specifically for retries, we are going to assume that the calling
// context understands when it IS OK and IS NOT OK to retry. Therefore, we
// are only going to look at the returned error as a means to to determine
// if retry is the best next step.
if ( ! retryDelay || ! this.isRetryableError( error ) ) {
throw( error );
}
console.warn( `API request failed, retrying in ${ retryDelay }ms.` );
await this.blockAndWait( this.applyJitter( retryDelay ), config.signal );
}
}
}
// ---
// PRIVATE METHODS.
// ---
/**
* I apply a +/- 20% offset to the current value (a small attempt to prevent the
* stampeding herd problem).
*/
applyJitter( value ) {
// Generate a +/- 20% delta from the original value.
var percentJitter = ( ( 20 - Math.floor( Math.random() * 40 ) ) / 100 );
var jitter = ( value * percentJitter );
return( Math.floor( value + jitter ) );
}
/**
* I return a Promise that is resolved after the given timeout. The internal timer can
* be canceled with an optional AbortSignal. If the internal timer is aborted, the
* returned Promise will never resolve.
*/
blockAndWait( durationInMilliseconds, signal ) {
var promise = new Promise(
( resolve ) => {
// When the calling context triggers an abort, we need to listen for it so
// that we can turn around and clear the internal timer.
// --
// NOTE: We're creating a proxy callback for our resolve function in order
// to remove this event-listener once the timer executes. This way, our
// event-handler never gets invoked if there's nothing for it to actually
// do. Also note that the "abort" event will only ever get emitted once,
// regardless of how many times the calling context tries to invoke
// .abort() on its AbortController.
signal?.addEventListener( "abort", handleAbort );
// Setup our internal timer that we can clear-on-abort.
var internalTimer = setTimeout( internalResolve, durationInMilliseconds );
// -- Internal methods. -- //
function internalResolve() {
signal?.removeEventListener( "abort", handleAbort );
resolve( durationInMilliseconds );
}
function handleAbort() {
clearTimeout( internalTimer );
}
}
);
return( promise );
}
/**
* I build a FormData instance from the given object.
*
* NOTE: At this time, only simple values (ie, no files) are supported.
*/
buildFormData( formFields ) {
var formData = new FormData();
Object.entries( formFields ).forEach(
( [ key, value ] ) => {
formData.append( key, value );
}
);
return( formData );
}
/**
* I transform the collection of HTTP headers into a like collection wherein the names
* of the headers have been lower-cased. This way, if we need to manipulate the
* collection prior to transport, we'll know what key-casing to use.
*/
buildHeaders( headers ) {
var lowercaseHeaders = Object.create( null );
Object.entries( headers ).forEach(
( [ key, value ] ) => {
lowercaseHeaders[ key.toLowerCase() ] = value;
}
);
return( lowercaseHeaders );
}
/**
* I build a query string (less the leading "?") from the given params.
*
* NOTE: At this time, there is no special handling of array-based values.
*/
buildQueryString( params ) {
var queryString = Object.entries( params )
.map(
( [ key, value ] ) => {
if ( value === true ) {
return( encodeURIComponent( key ) );
}
return( encodeURIComponent( key ) + "=" + encodeURIComponent( value ) );
}
)
.join( "&" )
;
return( queryString );
}
/**
* I try to determine if the given request-error object indicates that the original
* request can be retried.
*/
isRetryableError( error ) {
// If the error was triggered by an explicit Abort, we don't want to retry it -
// it was terminated early on purpose by the calling context.
if ( error.status.isAbort ) {
return( false );
}
// Short-hand for the HTTP status code of the error response.
var code = error.status.code;
return(
( code === -1 ) || // Various network failures.
( code === 0 ) || // Various network failures.
( code === 408 ) || // Request timeout.
( code === 429 ) || // Too many requests (ie, rate limiting).
( code >= 500 ) // Basically all unexpected server errors.
);
}
/**
* I merged the given params into the given URL. This is done by parsing the URL,
* extracting the URL-based params, merging them with the given params, and then
* rebuilding the URL with the merged params.
*
* NOTE: The given params take precedence in the case of a name-conflict.
*/
mergeParamsIntoUrl( url, params ) {
// Split on fragment segments.
var hashParts = url.split( "#", 2 );
var preHash = hashParts[ 0 ];
var fragment = ( hashParts[ 1 ] || "" );
// Split on search segments.
var urlParts = preHash.split( "?", 2 );
var scriptName = urlParts[ 0 ];
// When merging the url-params and the additional params, the additional params
// take precedence (meaning, they will overwrite url-based params).
var urlParams = this.parseQueryString( urlParts[ 1 ] || "" );
var mergedParams = Object.assign( urlParams, params );
var queryString = this.buildQueryString( mergedParams );
var results = [ scriptName ];
if ( queryString ) {
results.push( "?", queryString );
}
if ( fragment ) {
results.push( "#", fragment );
}
return( results.join( "" ) );
}
/**
* At a minimum, we want every error to have the following properties:
*
* - data.type
* - data.message
* - status.code
* - status.text
* - status.isAbort
*
* These are the keys that the calling context will depend on; and, are the minimum
* keys that the server is expected to return when it throws domain errors.
*/
normalizeError( data, fetchRequest, fetchResponse ) {
var error = {
data: {
type: "ServerError",
message: UNEXPECTED_ERROR_MESSAGE
},
status: {
code: fetchResponse.status,
text: fetchResponse.statusText,
isAbort: false
},
// The following data is being provided to make debugging AJAX errors easier.
request: fetchRequest,
response: fetchResponse
};
// If the error data is an Object (which it should be if the server responded
// with a domain-based error), then it should have "type" and "message"
// properties within it. That said, just because this isn't a transport error, it
// doesn't mean that this error is actually being returned by our application.
if (
( typeof( data?.type ) === "string" ) &&
( typeof( data?.message ) === "string" )
) {
Object.assign( error.data, data );
// If the error data has any other shape, it means that an unexpected error
// occurred on the server (or somewhere in transit). Let's pass that raw error
// through as the rootCause, using the default error structure.
} else {
error.data.rootCause = data;
}
return( error );
}
/**
* If our request never makes it to the server (or the round-trip is interrupted
* somehow), we still want the error response to have a consistent structure with the
* application errors returned by the server. At a minimum, we want every error to
* have the following properties:
*
* - data.type
* - data.message
* - status.code
* - status.text
* - status.isAbort
*/
normalizeTransportError( transportError ) {
return({
data: {
type: "TransportError",
message: UNEXPECTED_ERROR_MESSAGE,
rootCause: transportError
},
status: {
code: 0,
text: "Unknown",
isAbort: ( transportError.name === "AbortError" )
}
});
}
/**
* I parse the given query string into an object.
*
* NOTE: This method assumes that the leading "?" has already been removed.
*/
parseQueryString( queryString ) {
var params = Object.create( null );
for ( var pair of queryString.split( "&" ) ) {
var parts = pair.split( "=", 2 );
var key = decodeURIComponent( parts[ 0 ] );
// CAUTION: If there is no value in the query string pair, we want to use a
// literal TRUE value since this literal value will be treated differently
// when subsequently serializing the params back into a query string.
var value = ( parts[ 1 ] )
? decodeURIComponent( parts[ 1 ] )
: true
;
params[ key ] = value;
}
return( params );
}
/**
* I unwrap the response payload from the given response based on the reported
* content-type.
*/
async unwrapResponseData( response ) {
var contentType = response.headers.has( "content-type" )
? response.headers.get( "content-type" )
: ""
;
if ( RE_CONTENT_TYPE_JSON.test( contentType ) ) {
return( response.json() );
} else if ( RE_CONTENT_TYPE_TEXT.test( contentType ) ) {
return( response.text() );
} else {
return( response.blob() );
}
}
}
Party on with your bad self!
Want to use code from this post? Check out the license.
Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →