
Case Study: Removing Massive IN (ID-List) Clauses For Performance In MySQL 5.7.32 And Lucee CFML 5.3.7.47
Last week, I shared some emergency ColdFusion code that I had written and deployed that would allow me to view the processlist and kill slow queries in MySQL in one of InVision's read-replicas on Amazon RDS. After we upgraded to MySQL 5.7.32, a few of our oldest SQL queries started to perform really poorly; and, I needed to create a little breathing room for the database CPU while I refactored the problematic SQL statements. After my post last week, Martie Henry asked me what the performance bottleneck ended-up being; so, I thought I would share a quick case study about what was going on and how I "fixed it" (depending on how hard you squint).
In early December, we put InVision into "maintenance mode", took the database servers offline, upgraded to MySQL 5.7.32, and then brought everything back online. And when we did this, one our MySQL read-replica CPUs went B-A-N-A-N-A-S:
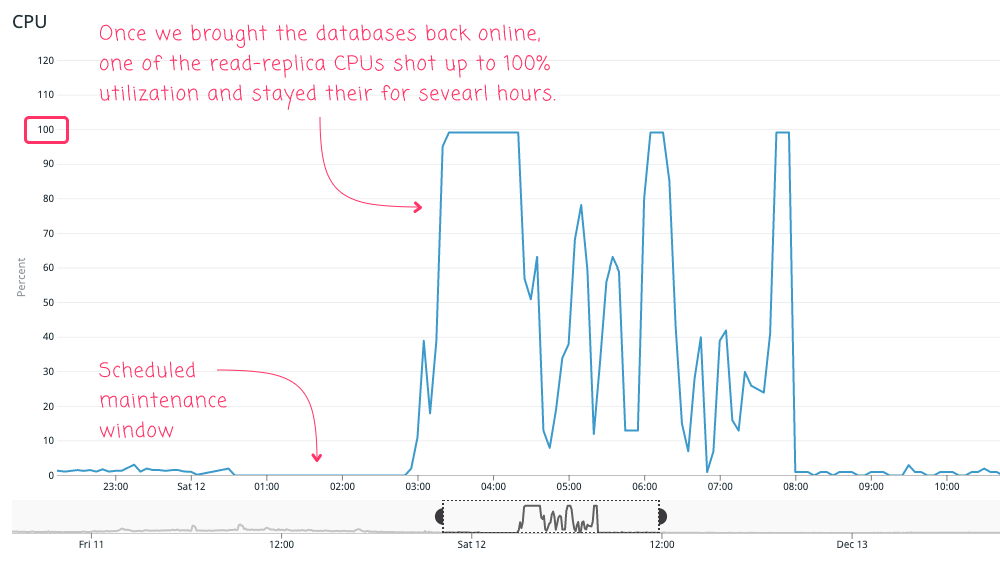
For about 5-hours one of the read-replica CPUs shot up to 100% utilization and stayed there. And, the most terrifying part of this is that the offending SQL queries were being run by just a handful of users. Essentially, a subset of queries started performing so poorly that they gave a single user the power to degrade the performance of an entire database.
Yikes!
ASIDE: I was actually paged for this CPU change; but, unfortunately, I had forgotten to turn the volume on my phone up before going to sleep. And, my PageDuty app hadn't been upgraded to use newer override settings. Lesson Learned: Keep your PageDuty app to-to-date! And, habitually check to make sure that it is still logged-in!
At the 5-hour mark, the CPU dropped down to normal weekend utilization levels (which are very low). I hadn't done anything - this was literally because the aforementioned handful of users stopped hitting that end-point. Saved by pure chance!
Upon investigation of the MySQL slow-log, I found several SQL queries that were running for thousands of seconds! And, they all had one thing in common: massive IN (id-list) clauses. And, I mean massive: some of the ID-lists were over 40K IDs long. Queries like this (truncated):
FROM
screen s
WHERE
s.projectID IN ( /* ... 40-thousand project IDs ... */ )
AND
These queries are in a very old area of the application and were built long before we had a lot of users. As such, the IN (id-list) clauses were all small and performed quite well. In those early days, I loved the use of an ID-list because it meant that we could isolate the "permissions queries" and then use the "accessible entity IDs" to drive all the other queries in a given view.
The data gathering for this application view looked like this (pseudo-code):
<cfscript>
/* ... truncated ... */
// The list of returned Project IDs is going to vary based on the role that
// the current user has in the given context; and on the member-permissions
// settings of the current enterprise. As such, we can isolate the
// application of these permissions into this one call; then, "reuse" those
// implicit permissions by driving all of the other queries on the given
// project ID list.
var projectIdList = getProjectsUserCanAccess();
// These methods can then all use the "IN ( id-list )" approach to gather
// their data without having to recheck permissions.
var projects = getProjects( projectIdList );
var members = getMembers( projectIdList );
var screenStats = getScreenStats( projectIdList );
var commentStats = getCommentStats( projectIdList );
var viewingStats = getViewingStats( projectIdList );
/* ... truncated ... */
</cfscript>
To be honest, I've known for some years that these queries were becoming problematic for performance, even on MySQL 5.6.x; however, they never became quite this bad until we upgraded to MySQL 5.7.x. It became clear that I had to put aside my current work and prioritize fixing this set of SQL queries.
And so, I sat down with Jonathon Wilson - fellow Principal Engineer at InVision - and started to consider our options. In a perfect world, we'd change the underlying data-model to be more friendly to the type of data-aggregation we were performing (see Epilogue). But, given the roadmap of the product, we didn't want to put too much work into an area of the application that wasn't going to be actively developed in the future. As such, our primary goal became "stop the bleeding", triage style.
After running some experiments on the read-replica, we discovered that the best return on investment (ROI) would likely be to remove the IN (id-list) clauses and simply "replicate" the permissions check into each subsequent SQL statement. This did not make the queries perform "great"; but, it appeared to put a limit on the upper-bound of the execution time.
In other words, it brought the "worst case" scenario down from catastrophic to poor user experience (UX). And, unfortunately, that was good enough for me (given the area of the application in question).
Of course, I didn't want to start changing a bunch of SQL queries based on a few one-off experiments. So, I chose what looked to be slowest query (based on the MySQL slow-log), and wrote an alternate version of it that replaced the IN (id-list) clause with a replicated security check. Then, I used LaunchDarkly feature flags to dynamically route some traffic to the old query and some traffic to the new query. And, of course, I add Datadog metrics to the execution pathways so that I could compare the relative performance of both approaches (pseudo-code):
<cfscript>
private array function getProjects( required string projectIdList ) {
var startedAt = getTickCount();
// If this user falls into the percentage-based roll-out of the experiment,
// route them to the new SQL query implementation.
if ( shouldUsePerformanceExperiment( userID ) ) {
var projectsQuery = gateway.getProjectsExperiment( userID );
recordTiming( "get-projects", "experimental", startedAt );
} else {
var projectsQuery = gateway.getProjects( projectIdList );
recordTiming( "get-projects", "control", startedAt );
}
/* ... truncated ... */
}
private boolean function shouldUsePerformanceExperiment( required numeric userID ) {
return( launchDarklyClient.getFeature( userID, "performance-RAIN-1234-id-list-experiment" ) );
}
private void function recordTiming(
required string metric,
required string group,
required numeric startedAt
) {
datadogClient.timing(
key = "id-list-experiment",
value = ( getTickCount() - startedAt ),
tags = [ metric, group ]
);
}
</cfscript>
As you can see, by using LaunchDarkly, I was able to slowly roll-out the SQL query refactoring to an increasing percentage of users. And, after each query, I was recording a Datadog StatsD timing / histogram metric so that I could see how each query performed in both the "control group" and the "experimental group".
Because of the low-volume of usage for this particular view in the application, and because the "worst case" performance appeared to be driven by a handful of users, I was having trouble getting good data quickly. As such, I had to let the experiment run for a while before I felt confident in the results.
However, after a few weeks of a 50% / 50% rollout, it became quite clear that the experimental query was outperforming the control query by a massive degree:
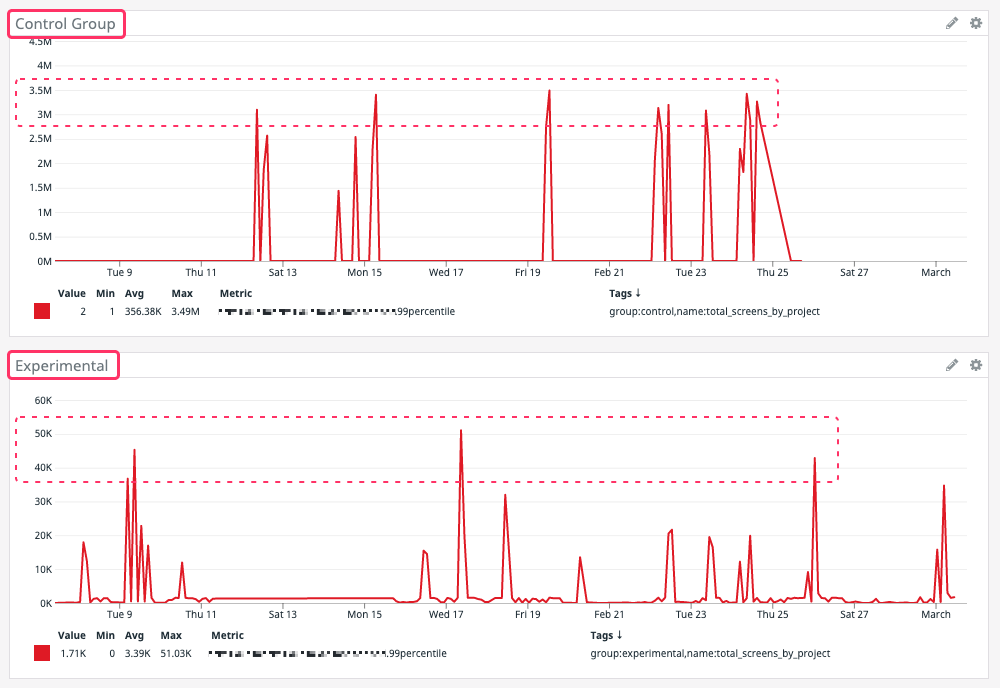
If you click into that image, you can see that the worst case for the control query (ie, the original query) was around 3.5M milliseconds (or just under 1-hour) to completion. The worst case for the experimental query, on the other hand, was around 50K milliseconds (or about 50-seconds). To be clear, 50-seconds is still not great performance. However, it is not catastrophic performance, which was the main goal of this experiment.
Of course, seeing this SQL refactoring approach work on one query didn't quite sell me. I wanted to move slowly and methodically. So, I took this one approach and I applied it to a few more of the slow SQL queries in the same view. Which means, I wrote an "experimental" version of 4-more queries and then put them all behind the same LaunchDarkly feature flag:
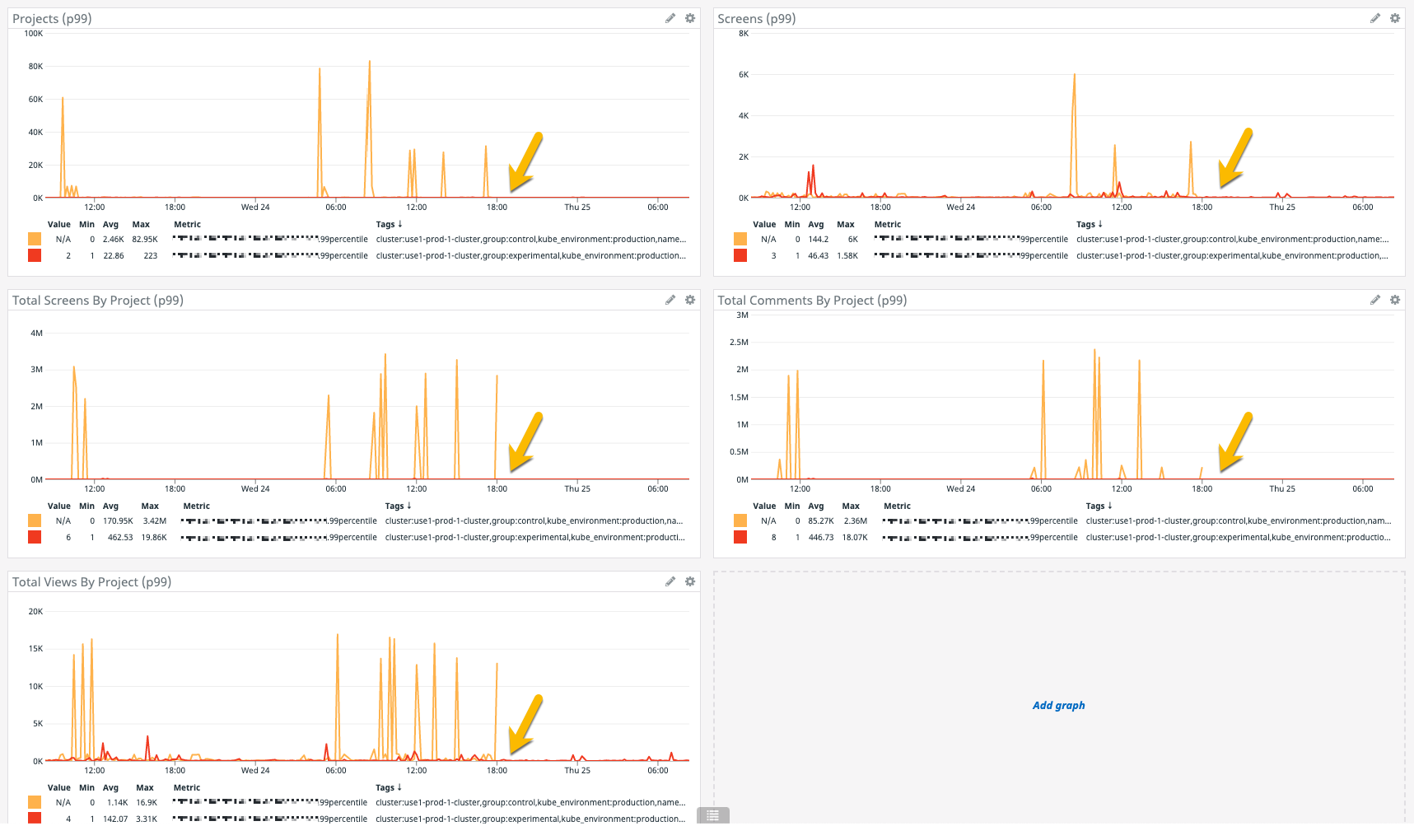
In each of these SQL queries, the experimental group with the replicated security checks drastically outperformed the control group with the IN (id-list) clauses. In this Datadog screenshot, the yellow-arrows are the moment in time in which I moved the LaunchDarkly roll-out to 100% of users; which is why there are no "control group" spikes after that on the graphs.
At this point, I decided that the experiment had conclusive results; and, I committed the "replicated security checks" to the 12 queries that had been using the IN (id-list) clause in this particular application view. Of course, I didn't want to write the same SQL 12-times; so, I moved the shared SQL into its own ColdFusion function and then interpolated the common SQL into each of the 12-queries.
I've looked at this before, but one of the coolest features of the CFQuery tag is that you can spread SQL and CFQueryParams across multiple function calls in Lucee CFML. And, that's exactly what I did here. I ended up with SQL queries in which the initial FROM clause referenced a function call, includeAccessibleProjectsSQL().
The following is a much simplified version of what is being executed; but, hopefully it is enough to illustrate the approach of using the common SQL to define the repetitive access controls:
<cfscript>
public query function getScreens(
required numeric userID,
required numeric companyID
) output = true {
```
<cfquery name="local.results">
SELECT
/* columns */
FROM
-- NOTE: This common SQL creates aliases for three tables:
-- * cmp - company
-- * p - project
-- * pm - project_membership
#includeAccessibleProjectsSQL( userID, companyID )#
INNER JOIN
screen s
ON
s.projectID = p.id
</cfquery>
```
return( results );
}
/* ... truncated ... */
private void function includeAccessibleProjectsSQL(
required numeric userID,
required numeric companyID
) output = true {
```
<!--- FROM --->
company cmp
INNER JOIN
project p
ON
(
cmp.id = <cfqueryparam value="#companyID#" sqltype="integer" />
AND
p.companyID = cmp.id
)
INNER JOIN
project_membership pm
ON
(
pm.projectID = p.id
AND
pm.userID = <cfqueryparam value="#userID#" sqltype="integer" />
AND
pm.endedAt IS NULL
)
```
}
</cfscript>
Essentially, the includeAccessibleProjectsSQL() function defines the first three tables of each CFQuery SQL statement. And, as you can see, the getScreens() function is referencing p.id - an alias defined in the common SQL - in its own INNER JOIN clause.
With this approach applied to the 12 SQL queries that are required to aggregate the data for this view in the application, we can see that it had a non-trivial affect on the read-replica database CPU:
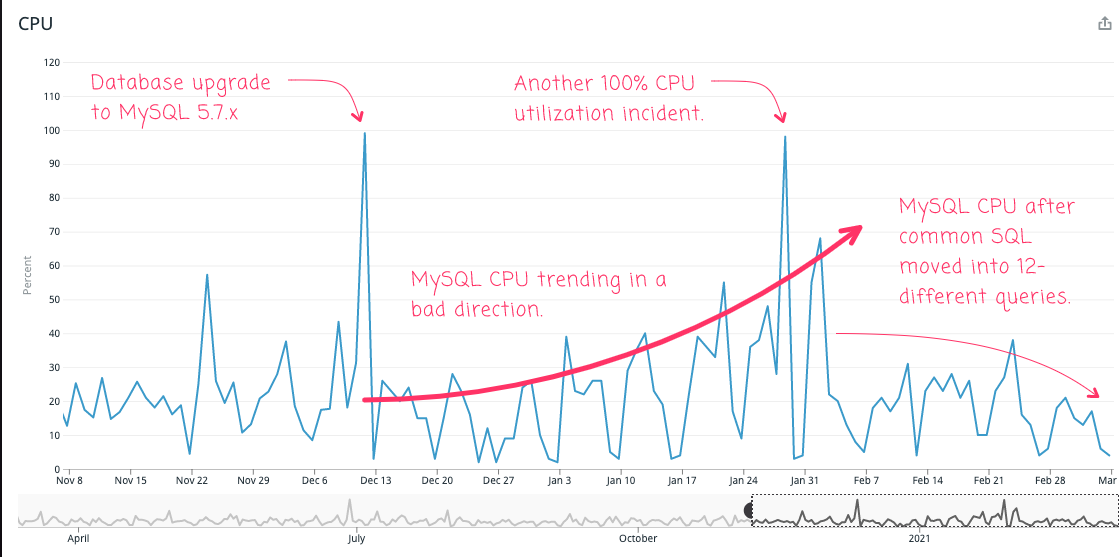
Obviously, the upward trendline is as much a guess as it is an observation - who knows what it would have done over time. What I can say is that just before I started rolling out the experiments, we hit another 100% CPU utilization incident; so, I do believe in my heart that the situation was a ticking time-bomb. And, as we can see from the CPU graphs, now that all of the changes have been applied, the performance of this page is actually slightly better than it had been before the database upgrade.
I'm still quite bully on the use of IN (id-list) style SQL queries. At smaller-scale, with better-constructed user interfaces (UIs), an IN (id-list) clause can really simplify data-access patterns. It's just that it has to be applied in a context that has bounded data. The issue with the SQL queries that I refactored is that they were never designed to be bounded; and therefore never designed to scale over time.
Epilogue: Aggregated Data vs. Aggregation Of Data
The root cause of the performance problem in this case-study is that the underlying data access is fundamentally wrong. These are really old queries that are powering a really old portion of the application that is a hold-over from when we were a small team working with a small user-base. And, because we weren't concerned about "scaling" at the time, these SQL queries are all perform aggregation of data on-the-fly. As the volume of data has grown over the past decade, these on-the-fly aggregations have become slower and slower.
Really, we shouldn't be performing on-the-fly aggregations at this scale, we should be querying aggregated data. That is, data that has already been queried, aggregated, and stored in the required format. Kind of like a materialized view within the same database. This way, data access for this user interface would become a simple, high-performance look-up.
The question then becomes, is it worth prioritizing a larger refactoring in lieu of feature development? The sad but pragmatic answer is "No". The fire has been put out. Yes, some outlier users will experience slow responses on this page; but, the majority of users will not; and the database is no longer getting hammered. Which means, at the macro level, engineering time is likely better spent on new features that will drive higher adoption.
Want to use code from this post? Check out the license.

Reader Comments