
A Peek Into The Interstitial Cost Of Microservices
As I've discussed recently, my team at InVision has been investing time in merging microservices back into our ColdFusion monolith. And, this week marks yet another successful subsumption of a Go microservice into our CFML juggernaut. What makes this example so interesting to me is that the target microservice was very small in scope; which, in turn, makes it easy to see the performance impact of the merger. And, what I'm seeing is a delta between the self-reported performance of the Go service and the self-reported performance of the ColdFusion service. When the numbers don't quite line up, it gives us a peek into the interstitial cost of a microservices architecture.
All of our services report a StatsD histogram / timing metric as to how long it takes to fulfill requests. Each of these metrics is tagged with the requested route / action so that we can break this internal latency down at the individual route level.
The Go microservice that I merged back into the ColdFusion monolith only exposed two routes. And, these two Go routes mapped directly onto two ColdFusion routes. Which means that if I look at the self-reported latency of the ColdFusion routes - and, more specifically the change in latency before and after the merger - I can see the difference between the "internal" cost of the Go service and the "external" cost of calling that Go service.
To get a broad sense of the latency delta, here are the AVG(p95) latency graphs (averaged across all of our Kubernetes pods) for the two self-reported times in the ColdFusion monolith:
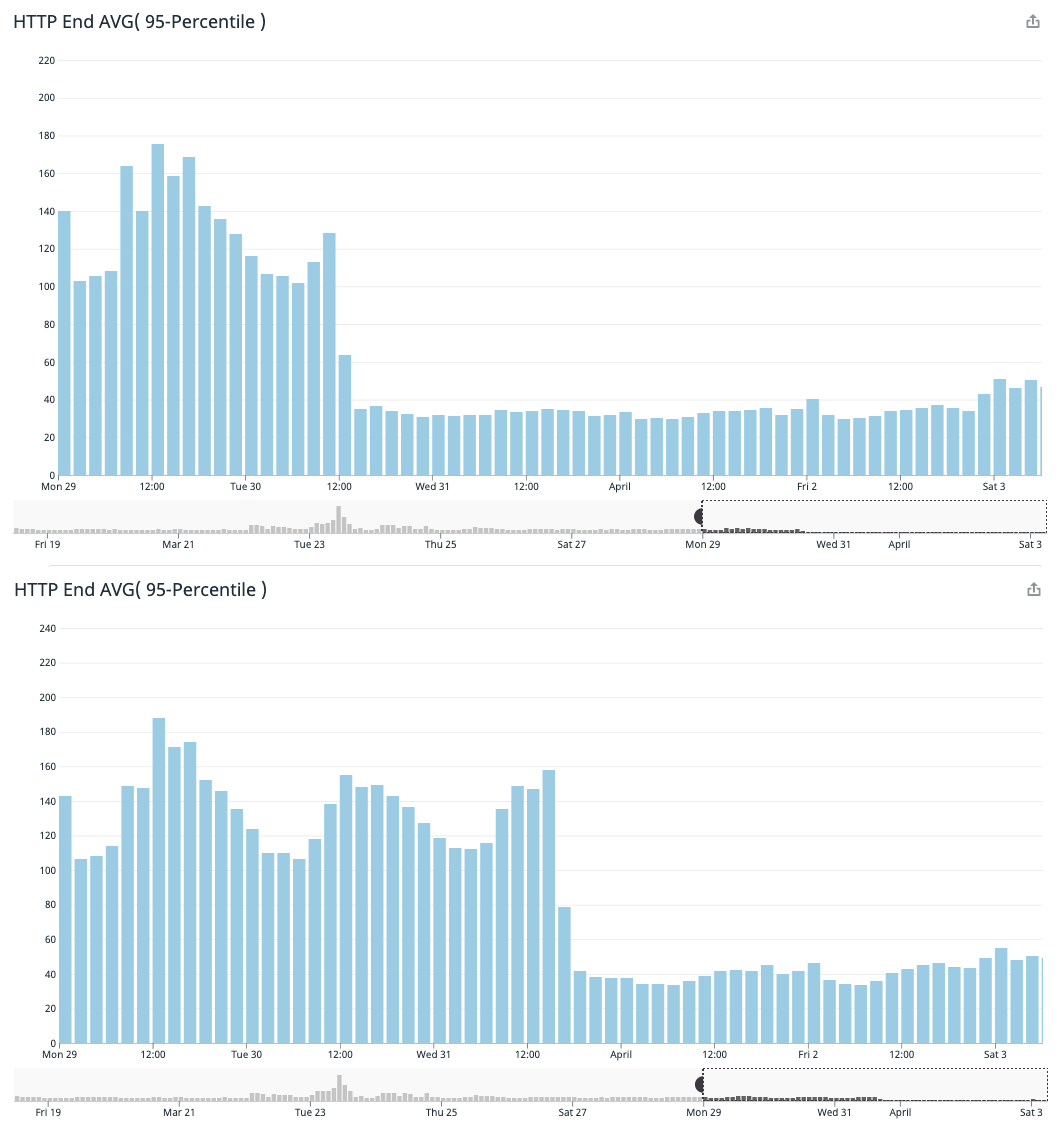
Thanks to the power of feature flags, we didn't have to cut both routes over at the same time. Instead, we used feature flags to slowly "strangle" the old Go service as we re-implemented the microservice logic inside our ColdFusion monolith. However, in both cases, we can see that when we finally stopped calling the microservice route, the self-reported latency in the ColdFusion application dropped quite significantly.
The interesting part now is to compare the difference in the drop in latency on the ColdFusion side to internal latency of the Go service. Let's look at the first route we strangled:
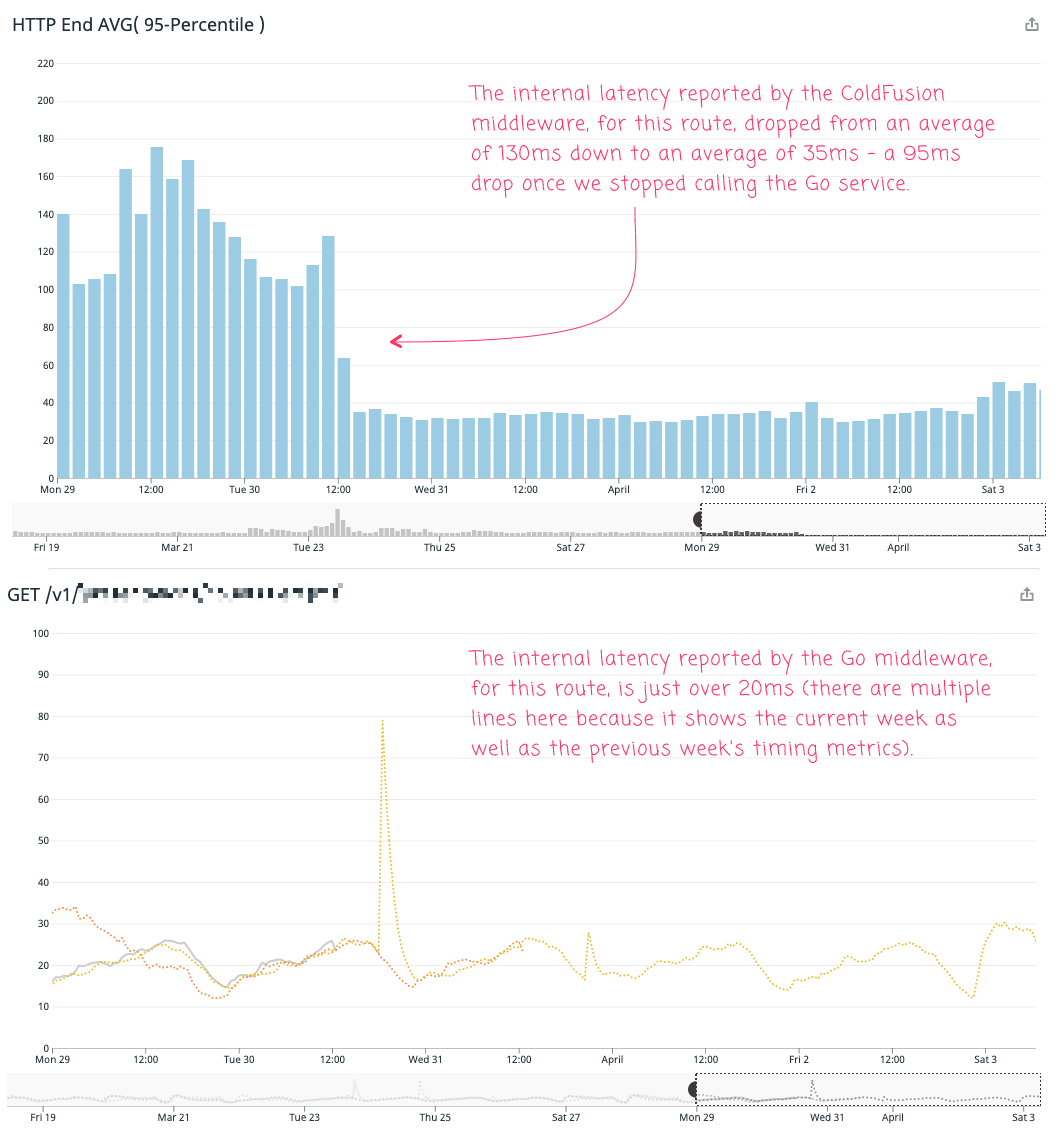
The Go service, for this route, reports a fairly consistent self-reported p95 latency of about 20ms. However, when we strangled this route into the ColdFusion monolith, the self-reported latency of the ColdFusion route dropped from about 130ms down to 35ms, a drop of about 95ms.
Now, it's not a perfect apples-to-apples comparison because we didn't just cut out the Go service - we also had to reimplement most of the logic that was in the Go service. So, we removed some HTTP latency cost while also adding some internal processing cost. But, for the sake of simplicity, let's be a little hand-wavey and just look at the raw numbers.
And, when we look at the raw numbers, comparing the 20ms internal latency of the Go service to the 95ms drop in internal latency of the ColdFusion service, we get 75ms of unaccounted for latency. That's the interstitial cost of the microservice architecture.
Now, let's look at the second route that we subsumed:
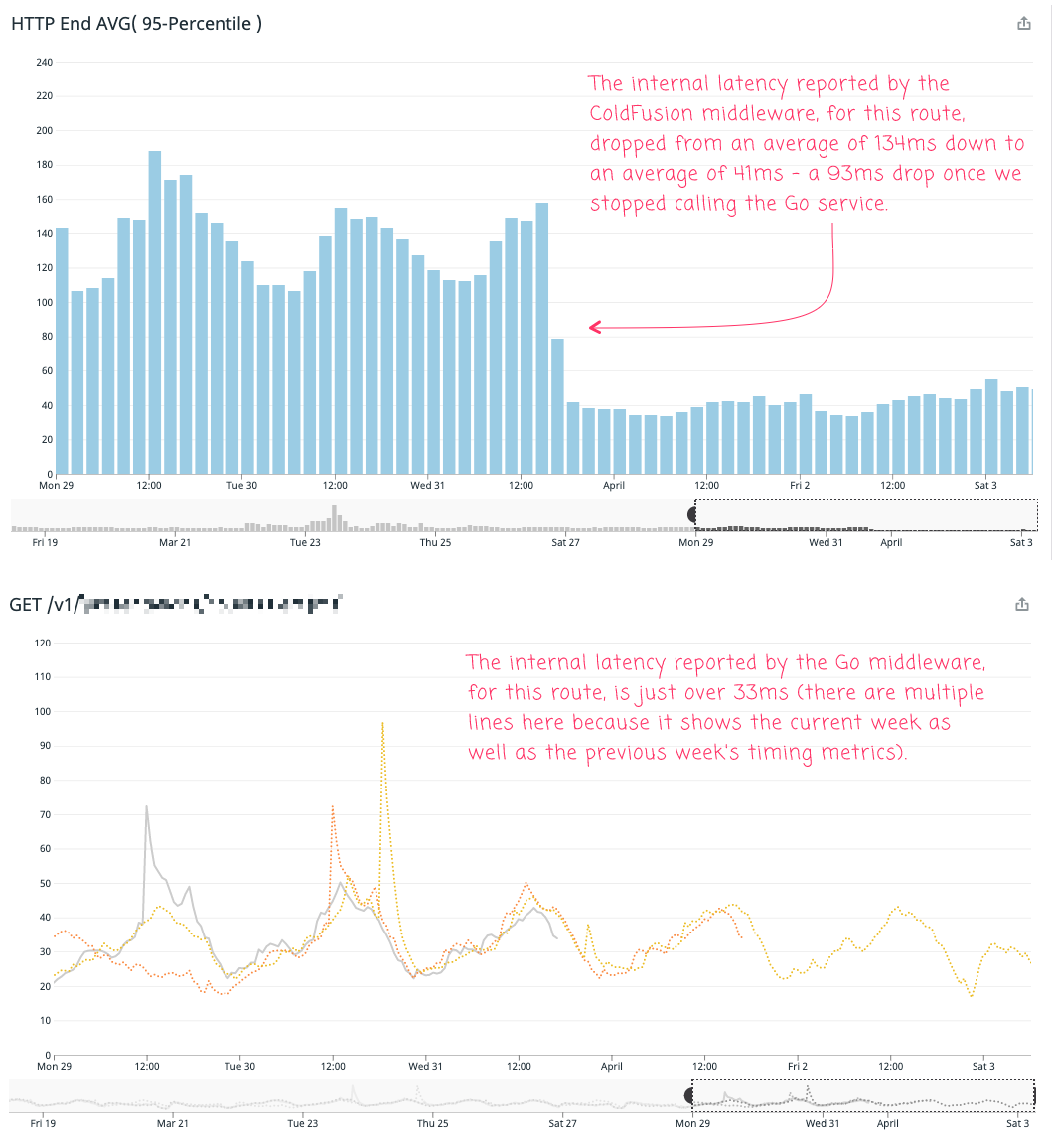
The Go service, for this route, reports a fairly consistent self-reported p95 latency of about 33ms. However, when we strangled this route into the ColdFusion monolith, the self-reported latency of the ColdFusion route dropped from about 134ms down to 41ms, a drop of about 93ms. If we compare the two, self-reported latencies, we get 60ms of unaccounted for latency. That's the interstitial cost of the microservice architecture.
So, where does this unaccounted for latency come from? I'm not sure - I'm not a "platform person" and I don't (personally) have access to any request tracing tools. But, to get electrons from one Kubernetes container to another, I assume there's HTTP Clients, DNS (Domain Name Server) resolution, load balancers, inverse proxies, etc that have to be considered. None of which is "free".
ASIDE: I feel like I recently heard Brad Wood on the Modernize Or Die podcast saying that making outbound HTTP requests in Lucee CFML was shockingly expensive. As such, it could be that majority of the unaccounted for latency was in the HTTP Client itself; but, I don't know - it's all a black-box to me.
To be clear, I am not trying to demonize microservices here. As I've said many times before, microservices are an architectural decision (just like a monolith) that comes with trade-offs. And, when you connect services with a network, you may be trading-off some performance / latency in return for independent deployability, scalability, and host of other "ilities". There's no one right answer here.
The reason this was so interesting to me is because I rarely get to see such a focused and so clearly identifiable difference between externalizing logic in a separate microservice vs. internalizing that same logic in a local module within the monolith.
Epilogue on CFHTTP Overhead in Lucee CFML
I searched around in the Lucee JIRA board and I think I found the HTTP overhead that I heard Brad Wood mention on the Modernize or Die podcast: CFHTTP calls seem to have too much OSGI overhead. Some of the ticket goes over my head; but, using FusionReactor Brad was able to see that the underlying HTTP Client is likely doing a lot more work than it has to in the latest versions of Lucee CFML. And, in fact, he's noting significant performance regressions when compared to the same tests run in the 4.x version of Lucee CFML.
Based on this information, it's definitely possible that the relatively high amount of inter-service latency that I'm seeing when Lucee calls other microservices is not the same that you would see in other server-to-service interactions. This is another reason why software architecture is highly contextual - what works for one team, one stack, and one product is not necessarily going to translate well for another team, another stack, and another product.
Reader Comments
@All,
There's a ticket on the Lucee Dev site about improved connection pooling for the CFHttp tag:
https://luceeserver.atlassian.net/browse/LDEV-2199
I don't really understand things at such a low-level; but, it's possible this would also impact the performance of having Lucee call other microservices.
I'm curious to know if there was also a operating cost calculation involved as well? And if the operating costs of micro-service vs monolith balance out in the end?
P.S. love your articles! It's nice to see a pragmatic approach to code.
@David,
Yes, there is definitely an operating cost associated with this stuff, which is part of our calculation. Our platform is fairly large and complex, so a lot of the stuff gets a bit hand-wavey. However, as someone on platform estimated for me, every microservice that we can merge back into the monolith probably saves us ~ $20K/year (when you consider all the various testing, multi-tenant, and single-tenant environments). Which, in the grand scheme of things is not that much; but, it's also not nothing either.
So, considering that pulling it into the monolith saves dollars-and-cents cost and "human maintenance" costs, I think it was worth the week-or-so of time that it took me to get it all working.