
Generating Lorem Ipsum Text In ColdFusion
As a fun code kata for my /utils section, I wanted to create a Lorem Ipsum text generator. Lorem Ipsum is a common way to create placeholder text during the design phase of the prototyping process. Lorem Ipsum text uses Latin words to embody English-looking text distributions without the distraction of being readable (except by those 4 people who took Latin classes in high school). What follows is my attempt to generate this placeholder text in ColdFusion.
My first step was to find some Latin words to consume. After much Googling, I came across a section on the Dickinson College website called Latin Core Vocabulary. Not only did this website have close to 1,000 terms, it broke them down by language part (ie, Noun, Verb, Adjective, etc); and, it also provided the entire list as an XML document. Huzzah!
Parsing the Latin Core XML Feed
The XML document wasn't the cleanest data. It contained some anchor tags and some language variations and conjugations for each term. I needed to parse the XML feed and translate it into a normalized data structure. Ultimately, I wanted to create a structure that was keyed by language part (ex, "noun", "verb") with each key pointing to an array of relevant Latin terms:
{
"adjective": [ "acer", "adversus", "..." ],
"adverb": [ "adeo", "adhuc", "..." ],
"conjunction": [ "ac", "an", "..." ],
"noun": [ "..." ],
"preposition": [ "..." ],
"pronoun": [ "..." ],
"verb": [ "..." ]
}
To accomplish this, I created a ColdFusion component, Parser.cfc, that served two purposes. First, it would parse the XML document into a normalized, array-of-structs data structure. And second, it would then group the terms by language part.
I just love how easy ColdFusion makes it to consume XML data. The parsed XML document is, essentially, already in struct and array format; but, I wanted to cleanup the data and make the resultant structure easier to debug along the way. Here's my parser:
component
output = false
hint = "I help parse the XML feed provided by https://dcc.dickinson.edu/latin-core-list1"
{
/**
* I extract the terms and group them by language part.
*/
public struct function groupTermsByPart( required array entries ) {
var parts = [
"adjective": [],
"adverb": [],
"conjunction": [],
"noun": [],
"preposition": [],
"pronoun": [],
"verb": []
];
for ( var entry in entries ) {
parts[ entry.part ].append( entry.term );
}
return parts;
}
/**
* I parse the given XML feed file into a normalized data structure.
*/
public array function parseXmlFile( required string filepath ) {
var doc = xmlParse( fileRead( filepath ) );
return doc.response.xmlChildren.map(
( node ) => {
return [
term: extractTerm( node.field_display_headwords.xmlText ),
definition: node.field_definition.xmlText.trim(),
part: extractPart( node.field_part_of_speech.xmlText ),
group: node.field_semantic_group.xmlText.trim().lcase(),
rank: val( node.field_frequency_rank.xmlText.trim() )
];
}
);
}
// ---
// PRIVATE METHODS.
// ---
/**
* I extract the language part from the given field input.
*/
private string function extractPart( required string input ) {
if ( input.reFindNoCase( "\b(adjective)\b" ) ) {
return "adjective";
}
if ( input.reFindNoCase( "\b(adverb)\b" ) ) {
return "adverb";
}
if ( input.reFindNoCase( "\b(conjunction)\b" ) ) {
return "conjunction";
}
if ( input.reFindNoCase( "\b(noun)\b" ) ) {
return "noun";
}
if ( input.reFindNoCase( "\b(preposition)\b" ) ) {
return "preposition";
}
if ( input.reFindNoCase( "\b(pronoun)\b" ) ) {
return "pronoun";
}
if ( input.reFindNoCase( "\b(verb)\b" ) ) {
return "verb";
}
}
/**
* I extract the language term from the given field input.
*/
private string function extractTerm( required string input ) {
// In the XML feed, the term is wrapped in an anchor tag.
var term = input
.lcase()
// Strip out the HTML tags.
.reReplace( "<[^>]+>", "", "all" )
.trim()
// Strip out the first item - the XML feed provides several variations of
// many of the terms.
.listFirst( ", /:-" )
// Replace all the accented characters.
.replace( "ā", "a", "all" )
.replace( "ē", "e", "all" )
.replace( "ī", "i", "all" )
.replace( "ō", "o", "all" )
.replace( "ū", "u", "all" )
;
// Safety: Make sure only normal alpha characters are left.
if ( term.reFind( "[^a-z]" ) ) {
writeDump( term );
abort;
}
return term;
}
}
Once I had the normalized data structure, I used it to generate a ColdFusion template that would store this data into a runtime variable. Notice that the following CFML code is generating a terms-by-part.cfm CFML template that defines a termsByPart variable. This template will be included into a future component.
<cfscript>
parser = new Parser();
entries = parser.parseXmlFile( expandPath( "./input/list.xml" ) );
parts = parser.groupTermsByPart( entries );
fileWrite(
expandPath( "./terms-by-part.cfm" ),
"<cfset variables.termsByPart = #serializeJson( parts )# />",
"utf-8"
);
</cfscript>
I'm doing this so that I don't have to keep reading and parsing a data-file into memory - the CFML template will automatically be compiled and cached as Java byte code. It's probably an unnecessary step; but, I went down a few false starts as I was doing the development and this is where I ended up.
Generating English-Like Latin Text
When I first tried generating the Lorem Ipsum text, I used a purely random selection approach. Meaning, I just selected a bunch of random Latin tokens until a desired length was achieved. But, the generated content didn't look good. It was too random, with lots of tiny words side-by-side.
After trying a number of different approaches, the one that seemed to create the most pleasing results was the use of sentence templates. Essentially, I took English phrases and worked backwards. Meaning, I would take a sentence such as:
"She longed for chocolate cake."
... and translate it into a template using the corresponding parts of speech:
"pronoun verb preposition adjective noun."
Then, in order to translate that into Lorem Ipsum text, I would iterate over the template, pluck out the parts of speech using a regular expression, and replace them with Latin tokens from the aforementioned termsByPart variable:
component {
// ... truncated version ...
private string function generateFromTemplate() {
return template.reReplace(
"\b(adjective|adverb|conjunction|noun|preposition|pronoun|verb)\b",
( transform, position, original, count ) => {
var tokens = termsByPart[ transform.matches ];
return randomElement( tokens );
},
"all"
);
}
}
This method would take the above parts-of-speech template and generate a random Latin string like:
"Aliquis decet cum vagus ignis"
Of course, since the algorithm is random, the generated sentence is non-sense; and, in this case, translates to (according to Google), "Someone should be with a stray fire."
I then created a number of these parts-of-speech templates for both sentences and titles and wrapped them up in a ColdFusion component called Generator.cfc. This component is able to generate single sentences and titles, groups of sentences and titles, and a high-level multi-section document.
In the following code, notice that my constructor function, init(), is performing an include of the generate CFML template that we created earlier (terms-by-part.cfm). This CFInclude tag defines a private variable within the CFC that can then be consumed in the generateFromTemplate() method:
component
output = false
hint = "I generate random Lorem Ipsum text."
{
/**
* I initialize the generator with the given Latin tokens and pattern templates.
*/
public void function init() {
// Language parts:
// - adjective
// - adverb
// - conjunction
// - noun
// - preposition
// - pronoun
// - verb
// --
// Note: I'm hard-coded the terms into a CFML file so that the CFML template will
// be cached a byte-code. This way, I don't have to keep reading a TXT file off of
// disk to get the data.
include "./latin-core/terms-by-part.cfm";
// In an effort to give the generated text a more natural feel, I'm using a finite
// set of sentence patterns. This will allow me to put the commas at natural
// offsets within the text.
variables.sentencePatterns = [
// Example: Dogs love fuzzy kittens.
"noun verb adjective noun.",
// Example: She longed for chocolate cake.
"pronoun verb preposition adjective noun.",
// Example: You broke my heart.
"pronoun verb pronoun noun.",
// Example: This day, just like yesterday, is a beautiful day.
"adjective noun, adverb preposition noun, verb adjective adjective noun.",
// Example: I love your mind and your booty.
"pronoun verb pronoun noun conjunction pronoun noun.",
// Example: You did it, you magnificent bastard.
"pronoun verb pronoun, pronoun adjective noun.",
// Example: I was completely thrilled by the news.
"pronoun verb adverb verb preposition adjective noun."
];
variables.titlePatterns = [
// Example: Burritos are life
"noun verb noun",
// Example: Twerking is the best
"noun verb adjective adjective",
// Example: Dogs and cats living together
"noun conjunction noun verb adverb",
// Example: Things you should avoid doing
"noun pronoun verb verb noun"
];
}
// ---
// PUBLIC METHODS.
// ---
/**
* I generate a structured doc, organized by section, title, and paragraph.
*/
public array function generateDoc(
required boolean useLoremIpsum,
required boolean useTitles,
required numeric paragraphCount
) {
// Note: To keep things simple, we're going to split the paragraphs up into
// sections regardless of whether or not we're actually inserting titles. The only
// difference will be that the titles will be empty if they are not to be used
// (and hence will not be rendered in the UI).
var slices = randomSlices(
generateParagraphs( paragraphCount ),
2, // Min slice size.
5 // Max slice size.
);
var sections = slices.map(
( slice ) => {
var title = useTitles
? generateTitle()
: ""
;
return [
title: title,
paragraphs: slice
];
}
);
// If using the traditional Lorem Ipsum prefix, replace whatever the first word
// with the given intro text.
if ( useLoremIpsum ) {
sections[ 1 ].paragraphs[ 1 ] = sections[ 1 ].paragraphs[ 1 ]
.reReplace( "[\S-]+", "Lorem ipsum dolor sit amet" )
;
}
return sections;
}
/**
* I generate a random paragraph with the given number of random sentences.
*/
public string function generateParagraph(
numeric minCount = 5,
numeric maxCount = 8
) {
return generateSentences( randRange( minCount, maxCount, "sha1prng" ) )
.toList( " " )
;
}
/**
* I generate a given number of random paragraphs.
*/
public array function generateParagraphs( required numeric count ) {
return range( count )
.map( () => generateParagraph() )
;
}
/**
* I generate a random sentence.
*/
public string function generateSentence() {
return generateFromTemplate( sentencePatterns );
}
/**
* I generate a given number of random sentences.
*/
public array function generateSentences( required numeric count ) {
return range( count )
.map( () => generateSentence() )
;
}
/**
* I generate a random title.
*/
public string function generateTitle() {
return generateFromTemplate( titlePatterns );
}
/**
* I generate a given number of random titles.
*/
public array function generateTitles( required numeric count ) {
return range( count )
.map( () => generateTitle() )
;
}
// ---
// PRIVATE METHODS.
// ---
/**
* I generate a random string using one of the given templates.
*/
private string function generateFromTemplate( required array templates ) {
// Each string is generated by randomly selecting one of the given templates; and
// then, replacing each language part with a randomly chosen Latin token.
return randomElement( templates ).reReplace(
"\b(adjective|adverb|conjunction|noun|preposition|pronoun|verb)\b",
( transform, position, original, count ) => {
var tokens = termsByPart[ transform.matches ];
// The first token in the template should never start with a "Q". This is
// strangely distracting since "q" is rarely used as the first letter in
// English words. Keep selecting until a non-Q word is found.
do {
var token = randomElement( tokens );
} while ( ( count == 1 ) && ( token[ 1 ] == "q" ) );
if ( count == 1 ) {
token = ucfirst( token );
}
return token;
},
"all"
);
}
/**
* I return a random element from the given array.
*/
private string function randomElement( required array values ) {
return values[ randRange( 1, values.len(), "sha1prng" ) ];
}
/**
* I group the given collection into random slices of the given sizes.
*/
private array function randomSlices(
required array collection,
required numeric minSize,
required numeric maxSize
) {
var length = collection.len();
var slices = [];
for ( var i = 1 ; i <= length ; i += size ) {
var size = min(
randRange( minSize, maxSize, "sha1prng" ),
( length - i + 1 )
);
slices.append( collection.slice( i, size ) );
}
return slices;
}
/**
* I return a range for 1...size, inclusive.
*/
private array function range( required numeric size ) {
var indices = [];
indices.resize( size );
for ( var i = 1 ; i <= size ; i++ ) {
indices[ i ] = i;
}
return indices;
}
/**
* Adobe ColdFusion shim: upper-case the first letter.
*/
private string function ucfirst( required string input ) {
if ( input.len() == 1 ) {
return ucase( input );
}
return ( ucase( input[ 1 ] ) & input.right( -1 ) );
}
}
The generateFromTemplate() method is a bit more complex than I originally made it out to be. After generating a bunch of Lorem Ipsum text, I was finding myself distracted by the large number of sentences that started with the letter Q. This just felt unusual in English. As such, my final logic prevents any sentences from starting with the letter Q; and, the algorithm will continue selecting tokens until an appropriate term is found.
Rending the Lorem Ipsum Text
The generateDoc() method returns an array of sections, each with a title and a collection of paragraphs. Rendering the Lorem Ipsum text then becomes a simple nested loop. Though, I'm also including the ability to cycle the text in any given title or sentence. This is for purely aesthetic reasons - some text just looks better than others.
<cfscript>
param name="url.generate" type="boolean" default=false;
param name="url.useLoremIpsum" type="boolean" default=false;
param name="url.useTitles" type="boolean" default=false;
// If the form hasn't been submitted yet, set non-false defaults.
if ( ! url.generate ) {
url.useLoremIpsum = true;
url.useTitles = true;
}
doc = new Generator().generateDoc(
useLoremIpsum = !! url.useLoremIpsum,
useTitles = !! url.useTitles,
paragraphCount = 30
);
</cfscript>
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<!-- .. truncated .. -->
</head>
<body>
<main>
<h1>
Lorem Ipsum Placeholder Text
</h1>
<form>
<input type="hidden" name="generate" value="true" />
<label>
<input
type="checkbox"
name="useLoremIpsum"
value="true"
<cfif url.useLoremIpsum>
checked
</cfif>
/>
Use "Lorem ipsum" prefix.
</label>
<label>
<input
type="checkbox"
name="useTitles"
value="true"
<cfif url.useTitles>
checked
</cfif>
/>
Use section titles.
</label>
<fieldset>
<button type="submit">
Generate text
</button>
<button type="button" class="copy">
Copy text
</button>
</fieldset>
</form>
<p class="attribution">
Latin terms borrowed with gratitude <a href="https://dcc.dickinson.edu/latin-core-list1" target="_blank">from Dickinson College</a>.
</p>
<hr />
<!---
For the sake of simplicity, even when we're not rendering titles, the doc
is still broken up into sections.
--->
<article>
<cfloop array="#doc#" index="section">
<cfif section.title.len()>
<figure>
<h2>
#encodeForHtml( section.title )#
</h2>
<button data-type="title">
Cycle
</button>
</figure>
</cfif>
<cfloop array="#section.paragraphs#" index="text">
<figure>
<p>
#encodeForHtml( text )#
</p>
<button data-type="paragraph">
Cycle
</button>
</figure>
</cfloop>
</cfloop>
</article>
</main>
<script type="text/javascript">
// Hook up handler for copy button.
document.querySelector( "button.copy" )
.addEventListener( "click", handleCopy )
;
// Hook up handlers for the cycle buttons.
for ( var button of document.querySelectorAll( "figure button" ) ) {
button.addEventListener( "click", handleCycle );
}
/**
* I cycle the sample text in the given context.
*/
async function handleCycle( event ) {
var buttonNode = event.currentTarget;
var textNode = buttonNode.previousElementSibling;
var type = buttonNode.dataset.type;
try {
textNode.textContent = await getNewText( type );
} catch ( error ) {
console.group( "Cycle operation failed." );
console.error( error );
console.groupEnd();
}
}
/**
* I generate new sample text of the given type.
*/
async function getNewText( type ) {
var response = await fetch( `./cycle.cfm?type=${ type }` );
if ( ! response.ok ) {
throw( new Error( "API responded with non-200 status.", { cause: response } ) );
}
var text = await response.text();
return text.trim();
}
/**
* I copy the currently-rendered text nodes to the user's clipboard.
*/
function handleCopy() {
var textNodes = document.querySelectorAll( "figure > *:first-child" );
var text = Array.from( textNodes )
.map( ( node ) => node.textContent.trim() )
.join( "\n\n" )
.trim()
;
console.log( text );
navigator.clipboard.writeText( text );
}
</script>
</body>
</html>
</cfoutput>
Next to each Lorem Ipsum element, there's a Cycle button. This button makes a fetch() call to the server to generate a new type of data:
<cfscript>
param name="url.type" type="string" default="paragraph";
if ( url.type == "title" ) {
writeOutput( new Generator().generateTitle() );
} else {
writeOutput( new Generator().generateParagraph() );
}
</cfscript>
Now, if I run this ColdFusion page to generate Lorem Ipsum text, I get the following output:
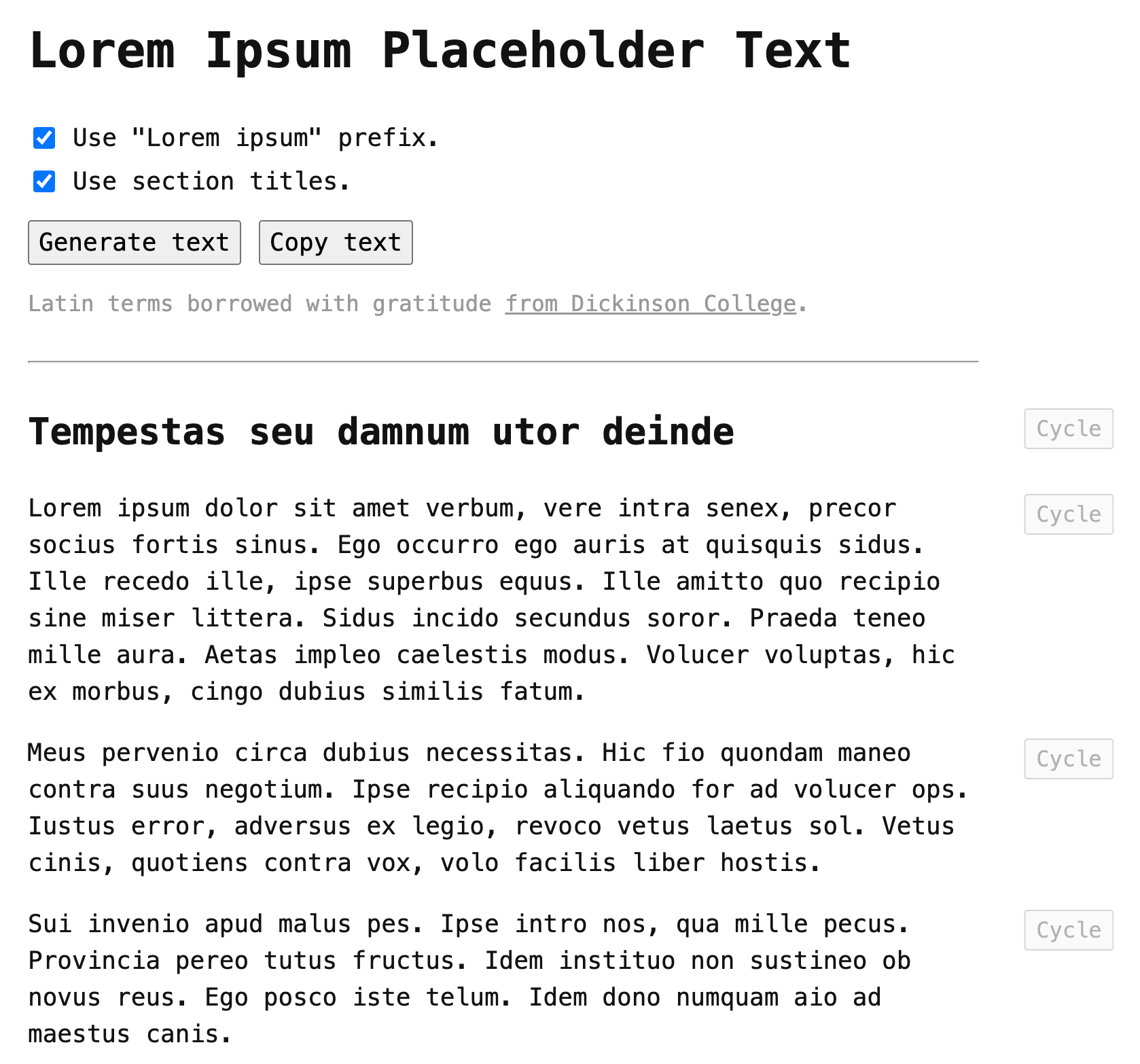
I think it looks pretty good. And, I think the solution that I came up with is a nice mixture of simplicity and elegance. I tried looking up some other Lorem Ipsum algorithms; but they all seemed much more complex with mathematical models that took word-length distribution into account. I really liked the "sentence template" approach that I took because it allowed me to keep it a little more brute force and little less magical.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →