
Posting Comments Using Reply Emails And Postmark's Inbound Streams In ColdFusion 2021
I've been a very happy Postmark customer for the last decade. Their SMTP and API services make sending and receiving emails absurdly simple. And, their Inbound webhooks allow you to treat Postmark as a reverse proxy that transforms inbound email delivery into API calls (webhooks) against your own servers. I've been wanting to use this feature on my blog forever; however, I was always afraid that it would lead to massive abuse. That said, in response to a recent spam attack, I was forced to add comment moderation. Which means, I can safely start playing with reply-based comment posting using Postmark's Inbound stream!
When you set up a server in Postmark, you can configure Transactional streams, Inbound streams, and Broadcast streams. The Transactional streams deliver emails to your users based on application-driven events (ex, sending a "Welcome" email after a user signs-up); the Broadcast streams - which are relatively new - deliver marketing emails to your users at your discretion; and finally, the Inbound streams accept emails from your users, parse those emails into JSON (JavaScript Object Notation) payloads, and then POST those payloads to an end-point of your choosing.
When you define an Inbound stream, Postmark allocates a unique email address for that stream. Something in the form of:
myuniqueinboxid@inbound.postmarkapp.com
Any email that is sent to that address will then be posted to your Webhook end-point. Of course, the unique ID in the email address may map the email to your Inbound stream (and its Webhook); but, it doesn't provide any application-specific information - the "Who", "What", and "Why" of the email that you'll likely need when processing the Webhook request.
Fortunately, Postmark allows us to use plus-style addressing on the Inbound stream. That is, it allows the above email address to contain a + suffix in the username. Something in the form of:
myuniqueinboxid+data@inbound.postmarkapp.com
Notice that the above email address has +data right before the @. When Postmark receives an email from such an address, it uses the plus-prefix to identify the correct Inbound stream; and then, it takes the plus-suffix and includes it in the Webhook payload as the MailboxHash property. So, for example, the JSON payload for the above email address would look like this (heavily truncated):
{
"To": "myuniqueinboxid+data@inbound.postmarkapp.com",
"TextBody": "...",
"HtmlBody": "...",
"StrippedTextReply": "...",
"MailboxHash": "data"
}
This MailboxHash property is the way in which we can provide metadata about why our Inbound Webhook is being called. This property can contain any information that we want, as long as it doesn't conflict with the email-address formatting.
When a comment is posted to one of my blog entries, I iterate over each one of the subscribers and send them a comment email. This email contains a Call to Action (CTA) that brings the subscriber back into my website for further interactions. With the addition of an Inbound stream, I can now include a replyTo property on my CFMail tag that directs replies to my webhook by way of Postmark.
ASIDE: We have to use a
replyToproperty since Postmark can only send emails from a predefined set of email address signatures. As such, we can't send emails from a dynamically generated email address; but, we can influence the Reply functionality using special SMTP headers.
My comment processing workflow now looks something like this (pseudo-code):
component {
public void function addComment() {
for ( var subscriber in getSubscribers() ) {
// Create the mailbox hash to use for this particular SUBSCRIBER.
// It has to relay both the user AND the entry so that we know
// which entry will receive the reply-to comment.
// --
// NOTE: We should include the subscriber ID and NOT RELY on the
// email address that sends the inbound email to Postmark - users
// have all kinds of complex email-forwarding and aliases
// constructs which make the "from" address unpredictable.
var hashData = {
userID: subscriber.id,
entryID: entry.id
};
// When we serialize the mailbox hash-data and include it in the
// Inbound email address, we have to utilize some sort of security
// method to make sure the data isn't tampered with. This could
// be encryption; it could include a one-way hash signature; or,
// it could include some sort of one-time use token. The choice
// is yours.
var replyToEmail = (
"myuniqueinboxid+" &
serializeAndEncrypt( hashData ) &
"@inbound.postmarkapp.com"
);
cfmail(
to = subscriber.email,
from = config.postmark.from,
replyTo = replyToEmail,
subject = "A comment was posted to: #entry.name#",
type = "HTML"
) {
include "/transactional-emails/new-comment.cfm";
}
}
}
}
As you can see, each outbound, transactional comment email includes a subscriber-specific replyTo directive which points to my Postmark Inbound stream; and, includes subscriber/entry-specific data which will be available in my webhook:
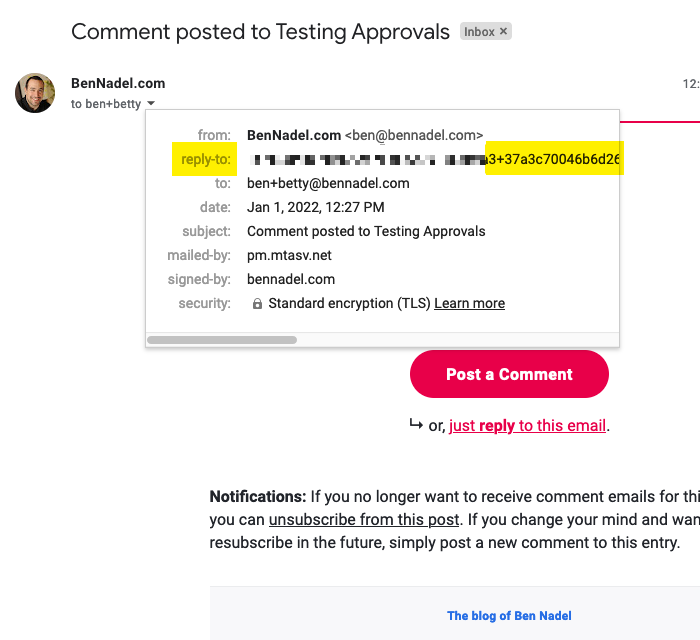
As you can see, the Reply-To header includes a subscriber-specific + style address.
On the webhook side, I can then use the getHttpRequestData() to access the Postmark Inbound payload, which gives me access to both the email-content and the MailboxHash (which is our serialized and encrypted data from above). I can then take that data and turn it into a Pending Comment ready for moderation (pseudo-code):
component {
public void function addCommentFromInboundWebhook() {
var httpRequestData = getHttpRequestData();
var httpHeaders = httpRequestData.headers;
var httpContent = httpRequestData.content;
// Postmark always sends Inbound emails from a fixed set of IP
// addresses. For security purposes, we should verify the origin.
testInboundIpAddress( httpHeaders );
var inboundData = deserializeJson( httpContent );
// The mailbox hash is specific to BOTH the subscriber and the blog
// post. This way, we know where to direct the new comment.
var mailboxHashData = decryptAndDeserialize( inboundData.MailboxHash );
var userID = mailboxHashData.userID;
var entryID = mailboxHashData.entryID;
// When a user replies to an email, Postmark populates the
// StrippedTextReply field with the reply-only content (as determined
// by PostMark). However, this is only populated by Reply emails -
// not by "mailto:" emails (even when addressed to the inbound
// mailbox). For "mailto:" links, we have to use the "TextBody", which
// has not been "cleaned up" by Postmark.
var rawTextReply = ( inboundData.StrippedTextReply.len() )
? inboundData.StrippedTextReply.trim()
: inboundData.TextBody.trim()
;
// Regardless of the text being provided by PostMark, we still have to
// apply some additional normalization and sanitization (especially if
// the user used a "mailto:" link).
var commentMarkdown = plainTextEmailParser
.parseReply( rawTextReply )
;
saveCommentForModeration( entryID, userID, commentMarkdown );
}
}
If the user actually uses the reply functionality of their email client, Postmark will automatically extract the reply content and provide it in the StrippedTextReply property of the Inbound data. However, if the user were to use a mailto: link (such as the one in my comment email), the StrippedTextReply comes through as an empty-string. As such, we can't rely solely on the StrippedTextReply content - if it's empty, we have to fallback on the TextBody.
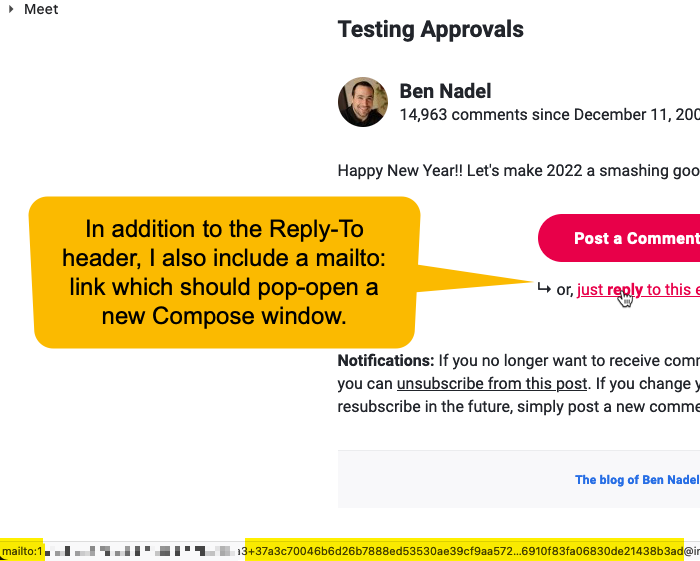
Of course, the TextBody property contains all the text of the email, including the user's signature and the quoted content. And, we definitely don't want all that junk showing up in the blog comments. As such, I have to try and clean up the content before I persist it. That's what the PlainTextEmailParser.cfc ColdFusion component is doing.
To be clear, parsing an email is more art than science. What I have today is "version 1" of the parser. As the reply-based comments get used, I'll have to tweak the algorithm as I see different variations coming through. Thankfully, since all of these Inbound replies go through moderation, it should allow me to view, edit, and evolve the parser without sacrificing the blog content quality.
Here's what I have for "version 1" of the plain-text parser - it's mostly a bunch of Regular Expressions (RegEx) that attempt to normalize and split the content apart:
component
output = false
hint = "I provide parsing / sanitization methods for plain-text email content."
{
/**
* I parse and normalize the given plain-text email content, returning the part that
* represents the main reply-content.
*/
public string function parseReply( required string content ) {
content = normalizeLineEndings( content );
content = normalizeSpaces( content );
content = normalizeEmptyLines( content );
// Now that we've normalized the whitespace markers, let's strip-off common
// signature formats. This is going to be an ONGOING GAME OF CAT-AND-MOUSE since
// signatures vary greatly across users and languages. However, since we're using
// comment moderation for all inbound emails, we can review and update this logic
// as the reply-based commenting receives usage.
content = stripSignature( content );
content = normalizeWrappedLines( content );
content = normalizeQuotes( content );
content = normalizeBullets( content );
return( content );
}
// ---
// PRIVATE METHODS.
// ---
/**
* I use Java's Pattern engine to return all the content that comes before the first
* match of the given RegEx pattern.
*/
private string function jreBefore(
required string content,
required string pattern
) {
// Using the pattern to SPLIT the text, limit the parts to 2 so that we can
// reduce the amount of processing that we have to perform - we know that the
// content we're interested in will always be the first match.
var parts = javaCast( "string", content ).split(
javaCast( "string", pattern ),
javaCast( "int", 2 )
);
return( parts[ 1 ].trim() );
}
/**
* I use Java's Pattern engine to perform a RegEx replace on the given content.
*/
private string function jreReplace(
required string content,
required string pattern,
string replacement = ""
) {
var result = javaCast( "string", content ).replaceAll(
javaCast( "string", pattern ),
javaCast( "string", replacement )
);
return( result );
}
/**
* I replace special bullets with an ASCII asterisk.
*/
private string function normalizeBullets( required string content ) {
content = jreReplace( content, "\u2022|\u2023|\u2043|\u2219|\u25cb|\u25cf|\u25e6", "*" );
return( content );
}
/**
* I trim lines that contain nothing but spaces.
*/
private string function normalizeEmptyLines( required string content ) {
return( jreReplace( content, "(?m)^[\s&&[^\n]]+$", "" ).trim() );
}
/**
* I convert all the line-breaks to NewLine characters. This will make subsequent
* pattern matching easier to perform.
*/
private string function normalizeLineEndings( required string content ) {
return( jreReplace( content, "\r\n?", chr( 10 ) ).trim() );
}
/**
* I replace "smart quotes" with standard ASCII quotes.
*/
private string function normalizeQuotes( required string content ) {
content = jreReplace( content, "\u2018|\u2019|\u201b|\u275b|\u275c", "'" );
content = jreReplace( content, "\u201c|\u201d|\u201e|\u201f|\u275d|\u275e|\u301d|\u301e|\u301f|\uff02", """" );
return( content );
}
/**
* I convert any special spaces to regular spaces.
*/
private string function normalizeSpaces( required string content ) {
return( jreReplace( content, "\u00a0|\u2000|\u2001|\u2002|\u2003|\u2004|\u2005|\u2006|\u2007|\u2008|\u2009|\u200a|\u2028|\u2029", " " ).trim() );
}
/**
* I attempt to remove any artificial line-breaks that were added by the SMTP server.
* Some SMTP servers will force a line to wrap if it is longer than 70 characters.
*/
private string function normalizeWrappedLines( required string content ) {
// The pattern tries to find lines that hard-wrap after (at least) 60 characters.
// Notice that the start of the pattern is either the line-start (^) OR the last
// match (\G). This allows the pattern to keep matching several connected lines.
var wrappedLinePattern = (
"(?mi)" &
"(?:^|\G)" &
"([^\n]{60,})" &
"\n" &
"([^\n]+)"
);
var pattern = createObject( "java", "java.util.regex.Pattern" )
.compile( javaCast( "string", wrappedLinePattern ) )
;
// Since the pattern only matches on a single line-break, it will fail to catch
// a single line that has been artificially split across more than 2-lines. As
// such, we have to keep applying the normalization until we find no matches.
do {
var matchCount = 0;
var matcher = pattern.matcher( javaCast( "string", content ) );
var buffer = createObject( "java", "java.lang.StringBuffer" ).init();
// Replace each match with the first and second line joined with a space.
while ( matcher.find() ) {
matcher.appendReplacement( buffer, javaCast( "string", "$1 $2" ) );
matchCount++;
}
matcher.appendTail( buffer );
content = buffer.toString();
} while ( matchCount );
return( content.trim() );
}
/**
* I strip off common signatures and any content that comes after those signatures.
*/
private string function stripSignature( required string content ) {
// Vertical tabbing (ie, someone putting in a bunch of line-breaks so that their
// reply isn't scrunched-up against the original email content).
content = jreBefore( content, "\n{4,}" );
// Horizontal rule indicators.
content = jreBefore( content, "(?m)^_{7}" );
content = jreBefore( content, "(?m)^-----" );
// Common pre-signature marks.
content = jreBefore( content, "(?m)^-- +\n" );
content = jreBefore( content, "(?m)^---\n" );
content = jreBefore( content, "(?m)^--[A-Z]" );
content = jreBefore( content, "\n{2,}--+\n" );
content = jreBefore( content, "(?m)^(\u2014)+ +\n" ); // Em-dash.
// Common "On wrote:" quotations.
content = jreBefore( content, "(?mi)^On [^\n]+?\bwrote:\n" );
content = jreBefore( content, "(?mi)^On [^\n]+?\n[^\n]+?\bwrote:\n" );
// Common origin device indicators.
content = jreBefore( content, "(?mi)^Sent from (Mailbox)" );
content = jreBefore( content, "(?mi)^Sent from my (Android|Blackberry|iPhone|iPad|iPod|Mobile|Verizon|Windows)" );
content = jreBefore( content, "(?mi)^Get Outlook for (iOS)" );
return( content );
}
}
In this code, the jre prefix on some of my function names stands for "Java RegEx" (as opposed to POSIX RegEx, which is the default Regular Expression engine in ColdFusion). It will definitely be a balancing act trying to find patterns that remove unwanted content while not removing some strange text that a user intended to include in the comment.
And, doing anything with fenced code blocks will be much harder; and is not supported at this time.
This is super exciting! I can't believe how much I've been able to transform the ColdFusion infrastructure of my blog over the last month-or-so. ColdFusion is just a thrilling language. And, Postmark is an amazing email delivery service. Hopefully, I can get the two of them to play nicely together.
Want to use code from this post? Check out the license.

Reader Comments
It looks like GitHub open-sources their email reply parser - I'll have to take a look at see how it works. On first glance, it looks similar in that it uses RegEx to pick apart the email. But, I'm having trouble understanding the Ruby code.
This looks really great, Ben…🙏
It's good to see your blog is still evolving, after so many years!
Thank you, good sir. Currently writing this comment as a Reply on my iPhone Gmail app 😎 I've had a lot of fun updating the code and bringing it into the future. Love me some ColdFusion!! Heck yeah!!
Yes. I am now replying! Amazing Let's see if this works, Ben! 🙏🙏🙏
@Charles,
Hey sorry, your email signature got posted there (I just deleted it). I'll have to look at the formatting to see why. I was so excited to see someone use the feature, I forgot to actually "moderate" it 🤪
Ha ha ha! No worries, Ben!
The new reply feature seems to work like a charm. Nice work…🙏
Hi Ben, I've also been Postmark App supporter for many years and was caught out by not being aware that they don't send emails to you when your smtp delivery fails - oops. As a result I was looking to create a webhook listener to send me emails when that happens. As always you've been there first which seems to make my challenge much easier. Although my requirement is a little different you demo helps push me in the right direction. Thank you. 🙂
@William,
Oh heck yeah!! Always happy to help 😊