
Generating Fake User And Company Data With ColdFusion
As a companion piece to my Feature Flags Book, I'm creating a small playground app in which readers can explore the feature flags experience, both from a configuration and a consumption standpoint. As part of this process, I had to generate a set of fake users against which a set of configured feature flags could be evaluated. I know there are plenty of existing websites that will generate fake data for you; however, since I needed a predictable set of properties for my feature flag rules engine, I decided to generate my own fake data using ColdFusion.
Fake data is nothing more than an aggregation of random values into a meaningful structure. In my case, I wanted to generate 100 fake users that were spread across 10 fake companies. When doing this kind of work, the hardest part is just coming up with the names. So, I asked ChatGPT to generate the names for me:
- Give me 30 fake tech company subdomains.
- Give me the 50 most popular American male first names.
- Give me the 50 most popular American female first names.
- Give me the 50 most popular American last names.
Aside: At first, I tried asking ChatGPT to generate the entire set of fake data for me as a CSV (Comma Separated Values) file. However, this was an uphill battle of ever-increasing prompt specificity. After about 45-minutes of not getting what I wanted, I decided to scrap the idea and just generate my own fake data.
Once I had these values, it was just a matter of selecting random values with randRange("sha1prng") and coalescing the parts into a meaningful whole.
But, I didn't want the data to be entirely random. After all, I'm generating this data for feature flag targeting. Which means, I want to ensure that some of the values exist in a known state so that they can be targeted within my app. As such, I'm using my iterating variables to drive some predictability in the outcome while allowing the rest of the data to be mostly random.
Specifically, the first company always has the property fortune100 set to true. And, the first user—within each company—always has the property role set to admin.
With that said, here's my ColdFusion code. It builds up an array of users; and then uses the JSON.stringify() method to "pretty print" the array to the response (on the client-side). Note that I'm using ordered structs to define the data so that the structures serialize in a human-friendly manner.
Try running this script for yourself →
<cfscript>
subdomains = [
"bytech", "cybercore", "cybernetics", "datalynk", "datasync", "digitalsys",
"fusionworks", "futuretech", "infocorp", "infologic", "infotech", "infowave",
"innovaplex", "megacorp", "netfusion", "nexsol", "nextbyte", "nextech",
"primetech", "quantumsoft", "softgen", "starcorp", "sysmax", "sysnova",
"techgenius", "techhub", "techlink", "techtide", "techwave", "ultralink"
];
firstNames = [
"Abigail", "Addison", "Aiden", "Alexander", "Amelia", "Anthony", "Aria", "Asher",
"Aubrey", "Audrey", "Aurora", "Ava", "Avery", "Bella", "Benjamin", "Camila",
"Carter", "Charles", "Chloe", "Christopher", "Daniel", "David", "Dylan",
"Eleanor", "Elijah", "Elizabeth", "Ella", "Ellie", "Emilia", "Emily", "Emma",
"Ethan", "Evelyn", "Everly", "Ezra", "Gabriel", "Grace", "Grayson", "Hannah",
"Harper", "Hazel", "Henry", "Hudson", "Isaac", "Isabella", "Jack", "Jackson",
"Jacob", "James", "Jaxon", "Jayden", "John", "Joseph", "Josiah", "Julian",
"Layla", "Leah", "Leo", "Levi", "Liam", "Lillian", "Lily", "Lincoln", "Logan",
"Lucas", "Lucy", "Luke", "Luna", "Madison", "Mason", "Mateo", "Matthew",
"Maverick", "Mia", "Michael", "Mila", "Natalie", "Noah", "Nora", "Nova", "Oliver",
"Olivia", "Owen", "Penelope", "Riley", "Samuel", "Scarlett", "Sebastian", "Sofia",
"Sophia", "Stella", "Theodore", "Thomas", "Victoria", "Violet", "William",
"Willow", "Wyatt", "Zoe", "Zoey"
];
lastNames = [
"Adams", "Allen", "Anderson", "Baker", "Brown", "Campbell", "Carter", "Clark",
"Davis", "Flores", "Garcia", "Gonzalez", "Green", "Hall", "Harris", "Hernandez",
"Hill", "Jackson", "Johnson", "Jones", "King", "Lee", "Lewis", "Lopez", "Martin",
"Martinez", "Miller", "Mitchell", "Moore", "Nelson", "Nguyen", "Perez", "Ramirez",
"Rivera", "Roberts", "Robinson", "Rodriguez", "Sanchez", "Scott", "Smith",
"Taylor", "Thomas", "Thompson", "Torres", "Walker", "White", "Williams", "Wilson",
"Wright", "Young"
];
roles = [ "admin", "manager", "engineer", "support", "analyst" ];
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
companyID = 1000;
companies = [];
// We need the companies to be unique. As such, we're not going to simply pull random
// values from the subdomains list. Instead, we're going to shuffle the subdomains
// collection and then just read items off the head.
shuffleValues( subdomains );
// 10 companies.
for ( i = 1 ; i <= 10 ; i++ ) {
// The first company should be fortune 100.
if ( i == 1 ) {
fortune100 = true;
fortune500 = false;
// Every other company should be randomly in fortune 500.
} else {
fortune100 = false;
fortune500 = randomTrue( 3 );
}
companies.append([
id: ++companyID,
subdomain: subdomains[ i ],
fortune100: fortune100,
fortune500: fortune500
]);
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
userID = 0;
users = [];
for ( company in companies ) {
// For each of 10 companies, 10 users (100 demo users in total).
for ( i = 1 ; i <= 10 ; i++ ) {
firstName = randomValue( firstNames );
lastName = randomValue( lastNames );
// First user role should always be Admin, all other roles are random.
role = ( i == 1 )
? roles[ 1 ]
: randomValue( roles )
;
users.append([
id: ++userID,
name: "#firstName# #lastName#",
email: lcase( "#firstName#.#lastName#@#company.subdomain#.example.com" ),
role: role,
company: company,
groups: [
betaTester: randomTrue( 5 ),
influencer: randomTrue( 20 )
]
]);
}
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I return a random value from the given array.
*/
public any function randomValue( required array values ) {
return values[ randRange( 1, arrayLen( values ), "sha1prng" ) ];
}
/**
* I return a random True with the given 1/chance.
*/
public boolean function randomTrue( required numeric chance ) {
return ( randRange( 0, chance, "sha1prng" ) == chance );
}
/**
* I shuffle the given array (in place) and return the reference.
*/
public array function shuffleValues( required array values ) {
createObject( "java", "java.util.Collections" )
.shuffle( values )
;
return values;
}
</cfscript>
<!--- Pretty-print the ColdFusion data using JavaScript's JSON implementation. --->
<pre><code id="prettyprint"></code></pre>
<script type="text/javascript">
data = JSON.parse( "<cfoutput>#encodeForJavaScript( serializeJson( users ) )#</cfoutput>" );
window.prettyprint.textContent = JSON.stringify( data, null, " " );
</script>
To keep things simple, I'm not worrying about data normalization—each user has their own company embedded within their user data. Since this demo is relatively small, I'm not concerned about the size of the payload. At this point, I'm erring on the side of easier consumption.
That said, when we run this ColdFusion code, we get the following output (truncated):
[
{
"id": 1,
"name": "Leo Martin",
"email": "leo.martin@fusionworks.example.com",
"role": "admin",
"company": {
"id": 1001,
"subdomain": "fusionworks",
"fortune100": true,
"fortune500": false
},
"groups": {
"betaTester": true,
"influencer": false
}
},
{
"id": 2,
"name": "Benjamin Hernandez",
"email": "benjamin.hernandez@fusionworks.example.com",
"role": "admin",
"company": {
"id": 1001,
"subdomain": "fusionworks",
"fortune100": true,
"fortune500": false
},
"groups": {
"betaTester": false,
"influencer": false
}
},
{
"id": 3,
"name": "Hudson Campbell",
"email": "hudson.campbell@fusionworks.example.com",
"role": "admin",
"company": {
"id": 1001,
"subdomain": "fusionworks",
"fortune100": true,
"fortune500": false
},
"groups": {
"betaTester": false,
"influencer": false
}
},
// ... 97 more fake users ...
]
And now that I have this data in a predictable structure, I can use the user and company properties to define a context object against which to evaluate feature flags. For example, I can enable the product-TICKET-111-reporting feature flag for any user with role:"admin":
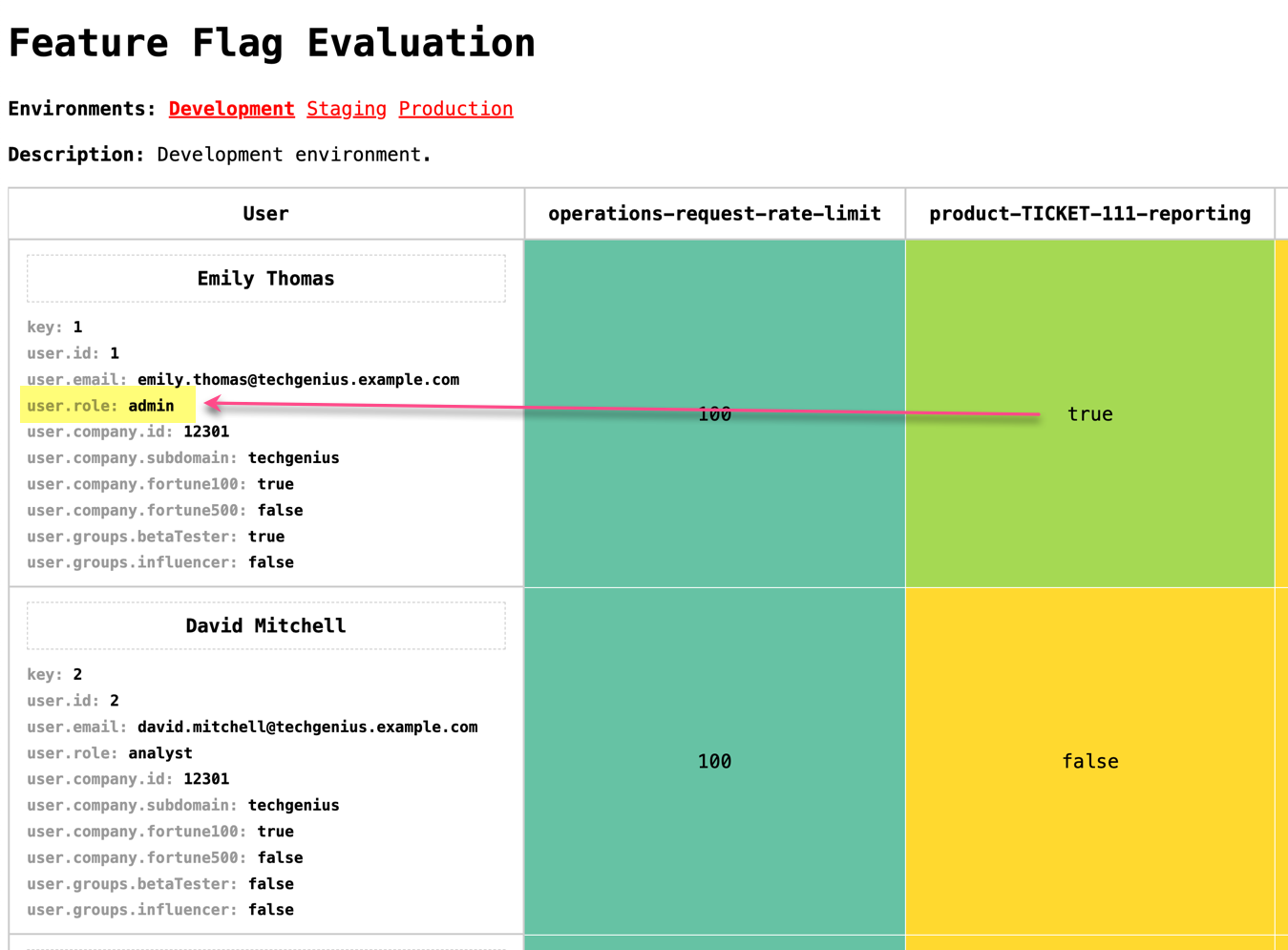
I know it's very tempting to reach for some external solution to a problem; such as when I tried to have ChatGPT generate the entire set of fake data. But, it's sometimes easier, faster, and more robust to just implement a solution for yourself. And, in this case, ColdFusion makes it really easy to randomize and coalesce data.
Want to use code from this post? Check out the license.

Reader Comments
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →