
Using WHERE TRUE To Create Dynamic, High-Performance SQL Queries In MySQL 5.7.32 And Lucee CFML 5.3.8.201
When I write ColdFusion applications, I almost always create a "Data Access Layer" (DAL) so that my business logic isn't intermingled with my SQL query syntax. And, to make this DAL more flexible, I tend to create some sort of "By Filter" function that allows me to query a given table using a variety of WHERE conditions. In order to make this query "simple", I'll start it with a WHERE TRUE condition so that every subsequent condition can uniformly start with AND. I recently read something somewhere (source forgotten) that indicated such an approach would cause index issues; however, this does not jive with what I read in High Performance MySQL. As such, I wanted to put together a quick exploration to see how using WHERE TRUE would affect MySQL's query planner outcomes.
In High Performance MySQL: Optimization, Backups, and Replication by Baron Schwartz, Peter Zaitsev, and Vadim Tkachenko, it states that constant conditions can be removed from the MySQL query planner:
Applying algebraic equivalence rules
MySQL applies algebraic transformations to simplify and canonicalize expressions. It can also fold and reduce constants, eliminating impossible constraints and constant conditions. For example, the term
(5=5 AND a>5)will reduce to justa>5. Similarly,(a<b AND b=c) AND a=5becomesb>5 AND b=c AND a=5. These rules are very useful for writing conditional queries, which we discuss later in this chapter. (Kindle Locations 5684-5687)
This seems to indicate that if I start a conditional SQL query with the constant conditions, WHERE TRUE, the MySQL query planner will simply remove it from the query plan since it doesn't affect any of the row filtering. To test this, I've written a "By Filter" function that looks at an old InVision table that is no longer in use, but which still has a ton of data in it:
CREATE TABLE `layer_sync_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`assetID` int(11) NOT NULL,
`jobID` varchar(100) NOT NULL,
`status` varchar(20) NOT NULL,
`errorMessage` varchar(1000) DEFAULT NULL,
`createdAt` datetime NOT NULL,
`updatedAt` datetime NOT NULL,
`version` int(11) DEFAULT NULL,
`type` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `jobID_UNIQUE` (`jobID`),
KEY `IX_assetID` (`assetID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
This data-table hasn't been used in years; but, in one of our staging environments, it has just over 23 million rows in it, which should be a sufficient amount of data for our EXPLAIN output.
Note that the table has three indices: the primary key (pkey), a unique key, and a non-unique key. When we author a generic "By Filter" function to access this table, we should only ever start our search using columns that are indexed. Attempting to start a search on non-indexed columns would lead to a full-table scan, which is prohibitive in production. This means that our "By Filter" function, in this case, should allow for id, jobID, and assetID arguments.
For the sake of the demo, my "By Filter" function has an explain argument which will dynamically insert an EXPLAIN token in the SQL. My intent is to run this locally in Lucee CFML and then manually run the executed SQL against the staging database:
ASIDE: Note how awesome it is that I can use tag islands in Lucee CFML to effortlessly include the
<cfquery>tag inside the<cfscript>tag. This is truly the best of all possible worlds.
<cfscript>
getLogByFilter( explain = true );
getLogByFilter( explain = true, id = 100 );
getLogByFilter( explain = true, jobID = "hello" );
getLogByFilter( explain = true, assetID = 100 );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I get log records using the given filtering conditions. CAUTION: If all conditions
* are omitted, the query will perform a FULL TABLE SCAN - don't be that guy!
*/
public query function getLogByFilter(
boolean explain = false,
numeric id = 0,
string jobID = "",
numeric assetID = 0
) {
```
<cfquery name="local.results" result="local.explainResult" datasource="testing">
<cfif explain>
EXPLAIN
</cfif>
SELECT
l.id,
l.assetID,
l.jobID,
l.status,
l.errorMessage,
l.createdAt,
l.updatedAt,
l.version,
l.type
FROM
layer_sync_log l
WHERE
/*
Since this is a CONSTANT CONDITION, MySQL's query planner can remove
it from the execution plan. This allows us to build-up dynamic query
conditions below without messing up our ability to leverage indices
on the table.
*/
TRUE
<cfif id>
AND
id = <cfqueryparam value="#id#" sqltype="integer" />
</cfif>
<cfif jobID.len()>
AND
jobID = <cfqueryparam value="#jobID#" sqltype="varchar" />
</cfif>
<cfif assetID>
AND
assetID = <cfqueryparam value="#assetID#" sqltype="integer" />
</cfif>
;
</cfquery>
```
// FOR THE DEMO, if the EXPLAIN argument is provided, let's output the SQL that
// was executed so that we can copy-paste it into a staging environment that has
// a large amount of data. This is important since data volume can affect the
// query planner's output).
if ( explain ) {
outputSqlAsPre( explainResult.sql );
}
return( results );
}
/**
* I clean-up and render the SQL statement that was executed by the server.
*/
public string function outputSqlAsPre( required string sql ) {
var trimmedSql = sql
.reReplace( "(EXPLAIN)\s+(SELECT)", "\1 \2" )
.reReplace( "(?m)^\t{3}", "", "all" )
.reReplace( "(?m)^[ \t]*[\r\n]+", "", "all" )
;
echo( "<pre>#trimmedSql#</pre>" );
}
</cfscript>
Since ColdFusion allows for both named and ordered arguments, it's super easy to author User Defined Functions (UDFs) in which all of the arguments are optional. This is perfect for our generic "By Filter" functions in which each argument may be used independently. Note that our WHERE condition starts with out with a semantically meaningless TRUE condition followed by a number of optional conditions that are only included based on the function invocation arguments.
When we run this ColdFusion code, we get 4 EXPLAIN statements echoed to the page. Let's assume that the first one, without any conditions, performs a full-table scan. And, instead skip right to the latter three.
When we run this against the staging environment with 23M records:
EXPLAIN SELECT
l.id,
l.assetID,
l.jobID,
l.status,
l.errorMessage,
l.createdAt,
l.updatedAt,
l.version,
l.type
FROM
layer_sync_log l
WHERE
/*
Since this is a CONSTANT CONDITION, MySQL's query planner can remove
it from the execution plan. This allows us to build-up dynamic query
conditions below without messing up our ability to leverage indices
on the table.
*/
TRUE
AND
id = ?
... we get the following output (substituting ? with a known id in the database):
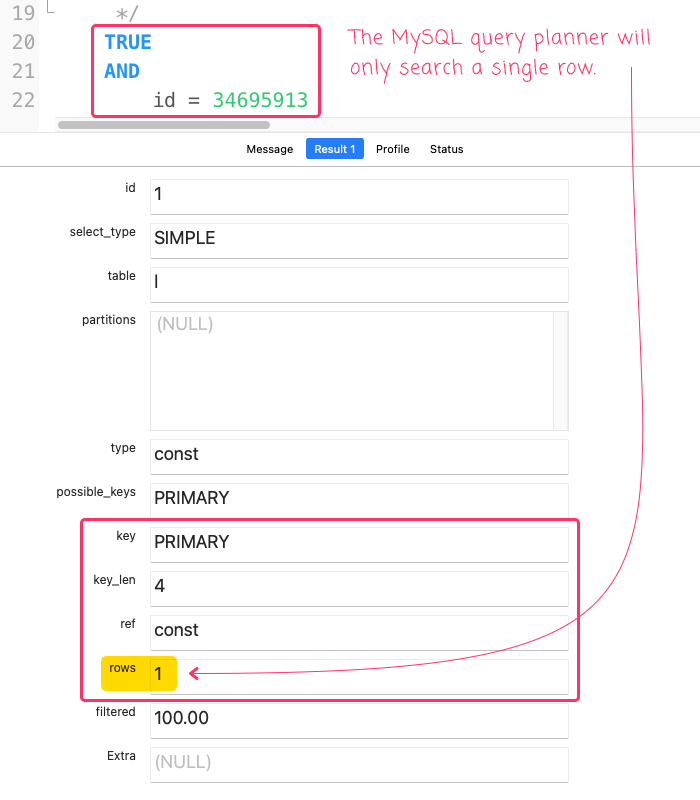
As you can see, even though we're starting our SQL statement with WHERE TRUE, the MySQL planner is ignoring this constant condition and is, instead, using the primary key index to search a single row based on the provided id value.
Similarly, when we run this against the staging environment with 23M records:
EXPLAIN SELECT
l.id,
l.assetID,
l.jobID,
l.status,
l.errorMessage,
l.createdAt,
l.updatedAt,
l.version,
l.type
FROM
layer_sync_log l
WHERE
/*
Since this is a CONSTANT CONDITION, MySQL's query planner can remove
it from the execution plan. This allows us to build-up dynamic query
conditions below without messing up our ability to leverage indices
on the table.
*/
TRUE
AND
jobID = ?
;
... we get the following output (substituting ? with a known jobID in the database):
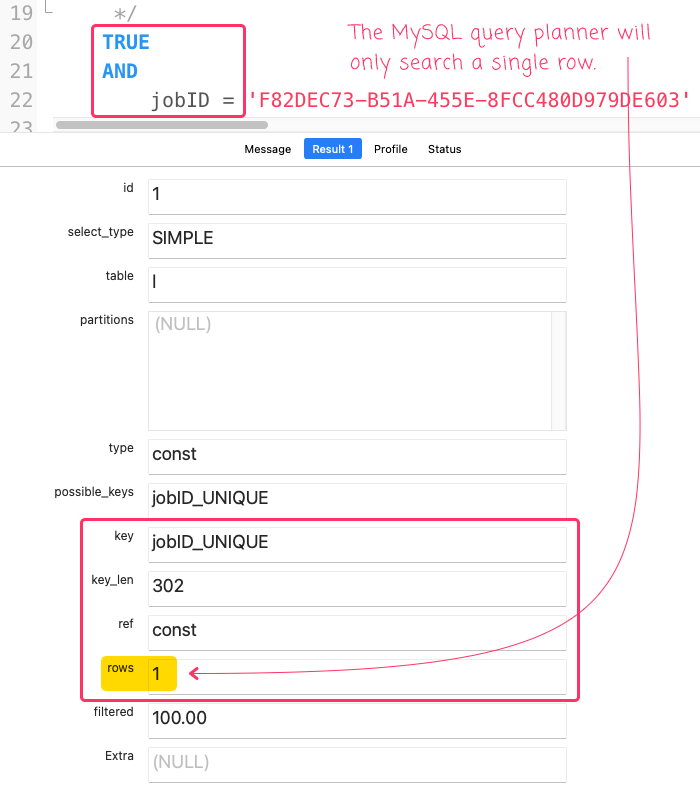
And finally, when we run this against the staging environment with 23M records:
EXPLAIN SELECT
l.id,
l.assetID,
l.jobID,
l.status,
l.errorMessage,
l.createdAt,
l.updatedAt,
l.version,
l.type
FROM
layer_sync_log l
WHERE
/*
Since this is a CONSTANT CONDITION, MySQL's query planner can remove
it from the execution plan. This allows us to build-up dynamic query
conditions below without messing up our ability to leverage indices
on the table.
*/
TRUE
AND
assetID = ?
;
... we get the following output (substituting ? with a known assetID in the database):
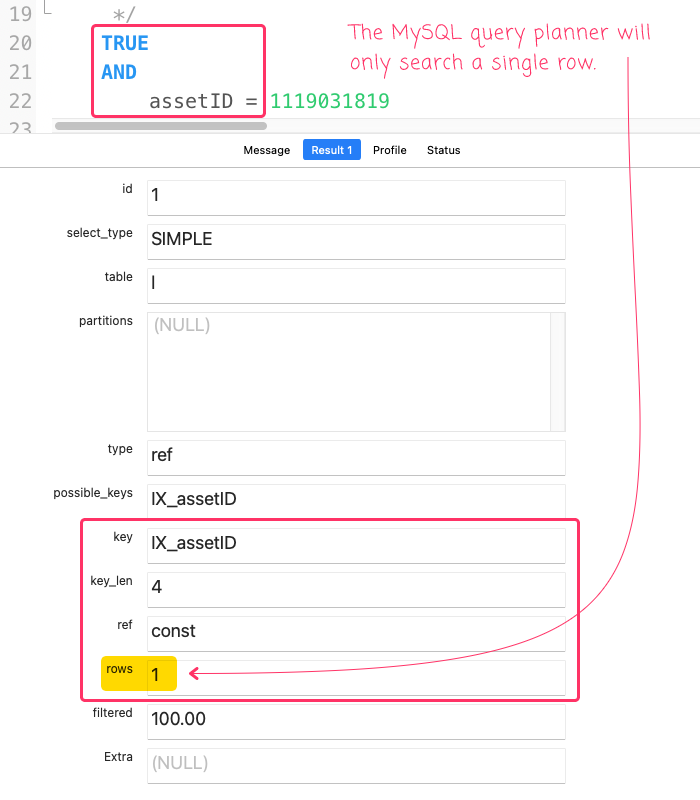
As you can see in all of these cases, the WHERE TRUE constant condition was completely ignored by the MySQL query planner. Instead, the query planner used the meaningful conditions that followed the WHERE TRUE and allowed the query to leverage the existing table indices. This allows us to author our dynamic, "By Filter" data-access functions in ColdFusion such that they are really easy to write and really easy to maintain over time.
Want to use code from this post? Check out the license.

Reader Comments
This is such an amazing tip to use:
It so much cleaner this way than having to work out whether the conditional statements should have an AND at the beginning or NOT
I always wondered why people put this in their SQL and now I know! 😀
@Charles,
Simplicity is such a key part of keeping things maintainable 💪
@Ben,
I've always used the following to start off my queries (for SQL Server):
Given it equates to TRUE, it would probably would also be excluded from the plan, but the main reason I use it is that when working in my database manager (SSMS : SQL Server Management Studio), it makes exploring and debugging queries easier, as you can comment out individual filters.
Consider the following:
I can comment out either of the useful filters, where in the following, if I wanted to temporarily exclude the id filter, I'd need to comment out id filter, and then also comment out the AND and then move createDt > '2021-10-1' to a new line:
Makes it easier for me, maybe others would find that useful too.
@Danilo,
That's a great point. I can't tell you how many times I've had to copy-paste generated SQL statements out of my CFML output and into a SQL GUI so that I could try to figure why the heck it's not giving me data 😆 Honestly, anything that makes debugging easier can be worth its weight in gold.
@Danilo,
Also, I usually use
1 = 1as well. To be honest, I only recently learned thatTRUEwas even an option. It may be MySQL-specific, not part of the base T-SQL stuff. I'm not sure.@Ben,
Just tried in SSMS with
A very quick search seems to indicate that SQL Server doesn't support boolean data types (would love to know if otherwise), and the closest is a bit type (0, 1).
@Danilo,
Ahhhhh, ok good catch. So that might be a MySQL-specific implementation. That said, your suggestion of
1=1should fill the gap quite nicely.