
Playing With RegExp Named Capture Groups In Node 10
A couple of weeks ago, at the NYC Node.js Meetup, Franziska Hinkelmann went over the exciting new features of Node 10, which had just recently entered Long Term Support (LTS). Of the features that she listed, the one that really caught my ear was the addition of "named capture groups" in the Regular Expression engine. I've never used named capture groups before - not in JavaScript, not in any other language (that I can remember). As such, I wanted to just play around a little bit - you know how much I freakin' love Regular Expressions. And, if nothing else, help spread the word about this new hawtness in Node 10 and V8 version 6.8.
There's very little information on the web about RegExp and named capture groups in JavaScript that I can see. The Mozilla Developer Network (MDN) doesn't have anything at all. Regular-Expression.info has some generic information (much of which doesn't apply to JavaScript). Really, the only solid source of information that I could find was from the master-blaster, Dr. Axel Rauschmayer.
Dr. Axel Rauschmayer's post is really thorough. So, I'm not even going to bother digging into the nitty-gritty of how named capture groups work in RegExp and JavaScript - I'll simply defer to him. For this post, I just want to try it out for myself and show people that it is possible.
In Regular Expressions, a capturing group is defined by a set of parenthesis that wrap around a portion of the RegEx pattern. These capturing groups are generally referenced by index, starting a "1" and counting open parenthesis from left-to-right.
A "named" capturing group side-steps the need to count open parenthesis by associating a name with a given group. The name is defined with a "?<label>" syntax and is the first token inside of a capturing group:
RegExp: hello (?<name>.+)
In this case, the first capturing group (by index) is also given the label, "name". Because of this, the ".+" value can subsequently be referenced by "name" in the resulting match.
NOTE: You can also use named capturing groups in back-references and replacement references. I will, however, defer to Rauschmayer's post on that matter - I have not tested it myself.
To see this in action, I first tried to use the String.prototype.replace() method:
| var input = "This is how we do it"; | |
| // In the above string, we're going to match on any string of WORD characters followed | |
| // by any string of NON-WORD characters. | |
| var pattern = /(?<word>\w+)(?<optionalNonWord>\W+)?/gi; | |
| // When using named-groups, a special Groups object is passed to the match-handler as the | |
| // last argument. However, since the handler is variadic, it's a bit of pain to locate | |
| // the groups object. As such, we're going to collect all arguments as a single array and | |
| // then just locate the Groups as the last item in the array. | |
| function handleMatch( ...params /* $0, $1, $2 offset, input, groups */ ) { | |
| // The groups is the last argument in the variadic signature. | |
| var groups = params.pop(); | |
| console.log( groups ); | |
| return( groups.word ); | |
| } | |
| var result = input.replace( pattern, handleMatch ); | |
| console.log( "RESULT:", result ); |
In this code, I am defining a Regular Expression pattern that contains two named capturing groups: ?<word> and ?<optionalNonWord>. I'm then using a Function-based replace() call to iterate over the matches. When using a Function-based iterator, there is a special "groups" argument that is included in the callback invocation. This groups argument contains the named captures.
Instead of identifying all of the arguments in the variadic callback, I'm just gathering them all up in a "rest" operator and popping off the last value - the "groups" collection. And, when we run this code, we get the following console output:
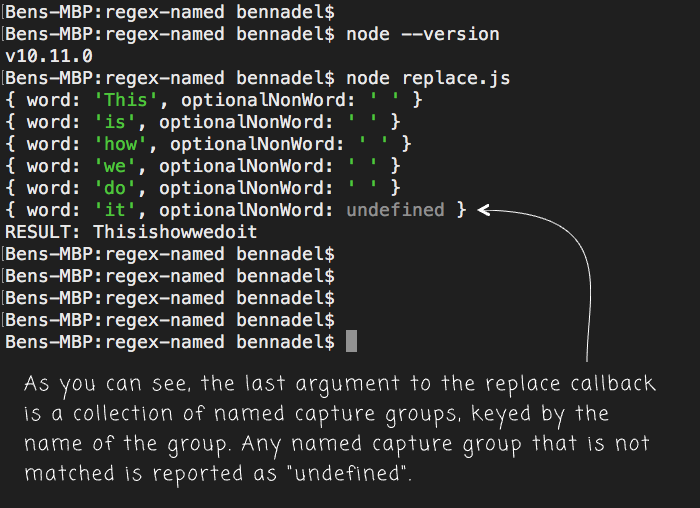
As you can see, in each iteration, the groups collection contains the values of the named capture groups. And, any named capture group that is not matched in a given iteration is defined as undefined.
That's pretty cool! But, I wanted to take it up a notch and look at the RegExp.prototype.exec() method. This method is a bit more intense, and uses a stateful RegExp instance. To try something fun, I took an old attempt at parsing CSV data in JavaScript using Regular Expressions and updated it to use named capture groups:
| var csvInputData = ` | |
| 1,"Sarah ""stubs"" O'Reilly",sarah@test.com | |
| 2,'Bobby Lee Smith, Jr.',blsmith@test.com | |
| 3,Seema Smith,ssmith@test.com | |
| `.trim(); | |
| // We're going to use a Regular Expression to parse the CSV input. This is a complicated | |
| // matter (and possibly not meant for RegEx); so, we're going to break it up in to | |
| // several patterns that are easier to understand. Ultimately, each of these patterns | |
| // will be combined into a single patterns; so, we're going to use named capture groups | |
| // in order to make the matches easier to understand. | |
| var delimiter = /(?<delimiter>,|\r?\n|\r|^)/; | |
| var doubleQuotedField = /"(?<doubleQuotedField>[^"]*(?:""[^"]*)*)"/; | |
| var singleQuotedField = /'(?<singleQuotedField>[^']*(?:''[^']*)*)'/; | |
| var unquotedField = /(?<unquotedField>[^"',\r\n]*)/; | |
| // Now, let's create our CSV parser pattern by joining the above patterns. The named | |
| // capture groups will carry over into the new pattern. | |
| var parser = new RegExp( | |
| `${ delimiter.source }(${ doubleQuotedField.source }|${ singleQuotedField.source }|${ unquotedField.source })`, | |
| "giy" | |
| ); | |
| var matches = null; | |
| var rows = []; | |
| var row = null; | |
| // Continue iterating over the input until we run out of fields. | |
| while ( matches = parser.exec( csvInputData ) ) { | |
| // When we use named capture groups, the resulting matches object has a key, | |
| // "groups", which contains all of the groups in the pattern. Any group that is not | |
| // matched is reported as UNDEFINED. Let's get a short-hand reference to this object. | |
| var groups = matches.groups; | |
| // If the delimiter has no visible characters, we're going to assume it is a row | |
| // delimiter. As such, we'll allocate a new row for the subsequent field match. | |
| if ( ! groups.delimiter.trim() ) { | |
| rows.push( row = [] ); | |
| } | |
| // If the double-quoted field was captured, make sure to un-escape embedded quotes. | |
| if ( groups.doubleQuotedField !== undefined ) { | |
| row.push( groups.doubleQuotedField.replace( /""/g, `"` ) ); | |
| // If the single-quoted field was captured, make sure to un-escape embedded quotes. | |
| } else if ( groups.singleQuotedField !== undefined ) { | |
| row.push( groups.singleQuotedField.replace( /''/g, `'` ) ); | |
| } else { | |
| row.push( groups.unquotedField ); | |
| } | |
| // Safe-guard against completely empty matches that fail to move the "lastIndex" | |
| // forward to the next offset. | |
| if ( | |
| ! groups.delimiter && | |
| ! groups.doubleQuotedField && | |
| ! groups.singleQuotedField && | |
| ! groups.unquotedField | |
| ) { | |
| parser.lastIndex++; | |
| } | |
| } | |
| console.log( rows ); |
Parsing CSV (Comma-Separated Value) data is not the cleanest thing to do with Regular Expressions. As you can see, accounting for the delimiter and several variations on field delimiters makes for a compound and verbose pattern. Luckily, we can use the named capture groups to make it a bit more human-readable. And, when we run this Node code, we get the following console output:
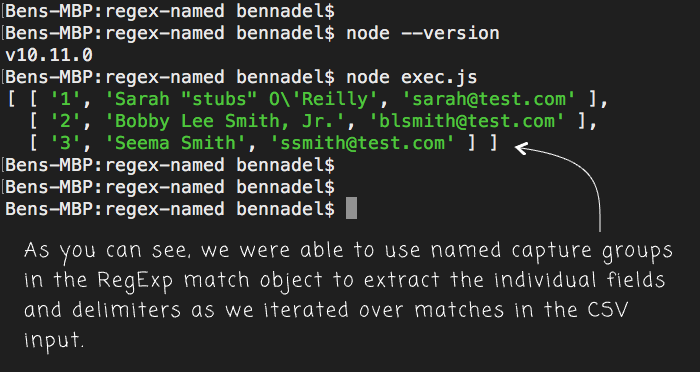
As you can see, we were able to use the compound Regular Expression to iterate over the CSV input and parse out the individual delimiters and field values. In each match, we used the named capture groups to make consuming the matches much easier to reason about.
Again, I'll defer to Rauschmayer's post for more technical detail. For this post, I really just wanted to try out RegExp named capture groups for the first time. And, to help spread the word to those who didn't know that this was a supported feature in Node.js 10.
Want to use code from this post? Check out the license.
Reader Comments
@All,
When I was searching for resources on Named capture groups, I think I probably was looking for Node-specific things, so my results were limited. Over on twitter, Mathias Bynens pointed out some other helpful resources: