
Superficial Performance Comparison Between ColdFusion Query-of-Queries (QoQ) And Array Functions In Lucee CFML 5.3.3.62
CAUTION: You should always take a controlled performance comparison with a grain of salt. These were not done in a production environment; they were not done under load; and the performance at small scale for either approach is significantly fast. Worrying about your choice here is not merited until you have identified an actual bottle-neck within your production application that you are trying to optimize.
Caveats aside, a few people on Twitter asked me if ColdFusion Query-of-Queries (QoQ) are actually slower than Array-based collation. Instinctually, I think it would make sense that Array-based methods are faster since they don't have parse SQL statements; and, their execution is less abstract. But, instincts are not nearly as interesting as numbers. So, I wanted to run a superficial performance comparison between a ColdFusion Query-of-Query example and an Array-based approach that attempts to gather the same data in Lucee CFML 5.3.3.62.
To be clear, ColdFusion Query-of-Queries are not some massive performance hog. They are fast. And, there's no sense in trying to avoid query-of-queries unless you have determined that it makes sense in a given context. In fact, in order to amplify any meaningful difference in performance, I have to run trials that contain 1,000 queries.
First, let's look at the Query-of-Query example. Borrowing the data from my previous post, I am attempting to JOIN and ORDER BY two different queries:
<cfscript>
friends = queryNew(
"id,name,isBFF",
"integer,varchar,tinyint",
[
{ id: 1, name: "Kim", isBFF: true },
{ id: 2, name: "Hana", isBFF: false },
{ id: 3, name: "Libby", isBFF: false },
{ id: 4, name: "Dave", isBFF: true },
{ id: 5, name: "Ellen", isBFF: false },
{ id: 6, name: "Sam", isBFF: false }
]
);
phoneNumbers = queryNew(
"id,friendID,phone,type",
"integer,integer,varchar,varchar",
[
{ id: 1, friendID: 1, phone: "555-1111", type: "mobile" },
{ id: 2, friendID: 6, phone: "555-6666", type: "home" },
{ id: 3, friendID: 3, phone: "555-3333", type: "home" },
{ id: 4, friendID: 1, phone: "555-1113", type: "pager" },
{ id: 5, friendID: 4, phone: "555-4444", type: "mobile" },
{ id: 6, friendID: 5, phone: "555-5555", type: "mobile" },
{ id: 7, friendID: 1, phone: "555-1112", type: "home" },
{ id: 8, friendID: 6, phone: "555-6667", type: "mobile" }
]
);
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// Number of experiments to run. This will allow us to see variations in performance
// across several trial.
loop times = 10 {
startedAt = getTickCount();
// Number of "queries" to execute during each experiment. No matter what type of
// data access we perform, at a small scale the difference is going to completely
// negligible. As such, in order to amplify any difference, we have to perform a
// number of trial to help simulate some degree of load on the server.
loop times = 1000 {
results = queryExecute(
sql = "
SELECT
( f.id ) AS friend_id,
( f.name ) AS friend_name,
( f.isBFF ) AS friend_isBFF,
( p.id ) AS phoneNumber_id,
( p.friendID ) AS phoneNumber_friendID,
( p.phone ) AS phoneNumber_phone,
( p.type ) AS phoneNumber_type
FROM
friends f,
phoneNumbers p
WHERE
p.friendID = f.id
ORDER BY
f.name ASC,
f.id ASC
;
",
options = {
dbtype: "query"
}
);
} // END: Inner Loop.
duration = ( getTickCount() - startedAt );
dump(
label = "Query-of-Query with JOIN, WHERE, ORDER BY",
var = numberFormat( duration, "," )
);
} // END: Outer Loop.
</cfscript>
As you can see, we are performing 10-trials with 1,000-iterations each. This volume is done in order to amplify the potential difference to a discernible level. And, when we run the above ColdFusion code, we get the following output:

NOTE: Before taking this snapshot, I refreshed the page about 20-times in order to give the CFML platform time to optimize all of the code execution pathways.
Ok, now that's try to gather the same data using Array function. Again, we're performing 10-trials with 1,000-iterations each:
<cfscript>
friends = [
{ id: 1, name: "Kim", isBFF: true },
{ id: 2, name: "Hana", isBFF: false },
{ id: 3, name: "Libby", isBFF: false },
{ id: 4, name: "Dave", isBFF: true },
{ id: 5, name: "Ellen", isBFF: false },
{ id: 6, name: "Sam", isBFF: false }
];
phoneNumbers = [
{ id: 1, friendID: 1, phone: "555-1111", type: "mobile" },
{ id: 2, friendID: 6, phone: "555-6666", type: "home" },
{ id: 3, friendID: 3, phone: "555-3333", type: "home" },
{ id: 4, friendID: 1, phone: "555-1113", type: "pager" },
{ id: 5, friendID: 4, phone: "555-4444", type: "mobile" },
{ id: 6, friendID: 5, phone: "555-5555", type: "mobile" },
{ id: 7, friendID: 1, phone: "555-1112", type: "home" },
{ id: 8, friendID: 6, phone: "555-6667", type: "mobile" }
];
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// Number of experiments to run. This will allow us to see variations in performance
// across several trial.
loop times = 10 {
startedAt = getTickCount();
// Number of "queries" to execute during each experiment. No matter what type of
// data access we perform, at a small scale the difference is going to completely
// negligible. As such, in order to amplify any difference, we have to perform a
// number of trial to help simulate some degree of load on the server.
loop times = 1000 {
phoneNumberIndex = groupBy( phoneNumbers, "friendID" );
results = friends
.map(
( friend ) => {
return({
friend: friend,
phoneNumbers: ( phoneNumberIndex[ friend.id ] ?: nullValue() )
});
}
)
.filter(
( result ) => {
return( result.keyExists( "phoneNumbers" ) );
}
)
.sort(
( a, b ) => {
if ( a.friend.name != b.friend.name ) {
return( a.friend.name.compareNoCase( b.friend.name ) );
}
return( ( a.friend.id < b.friend.id ) ? -1 : 1 );
}
)
;
} // END: Inner Loop.
duration = ( getTickCount() - startedAt );
dump(
label = "Arrays with MAP, FILTER, SORT",
var = numberFormat( duration, "," )
);
} // END: Outer Loop.
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I return a Struct that groups the given collection based on the given key. Each
* key-value is an Array that contains all of the items that match the same key-
* value.
*
* CAUTION: Every item in the collection is ASSUMED to have a NON-NULL reference to
* the given key. This makes sense for an in-memory JOIN.
*
* @collection I am the Array of Structs being grouped.
* @key I am the key on which to group items in the collection.
*/
public struct function groupBy(
required array collection,
required string key
) {
var index = {};
for ( var item in collection ) {
var keyValue = item[ key ];
// This expression attempts to get the current group indexed by the given
// key-value. However, if it doesn't exist, we're using the "Elvis"
// operator to "Assign and Return" a new Grouping for this key-value.
var group = ( index[ keyValue ] ?: ( index[ keyValue ] = [] ) );
group.append( item );
}
return( index );
}
</cfscript>
After refreshing this code 20+ times, we get the following output:
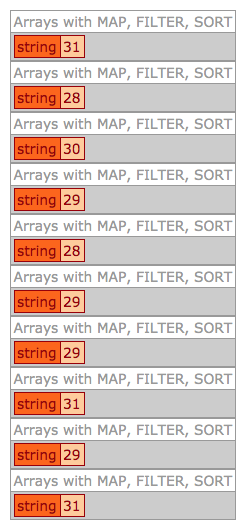
As you can see, executing the Query-of-Queries trials took about 73ms on average where as executing the Array-based equivalent took about 33ms on average. So, in this superficial performance comparison, the ColdFusion Query-of-Queries approach is roughly 2-times slower. But, again, from a pragmatic point of view, this difference is going to be negligible in most circumstances. You would only begin to care about the difference when you have a production app; you've measured and identified a bottleneck; and, you're looking for ways to optimize a hot pathway within the execution path.
Want to use code from this post? Check out the license.

Reader Comments
thanks man. you do good work.
@B,
Thank you, kindly :D I'm really loving all the Array-member-methods in Lucee. Making a lot of things very nice to work with.