
Using JSoup To Report Untrusted HTML Elements And Attributes In ColdFusion
Yesterday, I took my first look at using JSoup to sanitize untrusted HTML in ColdFusion. Historically, I've been using the OWASP AntiSamy project to do the same thing; and while the JSoup approach feels more flexible is easier to consume, it's missing one important feature that AntiSamy had: an ability to report on which aspects of the untrusted DOM (Document Object Model) were being removed during the sanitization process. As such, I wanted to look at how I can use JSoup to report the untrusted HTML elements and attributes that were being removed in my ColdFusion processing.
To be fair, JSoup's Cleaner class does expose two methods for testing the validity of a given document: isValid(DOM) and isValidBodyHtml(html). But, both of these methods just run the sanitization process under the hood and return a Boolean value indicating whether or not any parts of the DOM were dropped during the conversion.
On this blog, I accept untrusted HTML from my users in the form of comments. And, sometimes, users try to submit "malicious code" unknowingly—usually forgetting to wrap a code snippet in back-ticks (this is the Markdown way). Instead of rejecting their comments as part of a black-boxed workflow, I need to tell them why I'm rejecting their comment so that they have a chance to go in and fix the issues.
Which means, a Boolean true/false validity check is insufficient. Instead, I have to determine which elements and which attributes are causing validation to fail. And, I have to report some of that back to the user.
JSoup's Safelist class exposes two methods that we need for this process: isSafeTag() and isSafeAttribute(). In fact, these are the methods that JSoup's Cleaner class is using during its deep-copy algorithm. Ultimately, we're recreating a light-weight version of what the Cleaner class is doing; only, instead of creating a sanitized copy of the DOM, we're just recording the dropped elements and attributes.
Internally, the Cleaner class is using a NodeVisitor pattern because it's performing more complicated work. For the purposes of reporting, I'm just going to use the .getAllElements() method and the loop over every element in the DOM.
To see this in action, let's first define our untrusted HTML input. It's going to include unsafe protocols (javascript: and mailto:), unsafe attributes (onclick and target), and an unsafe element (<malicious>):
<p>
Hey, check out my <a href="javascript:void(0)">awesome site</a>!
</p>
<p>
It's <strong onclick="alert(1)" class="highlite">so <a>great</a>!</strong>
</p>
<p>
<malicious>This is fun, too</malicious>; you should <em>try it</em>.
</p>
<p>
Cheers, <a href="https://www.bennadel.com" target="_blank">Ben Nadel</a>
</p>
<p>
Contact me at <a href="mailto:ben@bennadel.com">ben@bennadel.com</a>.
</p>
<script>
alert(1);
</script>
<pre class="language-js">
<code class="so-cool">var x = prompt( "Get to the choppa!" );</code>
</pre>
As we iterate over the DOM and compare it to the Safelist configuration, we're either going to remove elements or attributes. I'm going to differentiate between these two options with a type property on my recorded values. For dropped tags, the structure will be:
type: "tag"tagName: {name}
For dropped attributes, the structure will be:
type: "attribute"tagName: {name}attributeName: {name}attributeValue: {value}
It's helpful for me to differentiate between the two types of issues because I may only want to report dropped tags to the user; whereas, I may allow dropped attributes to happen quietly in the background. When JSoup sanitizes a document, it's not throwing errors, it's just dropping constructs that aren't explicitly allow-listed. It's up to me to determine if a given omission is worth reporting.
In the following ColdFusion / Lucee CFML code, I'm defining the Safelist at the top and then performing my manual node traversal below, recording unsafe elements and attributes along the way:
<cfscript>
// Define our allow-listed markup.
safelist = create( "org.jsoup.safety.Safelist" )
.init()
// Basic formatting.
.addTags([ "strong", "b", "em", "i", "u" ])
// Basic structuring.
.addTags([ "p", "blockquote", "ul", "ol", "li", "br" ])
// Code blocks.
.addTags([ "pre", "code" ])
.addAttributes( "pre", [ "class" ] )
.addAttributes( "code", [ "class" ] )
// Links.
.addTags([ "a" ])
.addAttributes( "a", [ "href" ] )
.addProtocols( "a", "href", [ "http", "https" ] )
.addEnforcedAttribute( "a", "rel", "noopener noreferrer" )
;
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
untrustedDom = create( "org.jsoup.Jsoup" )
.parseBodyFragment( fileRead( "./input.html", "utf-8" ) )
;
// While the Cleaner class has the ability to return us a clean, sanitized document,
// it doesn't expose a native way to report on aspects of the sanitization process. On
// my blog, where I allow users to enter untrusted comments, I need a way to tell them
// WHY their comments are being rejected (for those users that are making honest
// mistakes like forgetting to wrap their code samples in back-ticks). As such, I want
// to reproduce some of the Cleaner class' internal workflow so that I can expose some
// relevant information to my readers.
unsafe = [
tags: [],
attributes: []
];
// The internal Cleaner algorithm uses a NodeVisitor pattern since it's doing more
// complicated construction. But, we can do roughly get the same access to the DOM by
// simply grabbing all the elements in the body.
for ( element in untrustedDom.body().getAllElements() ) {
tagName = element.normalName();
// We're starting at the body element because that's what the .body() method gives
// us. But the body won't be part of the content that we're actually validating -
// it's just the natural container of the parsed content. Skip it.
if ( tagName == "body" ) {
continue;
}
// Validate the tag name against the Safelist.
if ( ! safelist.isSafeTag( tagName ) ) {
unsafe.tags.append([
type: "tag",
tagName: tagName
]);
// If we're dropping this whole element, there's no need to also examine its
// attributes. We can move onto the next element.
continue;
}
// Validate the attributes against the Safelist.
for ( attribute in element.attributes().asList() ) {
if ( ! safelist.isSafeAttribute( tagName, element, attribute ) ) {
unsafe.attributes.append([
type: "attribute",
tagName: tagName,
attributeName: attribute.getKey(),
attributeValue: attribute.getValue()
]);
}
}
}
dump(
var = unsafe,
label = "Unsafe Elements and Attributes"
);
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I create an instance of the given JSoup package class.
*/
private any function create( required string className ) {
var jarPaths = [ "./jsoup-1.18.1.jar" ];
return createObject( "java", className, jarPaths );
}
</cfscript>
As you can see, I'm creating an unsafe structure with two properties, tags and attributes. This will further help me differentiate between issues that I want to report back to the reader; and issues that I want to manage quietly behind the scenes.
If we run this Lucee CFML code, we get the following output:
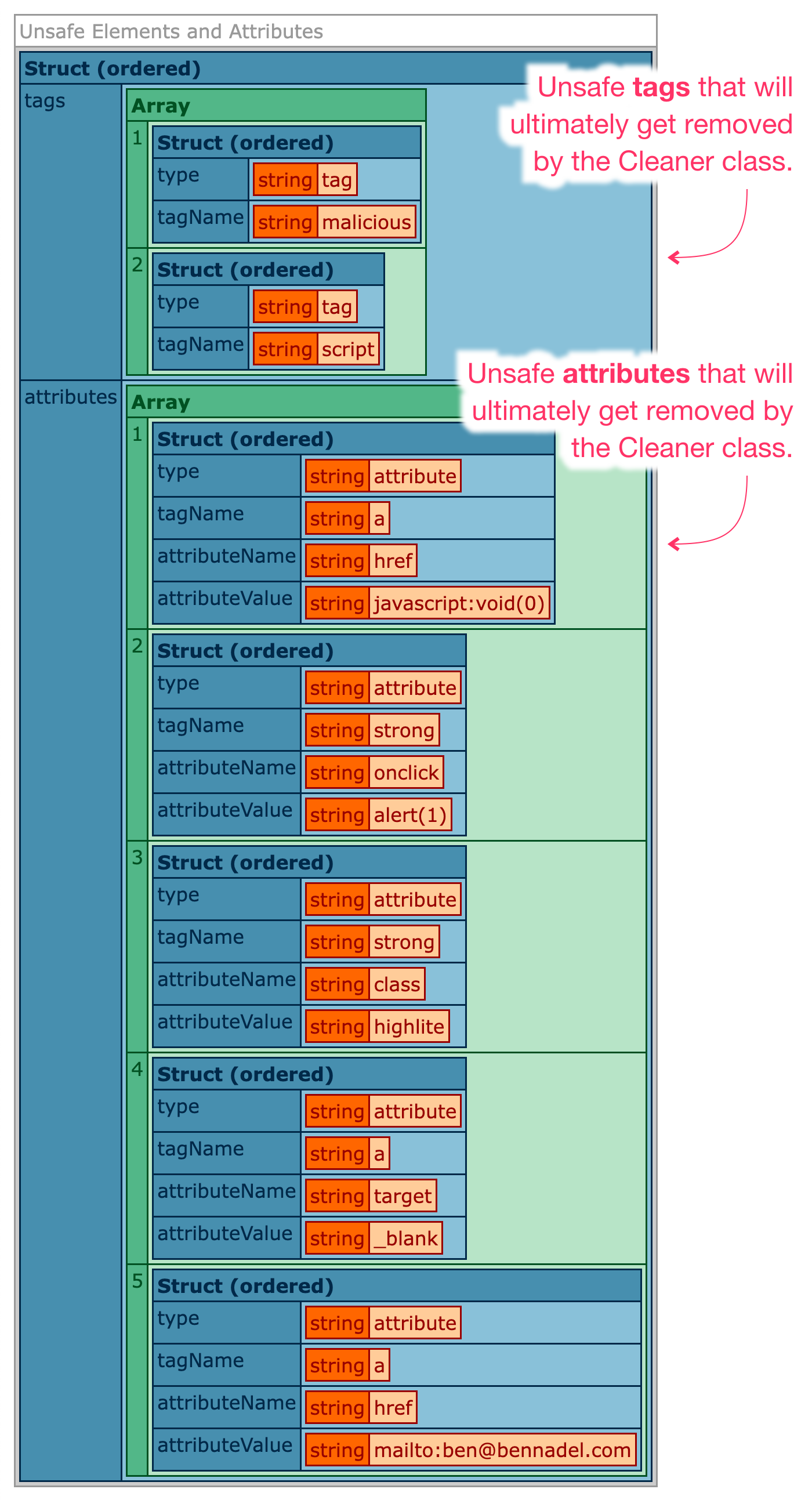
As you can see, by iterating over all the elements and attributes in the untrusted DOM tree, we've identified two "unsafe" elements and five "unsafe" attributes. At this point, it becomes a judgement call on my part as to which errors I want to report back to the user. For example, the user doesn't need to know that I'm removing the target attribute; however, they may want to know that I'm removing the anchor element with the mailto: protocol. Consuming this information will definitely require a nuanced view.
At the top of this post, I said that AntiSamy had a way of reporting this kind of information. And, it does; but, it's not easy to use—it returns natural language error messages that I then have to parse with RegEx pattern matching. With JSoup, I have to do a little more work to get at the untrusted information; but, the outcome is ultimately much easier to consume in my business logic since I'm consuming my data structures. This is another reason why I'll be switching my sanitization processes over to using JSoup.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →