
REST And GraphQL Are Not Your Only Choices When Building An HTTP API
I don't believe that the web development community is having an honest discussion about GraphQL. This is because, GraphQL is almost exclusively presented as an alternative to REST (Representational State Transfer). And, while GraphQL may remove points-of-friction found in REST, the dishonesty is rooted in a false and implicit dichotomy when it comes to API implementations. The truth is, GraphQL and REST are not your only choices when it comes to building an HTTP-based API. And while this may be obvious to many experienced web application developers, it is not nearly as obvious to newcomers. As such, I think that the community should be striving to have a more nuanced conversation.
At its core, an HTTP API is just a means to get data from a Producer to a Consumer. In much of today's thick-client world, an HTTP API is consumed via AJAX (Asynchronous JavaScript And JSON); and, delivers data from the Server to the Browser (often as part of a Single-Page Application, or SPA).
In this thick-client world, there's a good chance that a single team owns both the Client and the Server implementations. This is part of the value-proposition in the BFF (Backend-For-Frontend) pattern; and, it means that the decisions around an API are nothing more than a well-encapsulated implementation detail:
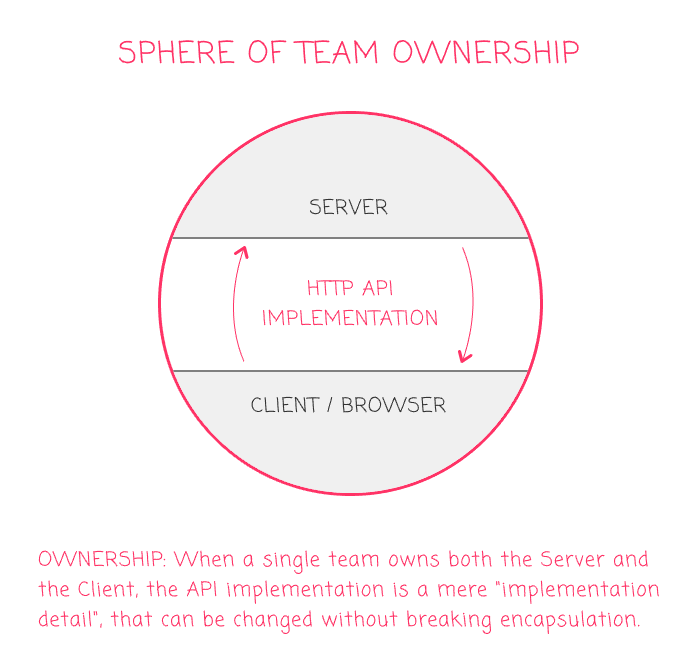
In this context: AJAX, WebSockets, long-polling, full page reloads, iframes, dynamic Image sources - your choices don't really matter. You can even have a combination of several different approaches. Whatever works well for your team and allows you to deliver value to your user-base is the implementation - or implementations - that you should go with.
That said, you can use AJAX without having to use either GraphQL or REST. For example, you could use AJAX to consume a static JSON (JavaScript Object Notation) file. Imagine a build-process that writes a list of Country Codes to a country_codes.json file? Or, a build-process that writes localized strings to a series of language-based JSON files, lang_${ language }.json.
In my primary application - inside my sphere of ownership (see graphic above) - I often create API end-points that are custom tailored for a specific user-interface. When I have a new interface, I create a new end-point. It's not REST. It's not GraphQL. It's just an HTTP-based AJAX call that returns a JSON payload. And, as the needs of the front-end continue to evolve, I alter the implementation of my server-side end-points to meet those needs.
Because my team owns both the front-end and the back-end, this approach proves fast and extremely flexible. It makes it easy to run isolated experiments without breaking any unrelated end-points; it makes it easy to use different data-sources - such as a read-replica - for pages that can cope with staleness; and, it makes it very easy to delete cohesive vertical slices in the application logic (ie, deleting both front-end and back-end code).
I don't use GraphQL in this context because it doesn't solve a problem that my team actually has. The same is true for REST. Both GraphQL and REST would - in this context - add structures and abstractions that would likely slow us down or, at the very least, limit some of our flexibility.
That is not to say that my approach is better than GraphQL or REST; it is only to say that in my particular context, neither GraphQL nor REST solve a problem. And, that's part of the point: context is king. My team owns the full-stack context, so we use an API implementation that best meets our needs. If I were building a Public API, or an inter-service API - in which I didn't own the Consuming context - I certainly wouldn't be building custom end-points - that would be crazy-pants!
Both REST and GraphQL can be good options for an API implementation. But, they are certainly not your only choices when it comes to HTTP APIs. You should choose an implementation - or mix of implementations - that best fit your context, your sphere of ownership, and the skill-set of your team. I understand that GraphQL solves many points-of-friction that are present in REST; but, as a community, we shouldn't be presenting GraphQL and REST as "either-or" options. The conversation, for the sake of up-and-coming web developers, should be more contextual and more nuanced.
Reader Comments
Amen sista! Preach!
Sounds like you create individual, app-specific RPC APIs, which I think is smart if you are your own customer. REST/GraphQL make a lot more sense for SASS apps, where your content is the service.
@Chris,
Yeah, the moment you expose an API to the general public (or to an internal public), the games totally changes. But, it's good to understand that these are two very different types of constraints and context and have different demands. There doesn't have to be "one best solution" that works for everything.
Agree entirely. Clearly where an API is to be used by others there is a need for an interface that follows industry standards and where responses to calls from client to server don't change over time. For a system that is not providing an external interface there is more flexibility in how the client and server interact.
One benefit of using GraphQL (and REST) could be that the complete data structure needs to be defined in a coherent way which could encourage better design of the back end data structure.
@Simon,
Encourging better design is always appreciated. One of the things that has really come back to bite my team(s) is when people slowly add cruft to the underlying database queries in order to satisfy some front-end requirements. So, you start out with a simple query like:
And, let's say this powers some UI that shows the user. Then, the Design team wants to add something to the UI that shows the date the user signed-up, like a "Member since X" kind of note. So, some developer looks that the code, sees that query, and just thinks, "Oh, I know, I'll just add to this query". And it becomes:
And then, it just balloons from there, where each developer keeps adding cruft to the one underlying query until it is bloated and gross and can't be refactored easily.
So, driving some sort of better, more unified model would, in my mind, lead to much better query consistency.
I know that's not necessarily what you were talking about :D but, I just had to get that off my chest.