
Considering Index Design When Using A Nullable DateTime Column To Record A Scheduled Action
I had a lot of fun writing yesterday's post on creating a composite index using ancestral keys in a hierarchical database. Index design - and database schema design in general - is fascinating to me. I've been using relational databases for years and I'm still learning how to leverage them most effectively. In the spirit of that journey, I wanted to share another thought that I've had recently about index design, this time around the use of a nullable DateTime column used to record the execution of a scheduled action. To me, this is an interesting use-case because the order of the columns in the composite index is opposite of what it is in both the MySQL table and in my mental model.
To set the context for this exploration, I'm building an internal scheduling system at work. Essentially, I have a table that keeps track of notifications that have to be sent. The records in this table are created explicitly by an internal user action; and then, they are "processed" by an ongoing scheduled task.
The scheduling and notification algorithm is controlled by two columns:
scheduledAt- A non-nullable DateTime column that indicates when the given notification should be sent.sentAt- A nullable DateTime column that indicates if and when the given notification was sent by the scheduled task.
When these records are inserted into the database, the scheduledAt column is defined as some future date and the sentAt column is set to NULL. The NULL value indicates that the notification is "pending"; and, it's up to the scheduled task to locate these records and send them at the appropriate time.
When I first went to author the scheduled task query that locates the "overdue" notifications, my WHERE column looked something like this:
SELECT
*
FROM
demo_notification n
WHERE
n.scheduledAt <= '2019-07-10' -- Indicates "overdue".
AND
n.sentAt IS NULL -- Indicates "pending" state.
This WHERE column matches the voice in my head: "Find the notifications that are overdue and have not yet been processed". And, at first, I created an index that aligned with this mindset:
KEY `IX_byDate` ( `scheduledAt`, `sentAt` )
The problem with this approach is that my query is using a range condition on the first column of the index and then an equality comparison on the second column of the index. At least in MySQL, this doesn't work. MySQL can only consume a composite index prefix up to and including a range condition. It then ignores everything after the range (in terms of index consumption). So, in this case, the sentAt condition is being checked by Using Where only after the rows are identified by the index range condition:
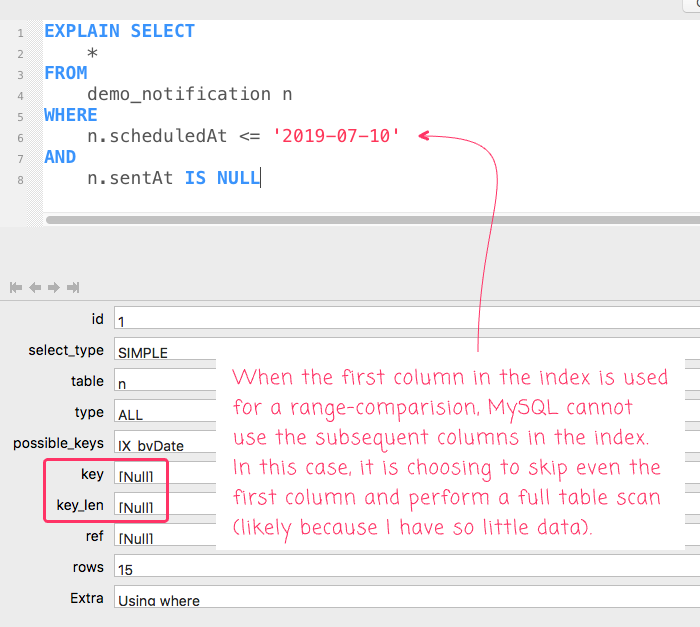
In this case - probably because I have so little data, and because the range isn't very limiting - MySQL is bypassing the index altogether and just performing a full table scan.
In order to create a better index for my scheduled notifications algorithm, we have to reverse the way we think about gathering the data. Instead of locating the "overdue" notifications first, we have to focus on locating "unprocessed" records first. The new voice in my head then becomes: "Find the notifications that haven't been processed and then limit that to the ones that are overdue".
With this new mindset, the order of the columns in the composite index is flipped, with sentAt being first:
KEY `IX_byDate` ( `sentAt`, `scheduledAt` )
And, we can also flip the conditions in the SQL query as well. Though, to be clear, this is just a personal preference that defines "intent" - to line the SQL conditions up with the way in which the MySQL query optimizer will consume them. Technically, the query optimizer will do this for you behind the scenes:
SELECT
*
FROM
demo_notification n
WHERE
n.sentAt IS NULL -- Indicates "pending" state.
AND
n.scheduledAt <= '2019-07-10' -- Indicates "overdue".
As you can see, in this version of the query, the equality condition is being performed on the first column of the index, sentAt, while the range condition is being performed on the second column of the index, scheduledAt. This allows MySQL to use the composite index to perform both comparisons:
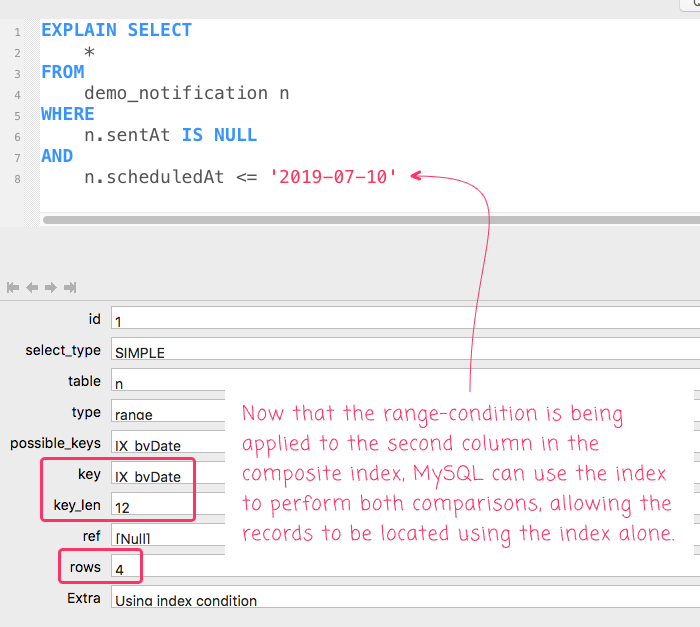
To me, this is a really fun SQL exploration because it forces you to think deeply about how the data in your application will be accessed; and then, to modify that thinking based on the constraints of the underlying database engine. In this case, I had to flip the order of the columns in my index because my data was being accessed using a range condition. This is sharp contrast to my normal ID-based conditions that can be structured in closer alignment with my mental model.
I just love SQL.
Want to use code from this post? Check out the license.

Reader Comments
Ben. I never knew this. Thanks for the heads up. I'd be interested to know why MySQL will not process other indexes after a RANGE column in a composite index? This seems a bit weird to me. Possibly a bug? I guess, if this is the case for MSSQL, Oracle etc, then it is probably normal behaviour.
@Charles,
I'm not 100% on this, but I believe this is more-or-less the way other SQL engines use indexes as well. I did a little Googling and found this post -- https://www.vividcortex.com/blog/the-left-prefix-index-rule -- that generalizes it for most databases:
I think it has to do with how the index is structured internally. But, that's a lot more lower-level than I understand. I just sort of accept that it stops at the first range-condition :D