
Reading Element Attributes Collection In JavaScript
For as long as I can remember, I've been using JavaScript to interact with individual attributes stored in the Document Object Model (DOM). This includes abstractions such as jQuery's .attr() method; and, native DOM methods like .getAttribute(), .setAttribute(), .removeAttribute(), and .hasAttribute(). But, I've never worked with attributes as a collection. Having used several frameworks that make heavy use of custom attributes (Angular, Alpine, HTMX, etc), I'm now curious to better understand the meta-programming mechanics that these frameworks are using.
Run this demo in my JavaScript Demos project on GitHub.
View this code in my JavaScript Demos project on GitHub.
When Angular was released in 2015, the syntax seemed rather wild at first glance. It was using all manner of characters within the HTML attributes that I had never seen before. For example, setting a property was defined using bracket-notation:
<input [disabled]="isDisabled" />
And, binding to an event was defined using parenthesis-notation:
<form (submit)="processForm()">
You could even setup event binding with dot-modifiers, such as those that might be helpful during keyboard events:
<textarea (keydown.meta.enter)="submitForm()">
At first, people scoffed at this idea. But, Angular claimed that this was all perfectly valid HTML syntax. And, after the initial shock wore off, developers began to see the brilliance of this approach. In fact, other frameworks, like Alpine.js, followed suit.
In Alpine.js, for example, you can setup property bindings with x-bind:
<input x-bind:disabled="isDisabled" />
And, you can setup event bindings using @:
<textarea @keydown.meta.enter="submitForm()">
And, just as in the Angular context, this Alpine.js code represents perfectly valid HTML syntax.
It turns out, these are all just key-value pairs. All the fancy syntax that you see on left-side of the = sign, it's all just a single string. And, each framework must parse said string into semantically relevant tokens.
These strings can be accessed using the .attributes property on the DOM node. To see this in action, I've created a demo with a single <p> tag with a variety of attribute pairs. I then use the .attributes property to iterate over all the attribute pairs:
<!doctype html>
<html lang="en">
<body>
<h1>
Reading Element Attributes In JavaScript
</h1>
<p
id="target"
x-DIRECTIVE="A"
x-DIRECTIVE="B"
X-DIRECTIVE:VALUE1
x-directive:value2="expression2"
x-directive:value3.modifierA.modifierB="expression3"
x-directive:value4.MODIFIERA.modifierB="expression4"
:class="{ active: true }"
@click="console.log( 'Hello' )"
[class.active]="true"
[style.width.px]="100"
(click.prevent)="submit()">
</p>
<script type="text/javascript">
// The ".attributes" property is a live collection of the attributes on the given
// node. It is "array-like"; and can be iterated using for-of. Each attribute
// exposes a "name" and "value" property.
for ( var attribute of window.target.attributes ) {
console.group( "Attribute Pair" );
logPair( "Name:", attribute.name );
logPair( "Value:", attribute.value );
console.groupEnd();
}
/**
* I pretty-print the key-value pair to the console.
*/
function logPair( key, value ) {
console.log(
"%c%s%c %s",
"color: #999", // Key styles.
key,
"", // Value styles (reset).
value
);
}
</script>
</body>
</html>
Within a single element, all attribute names must be unique. As such, you will see that the X-DIRECTIVE attribute, which I have in the HTML twice, will only show up once in the console logging. Furthermore, all attribute names will be converted to lowercase.
When we run the above code, we get the following console output:
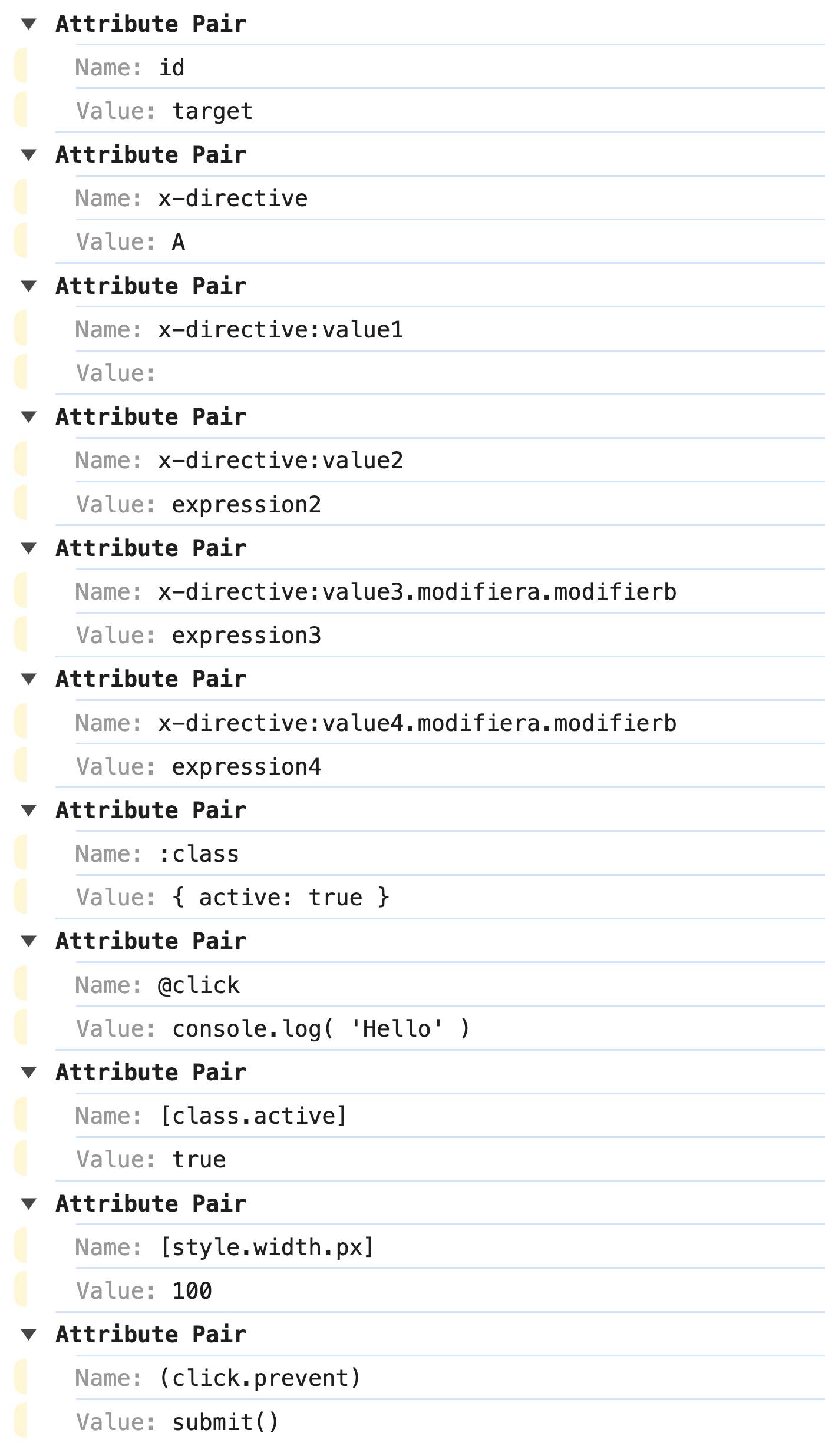
As you can see, it's all DOM-native key-value pairs. Each key is a string. And, each value is a string. This is pretty cool. And, it sheds a lot of light on how these frameworks provide such a robust set of domain specific languages (DSL) for the developers to consume.
Want to use code from this post? Check out the license.
Reader Comments
While custom attributes can be useful in detail, frameworks generally rely on having a copy of the DOM (virtual dom) and processing the entire thing don't they?
Achieving the same effect with a non-framework requires use of the DOM Mutation Observer API. This lets you spot new/changed elements in the DOM that have your custom attributes and to do something with them.
@Julian,
I think it's very framework specific. For example, Stimulus.js and Alpine.js both use
MutationObserverto do exactly what you're saying. But, Angular.js (and modern Angular) neither use a mutation observer nor a virtual DOM (but rather an in internal collection of "watch" expressions).But, certainly, the
MutationObserveris a very powerful tool!Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Post a Comment →