
Considering When To Throw Errors, Why To Chain Them, And How To Report Them To Users
The truth is, I am not great at dealing with Exceptions and Error reporting in web application development. And, as someone who's been in web development for over 15-years, this saddens me. But, I'm trying to do something about it. For the last several months, I've been reading articles, watching presentations, and listening to podcasts about error handling all while constructing a foundational mental model for how I wanted to implement error handling in my own code. My mental model is not yet complete - and it will take more field experience in order to polish it; but, I'd like to share what I have so far.
The first thing I did on this journey was to start reading, watching, and listening to loads of content relating to error handling - just letting it wash over me. During this phase, I was doing nothing more than saturating my subconscious with interesting details. Then, once the content started to feel repetitive, I went back through all the content and extracted evidence that I found compelling in one way or another (see evidence below).
Once I had a good amount of evidence, I then went back and attempted to reduce the evidence down into a set of DO and DO NOT rules regarding error handling. I know that most expert programmers will say "it depends" to just about everything in computer science. But, that's not how my brain is wired (yet). I enjoy rules. I thrive on rules. And so, when I am learning, my mental model becomes an aggregation of rules that represent my understanding to date. That's not to say that these rules don't evolve over time - only to say that I represent wisdom behind rules, not behind more abstract layers of wisdom.
That said, the following list contains the DO and DO NOT rules that I have come up with (so far) regarding error handling in web application development:
CAVEAT: I had already decided that throwing exceptions was cleaner than returning error codes. As such, I wasn't looking to see which approach was better - I was looking for evidence on how to carry about error handling more coherently.
The DO Rules
DO throw an error from any method that cannot carry out the function it was contracted to do.
DO design code that - at a minimum - provides the "Fundamental Guarantee", which says that no resources will be leaked and no component will be left in an undefined state if an error is thrown (use those "Finally" blocks to clean up after yourself!).
DO consider robustness far before performance. Errors should be rare enough that performance overhead doesn't really matter. If you suspect performance is an issue, measure the performance first so that you can make an educated decision about refactoring.
DO keep the granularity and robustness of error handling commensurate with the cost of failure. A Pace Maker will necessarily have more error handling than a web-based TO-DO application.
DO have a global error handler at the boundary of your system (such as the web-application framework, aka the "delivery mechanism") that catches errors and recovers (preventing a crash). This handler should prevent technical details from leaking out of the system, while providing a meaningful response that the client can consume.
DO keep a centralized list of all the "error responses" that can be reported back to the user. This serves to document the behavior of the application and, as an added benefit, encourages consistency and facilitates internationalization of messages. The translation of a thrown error to one of these error responses should be done at the global / boundary error handler.
DO chain errors when you want to semantically-enrich the error.
DO semantically-enrich an error when you believe that the layer(s) above you might want to react to the semantically-enriched error. Reacting might involve something complex like a retry and fail-over algorithms; or, something simple like responding with a more meaningful HTTP status code.
DO include the "root cause" error when semantically-enriching an error. You never want to lose the message or the stack trace from the underlying error.
DO include sufficient contextual information when throwing (or chaining) an error. Your error object should contain enough contextual information that a programmer can easily reconstruction why the error occurred when looking at the logs.
DO design your errors to be consumed specifically by programmers (NEVER USERS). Keep your errors full of helpful technical and contextual information that can facilitate the debugging of the application.
DO prefer text over numbers for API "error codes". Doing so makes it easier to search (Google) for further documentation on the error's meaning (ex, prefer "RATE_LIMIT_EXCEEDED" over "E9004"). This also makes the error code easier to understand without documentation.
DO feel free to create subtle variations of error types and code that may help programmers and support engineers debug the application. For example, you can use "CONFLICT_ON_CREATE" and "CONFLICT_ON_RENAME" even when the same underlying "conflict" business rule is being violated. This subtle variation helps narrow in on the problem quickly and facilitates the tailoring of more specific error responses for the user (at the global / boundary error handler).
DO provide a way to collect superficial validation errors before a workflow is enacted. This allows the application to report multiple validation errors to the user instead of just one (based on the first error thrown in the workflow). That said, you should throw an exception if one of those validation errors is still present once the workflow has been engaged.
DO log "expected" domain errors and "unexpected" technical errors at different log-levels so that they can be easily identified and separated in the logs.
DO log meta-data about the request from which the error originated. Meta-data like "user ID", "IP address", and server / pod name can be really helpful when debugging. Correlation / request tracing IDs can also help track errors across distributed systems.
DO consider returning NULL instead of throwing a NOT_FOUND exception in low-level APIs if and only if it makes the code easier to consume and does not create ambiguity around the meaning of NULL (sorry Yegor).
The DO NOT Rules
DO NOT catch errors unless you really have to. Every "Catch" block has to have a really good reason to exist in your application.
DO NOT chain errors just for the sake of chaining them. Only chain when semantically enriching an error or when adding critical contextual information.
DO NOT chain errors simply because of language constraints. Meaning, some languages let you catch a subset of errors (allowing others errors to continue to propagate up the call stack); some languages do not. If you have to catch all errors locally in order to inspect the type (so to handle a subset of types), do not feel like you have to chain the rethrow of the non-handled errors.
DO NOT omit an underlying error when throwing a new error. Always include the underlying error as the "root cause" of the error you are throwing.
DO NOT let your end-users see error messages. Your application should catch errors at the boundary and translate them into "error responses" (which are always safe - and intended - to show the user).
DO NOT internationalize your error messages - doing so is an indication that you are targeting error messages at the users, not programmers. Error messages are for programmers.
DO NOT throw "domain errors" based on "technical errors". Meaning, a "NETWORK_FAILURE" technical error should never lead to a "USER_AUTHENTICAION_FAILED" domain error. Technical errors should bubble up through the system as technical errors (except for when they are being handled locally in retry or fallback algorithms, for example).
DO NOT log personally identifiable information (PII). Be sure to scrub common properties like "password", "ssn", and "creditcard" out of error payloads before logging them.
DO NOT swallow errors. Either log them or throw them (but never both).
DO NOT return error codes instead of throwing errors. It violates the Command Query Separation principle and litters your code with error handling logic.
For me, learning effectively requires more than just reading and writing - I have to code. And, since writing is open to interpretation, I wanted to try and come with a small Node.js demo that would illustrate how I interpret the rules that I have described above and how I would actually manifest them in an application.
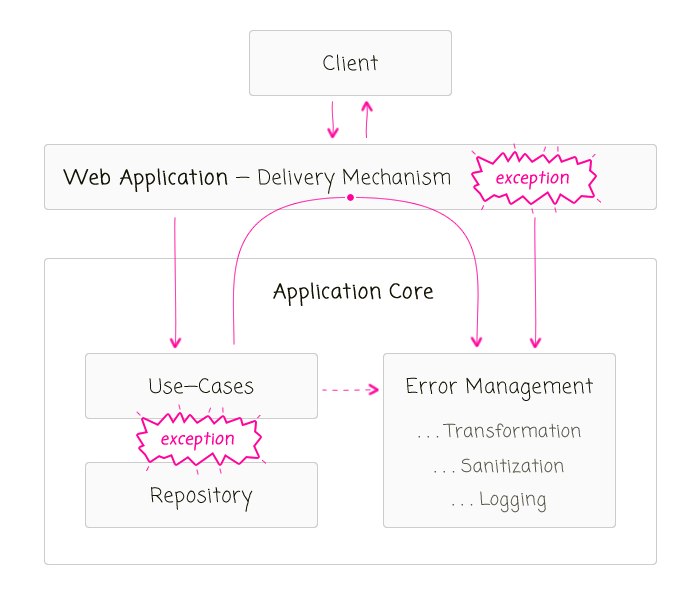
The demo is rather trite - a JSON (JavaScript Object Notation) API that allows you to Set and Get a single message. I wanted something that was small in scope; but, sufficiently layered so as to include as many of the DO and DO NOT rules as I could manage. What I came up with was a small Express.js application with two routes that map to two Use-Cases that both share a single Repository:
I tried to keep the code as simple as I could while still keeping it informative. As such, the organization of the code does not necessarily represent best practices. And, to be completely transparent, I am still not sure how I would want to implement validation prior to invocation (ie, collecting error messages without throwing errors).
I've also tried to keep all irrelevant comments out of the code (which, if you know me, was a monumental challenge of wills). The only comments in the demo are the inclusion of DO and DO NOT rules where they clarify the choices I am making.
That said, let's start from the bottom up - the repository - the source of data. This is where the messages live, using an implementation from which the rest of the application can remain decoupled. As we go through the code, I'll try to let the comments speak for themselves; but, I'll provide additional insight if I think it adds value.
// Require the application modules.
var AppError = require( "./app-error" ).AppError;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
exports.MessageRepository = class MessageRepository {
constructor() {
this._message = null;
}
// ---
// PUBLIC METHODS.
// ---
getMessage() {
var promise = new Promise(
( resolve, reject ) => {
// DO NOT throw "domain errors" based on "technical errors". Meaning, a
// "NETWORK_FAILURE" technical error should never lead to a
// "USER_AUTHENTICAION_FAILED" domain error. Technical errors should
// bubble up through the system as technical errors (except for when they
// are being handled locally in retry or fallback algorithms, for example).
this._simulateNetworkProblems();
// DO throw an error from any method that cannot carry out the function
// it was contracted to do.
if ( ! this._message ) {
throw(
new AppError({
type: "Message.NotFound"
})
);
}
resolve( this._message );
}
);
return( promise );
}
setMessage( newMessage ) {
this._message = newMessage;
return( Promise.resolve() );
}
// DO consider returning NULL instead of throwing a NOT_FOUND exception in low-
// level APIs if and only if it makes the code easier to consume and does not
// create ambiguity around the meaning of NULL (sorry Yegor).
tryGetMessageOrNull() {
var promise = new Promise(
( resolve, reject ) => {
// DO NOT throw "domain errors" based on "technical errors". Meaning, a
// "NETWORK_FAILURE" technical error should never lead to a
// "USER_AUTHENTICAION_FAILED" domain error. Technical errors should
// bubble up through the system as technical errors (except for when they
// are being handled locally in retry or fallback algorithms, for example).
this._simulateNetworkProblems();
resolve( this._message || null );
}
);
return( promise );
}
// ---
// PRIVATE METHODS.
// ---
_simulateNetworkProblems() {
if ( Math.random() < 0.5 ) {
throw( new Error( "NetworkFailure" ) );
}
}
};
In this repository, I am including some simulated (albeit greatly exaggerated) network problems. I did this because I wanted to illustrate my choice to let non-domain errors propagate through the stack as "technical errors". Notice that I am not trying to wrap the network error in some sort of repository error (ex, "Message.ReadFailure"). I am doing this because I don't believe the calling context needs to handle network problems explicitly. That said, the application may evolve over time to require this differentiation, at which point I may consider chaining the underlying network failure error.
The repository is then used by the two Use-Case for getting and setting the message. Let's look at the GetMessageQuery first:
// Require the application modules.
var AppError = require( "./app-error" ).AppError;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
exports.GetMessageQuery = class GetMessageQuery {
constructor( messageRepository ) {
this._repository = messageRepository;
}
// ---
// PUBLIC METHODS.
// ---
execute() {
var promise = this._repository
.getMessage()
.catch(
( error ) => {
// DO chain errors when you want to semantically-enrich the error.
if ( AppError.is( error, "Message.NotFound" ) ) {
// DO semantically-enrich an error when you believe that the
// layer(s) above you might want to react to the semantically-
// enriched error. Reacting might involve something complex like
// a retry and fail-over algorithms; or, something simple like
// responding with a more meaningful HTTP status code.
throw(
new AppError({
type: "Message.NotYetSet",
// DO design your errors to be consumed specifically by
// programmers (NEVER USERS). Keep your errors full of
// helpful technical and contextual information that can
// facilitate the debugging of the application.
detail: "The user has tried to access the message before any message has been set in the system.",
// DO include the "root cause" error when semantically-
// enriching an error. You never want to lose the message
// or the stack trace from the underlying error.
rootCause: error
})
);
}
// DO NOT chain errors simply because of language constraints.
// Meaning, some languages let you catch a subset of errors (allowing
// others errors to continue to propagate up the call stack); some
// languages do not. If you have to catch all errors locally in order
// to inspect the type (so to handle a subset of types), do not feel
// like you have to chain the rethrow of the non-handled errors.
throw( error );
}
)
;
return( promise );
}
};
Here, you can see where I am really stretching to come up with sufficiently illustrative cases in such a trite demo. In this application, you're not allowed to get the message until a message is set. I could have just let the NotFound error bubble up to the top; but, I am wrapping the "Message.NotFound" error in a "Message.NotYetSet" error (ie, chaining it) so as to enrich it semantically. Among other things, this will allow us to return a more informative error response to the user.
That said, you can see that there is a pathway in which I am just rethrowing the error without chaining it. This is to make up for the fact that JavaScript / Node.js doesn't let me differentiate errors at the Catch-level. As such, I'm blindly rethrowing the errors I don't care about in order to make up for the technical deficit in the language.
NOTE: Some user-land Promise libraries allow you to provide .catch() handlers that are bound to a particular "instanceof" Error. But, I have never used that feature personally (just never tried it).
The SetMessageQuery use-case is slightly more complicated because it attempts to provide a pre-action validation hook:
// Require the application modules.
var AppError = require( "./app-error" ).AppError;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
exports.SetMessageCommand = class SetMessageCommand {
constructor( messageRepository ) {
this._repository = messageRepository;
}
// ---
// PUBLIC METHODS.
// ---
execute( newMessage ) {
var promise = new Promise(
( resolve, reject ) => {
// DO provide a way to collect superficial validation errors before a
// workflow is enacted. This allows the application to report multiple
// validation errors to the user instead of just one (based on the first
// error thrown in the workflow).....
var errors = this.validate( newMessage );
// ..... That said, you should throw an exception if one of those
// validation errors is still present once the workflow has been engaged.
if ( errors.length ) {
throw(
new AppError({
type: errors[ 0 ].type,
extendedInfo: errors[ 0 ].extendedInfo
})
);
}
this._repository
// DO consider returning NULL instead of throwing a NOT_FOUND
// exception in low-level APIs if and only if it makes the code
// easier to consume and does not create ambiguity around the
// meaning of NULL (sorry Yegor).
.tryGetMessageOrNull()
.then(
( message ) => {
if ( message === newMessage ) {
// DO NOT return error codes instead of throwing errors.
// It violates the Command Query Separation principle and
// litters your code with error handling logic.
throw(
new AppError({
type: "Message.Conflict",
// DO include sufficient contextual information
// when throwing (or chaining) an error. Your
// error object should contain enough contextual
// information that a programmer can easily
// reconstruction why the error occurred when
// looking at the logs.
extendedInfo: {
message: message,
newMessage: newMessage
}
})
);
}
return( this._repository.setMessage( newMessage ) );
}
)
.then( resolve, reject )
;
}
);
return( promise );
}
// DO provide a way to collect superficial validation errors before a workflow is
// enacted. This allows the application to report multiple validation errors to the
// user instead of just one (based on the first error thrown in the workflow). That
// said, you should throw an exception if one of those validation errors is still
// present once the workflow has been engaged.
validate( newMessage, errors = [] ) {
if ( ( typeof newMessage ) !== "string" ) {
errors.push({
type: "Message.Invalid",
extendedInfo: {
message: newMessage
}
});
}
if ( ! newMessage ) {
errors.push({
type: "Message.Blank"
});
}
if ( newMessage.length > 100 ) {
errors.push({
type: "Message.TooLong",
extendedInfo: {
message: newMessage,
maxLength: 100
}
});
}
return( errors );
}
};
As I stated earlier, allowing for pre-command validation is the part of this entire application that feels the most shaky for me. That said, it's mostly an implementation detail. Hopefully, what I am illustrating here is that the pre-command validation allows the web-application to collect superficial validation errors. But, if the web-application were to continue trying to process the request - ignoring the validation errors - the use-case would through an exception. This goes back to the base philosophy that a method should throw an error if it cannot do what it said it would do, which in this case, would be to "save a message."
Both of these use-cases represent the interactions that the "application core" is capable of performing. And, both of these use-cases are consumed by the Express.js application, which is the "delivery mechanism" for the application:
// Require the core node modules.
var bodyParser = require( "body-parser" );
var chalk = require( "chalk" );
var express = require( "express" );
var util = require( "util" );
// Require the application modules.
var AppError = require( "./app-error" ).AppError;
var ErrorTransformer = require( "./error-transformer" ).ErrorTransformer;
var GetMessageQuery = require( "./get-message-query" ).GetMessageQuery;
var MessageRepository = require( "./message-repository" ).MessageRepository;
var SetMessageCommand = require( "./set-message-command" ).SetMessageCommand;
var Sanitizer = require( "./sanitizer" ).Sanitizer;
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
errorTransformer = new ErrorTransformer();
messageRepository = new MessageRepository();
sanitizer = new Sanitizer();
getMessageQuery = new GetMessageQuery( messageRepository );
setMessageCommand = new SetMessageCommand( messageRepository );
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
var app = express();
app.use( bodyParser.json() );
app
.route( "/" )
// I GET the message from the system.
.get(
function( request, response, next ) {
getMessageQuery
.execute()
.then(
( message ) => {
response.send( message );
}
)
// DO have a global error handler at the boundary of your system (such
// as the web-application framework, aka the "delivery mechanism") that
// catches errors and recovers (preventing a crash). This handler should
// prevent technical details from leaking out of the system, while
// providing a meaningful response that the client can consume.
.catch( next )
;
}
)
// I SET the message in the system.
.post(
function( request, response, next ) {
// DO provide a way to collect superficial validation errors before a
// workflow is enacted. This allows the application to report multiple
// validation errors to the user instead of just one (based on the first
// error thrown in the workflow). That said, you should throw an exception
// if one of those validation errors is still present once the workflow has
// been engaged.
var superficialErrors = setMessageCommand.validate( request.body.message );
// TODO: Possibly move this error handling to the global error handler using
// next(superficialErrors) -- this way we truly centralize all of the
// error recovery.
if ( superficialErrors.length ) {
response
.status( 400 )
.json( errorTransformer.getValidationResponse( superficialErrors ) )
;
return;
}
setMessageCommand
.execute( request.body.message )
.then(
() => {
response
.status( 204 )
.end()
;
}
)
// DO have a global error handler at the boundary of your system (such
// as the web-application framework, aka the "delivery mechanism") that
// catches errors and recovers (preventing a crash). This handler should
// prevent technical details from leaking out of the system, while
// providing a meaningful response that the client can consume.
.catch( next )
;
}
)
;
// DO have a global error handler at the boundary of your system (such as the web-
// application framework, aka the "delivery mechanism") that catches errors and
// recovers (preventing a crash). This handler should prevent technical details from
// leaking out of the system, while providing a meaningful response that the client
// can consume.
app.use(
function( error, request, response, next ) {
// DO log meta-data about the request from which the error originated. Meta-
// data like "user ID", "IP address", and server / pod name can be really
// helpful when debugging. Correlation / request tracing IDs can also help
// track errors across distributed systems.
var metaData = {
httpMethod: request.method,
httpResource: request.originalUrl,
ipAddress: request.ip,
// DO NOT log personally identifiable information (PII). Be sure to scrub
// common properties like "password", "ssn", and "creditcard" out of error
// payloads before logging them.
params: sanitizer.sanitizeScopeForLogging( request.params ),
query: sanitizer.sanitizeScopeForLogging( request.query ),
body: sanitizer.sanitizeScopeForLogging( request.body )
};
// DO log "expected" domain errors and "unexpected" technical errors at
// different log-levels so that they can be easily identified and separated
// in the logs.
if ( AppError.isDomainError( error ) ) {
console.log( chalk.bold.cyan( "WARNING - Domain Error" ) );
console.log({
level: "warn",
metaData: metaData,
// DO NOT log personally identifiable information (PII). Be sure to
// scrub common properties like "password", "ssn", and "creditcard"
// out of error payloads before logging them.
data: sanitizer.sanitizeScopeForLogging( error )
});
} else {
console.log( chalk.bold.red( "ERROR - Unexpected Error" ) );
console.log({
level: "error",
metaData: metaData,
// DO NOT log personally identifiable information (PII). Be sure to
// scrub common properties like "password", "ssn", and "creditcard"
// out of error payloads before logging them.
data: sanitizer.sanitizeScopeForLogging( error )
});
}
if ( ! response.headersSent ) {
// DO NOT let your end-users see error messages. Your application should
// catch errors at the boundary and translate them into "error responses"
// (which are always safe - and intended - to show the user).
var errorResponse = errorTransformer.getErrorResponse( error );
response
.type( "application/json" )
.status( errorResponse.status )
.send({
code: errorResponse.code,
status: errorResponse.status,
message: errorResponse.message
})
;
}
}
);
app.listen( "8080" );
The primary point of illustration in this Express.js application is that I am using a global error handler that logs errors and translates them into responses for the user. The Express.js application is the "boundary" to our system where we prevent internal, technical details from leaking out into the Client.
In this case, I happen to be handling "validation errors" directly in the POST route handler. However, if I could go back and redo this demo (frankly, I'm exhausted), I think I would move the validation error handling down into the global error handler. This way, the route handlers could just call:
return( next( superficialErrors ) );
... and I wouldn't be littering my routes with special error responses.
When the global error handler does receive an error, it doesn't just return it to the user. Doing so would, at best, be confusing to the user and, at worst, expose security vulnerabilities to the outside world. As such, the errors that have bubbled up to the top of the application are translated into "Error responses" using an error transformer:
// DO keep a centralized list of all the "error responses" that can be reported back to
// the user. This serves to document the behavior of the application and, as an added
// benefit, encourages consistency and facilitates internationalization of messages.
// The translation of a thrown error to one of these error responses should be done at
// the global / boundary error handler.
var errorResponses = exports.errorResponses = {
// DO prefer text over numbers for API "error codes". Doing so makes it easier to
// search (Google) for further documentation on the error's meaning (ex, prefer
// "RATE_LIMIT_EXCEEDED" over "E9004"). This also makes the error code easier to
// understand without documentation.
"Message.Blank": {
status: 422,
message: "The message cannot be empty. Please provide a longer message."
},
"Message.Invalid": {
status: 400,
message: "The message you sent cannot be parsed. Please double-check to make sure you're sending a String value."
},
"Message.NotYetSet": {
status: 403,
message: "The message has not yet been initialized. Once you SET a message, you will be able to GET a message."
},
"Message.TooLong": {
status: 422,
message: function( error ) {
var message = error.extendedInfo.maxLength
? `The message is too long. Please provide a message that is less than ${ error.extendedInfo.maxLength } characters.`
: "The message is too long. Please provide a shorter message."
;
return( message );
}
},
"Server": {
status: 500,
message: "There was an unexpected error - our support team has been notified and will be investigating."
}
};
exports.ErrorTransformer = class ErrorTransformer {
getErrorResponse( error ) {
var errorCode = ( error && errorResponses.hasOwnProperty( error.type ) )
? error.type
: "Server"
;
var errorResponse = errorResponses[ errorCode ];
var errorStatus = errorResponse.status;
// DO NOT let your end-users see error messages. Your application should catch
// errors at the boundary and translate them into "error responses" (which are
// always safe - and intended - to show the user).
var errorMessage = ( errorResponse.message instanceof Function )
? errorResponse.message( error )
: errorResponse.message
;
return({
code: errorCode,
status: errorStatus,
message: errorMessage
});
}
getValidationResponse( validationErrors ) {
var validationResponse = validationErrors.map(
( validationError ) => {
return( this.getErrorResponse( validationError ) );
}
);
return( validationResponse );
}
};
The Error Transformer acts as the point of centralization for all errors that the application can return to the client. These error response messages can be static; or, they can depend on the error that has bubbled up through the application (notice that the "Message.TooLong" error provides the "message" as an invocable, not a string).
Of course, reporting the error to the user is one thing; but, the more important aspect of error reporting is, arguably, reporting it to the engineers that are building and maintaining the application. As such, the Express.js application both returns the "error response" and logs the "exception". In this case, I'm just logging to the console (where it might be consumed on the standard error / out stream); but, a critical point in all of this is that I'm doing my best not to persist Personally Identifiable Information (PII) to the logs. I attempt to prevent this by passing the logged data through a sanitizer before I write it to the console:
exports.Sanitizer = class Sanitizer {
// ---
// PUBLIC METHODS.
// ---
sanitizeScopeForLogging( scope ) {
var sanitizedScope = Object.assign( {}, scope );
// NOTE: These properties don't appear to be iterable on an Error object; so,
// we are explicitly checking for them (and copying them over for logging).
scope.message && ( sanitizedScope.message = scope.message );
scope.stack && ( sanitizedScope.stack = scope.stack );
for ( var key of Object.keys( scope ) ) {
// DO NOT log personally identifiable information (PII). Be sure to scrub
// common properties like "password", "ssn", and "creditcard" out of error
// payloads before logging them.
if ( this._isBlacklisted( key ) ) {
sanitizedScope[ key ] = "[sanitized]";
}
}
// Beyond the scope of this exploration:
// --
// TODO: Recursively walk through scope.
// TODO: Truncate long key-values to make sure the logs remain responsive
// and easy to consume.
return( sanitizedScope );
}
// ---
// PRIVATE METHODS.
// ---
_isBlacklisted( key ) {
return(
key.match( /creditcard/i ) ||
key.match( /expiration(month|year)/i ) ||
key.match( /password/i ) ||
key.match( /ssn/i )
);
}
};
In reality, I would probably need to recurse through the structure being logged; but, in order to keep things as simple as possible, I'm just sanitizing top-level keys, making sure that indicators like "password" or "ssn" (Social Security Number) don't get written to log files.
And, of course, under all of this is my custom AppError, which is a subclass of the native Error (since you can subclass native Constructors in ES6):
exports.AppError = class AppError extends Error {
constructor( settings = {} ) {
settings.type
? super( `Domain Error: ${ settings.type }` )
: super( "Technical Error" )
;
this.name = "AppError";
this.type = ( settings.type || null );
this.detail = ( settings.detail || null );
this.rootCause = ( settings.rootCause || null );
this.extendedInfo = ( settings.extendedInfo || null );
Error.captureStackTrace( this, this.constructor );
}
// ---
// STATIC METHODS.
// ---
static is( error, ...typePrefixes ) {
if ( ! ( ( error instanceof AppError ) && error.type ) ) {
return( false );
}
for ( const typePrefix of typePrefixes ) {
if (
( error.type === typePrefix ) ||
( error.type.startsWith( typePrefix + "." ) )
) {
return( true );
}
}
return( false );
}
static isDomainError( error ) {
return( ( error instanceof AppError ) && error.type );
}
}
And that's all there is to this application. Hopefully the code is simple enough to be understandable; yet, complex enough to illustrate the error handling rules that I am formulating without them seeming superfluous. And, remember that this mental model will continue to evolve over time, especially as I try to practice more of this approach in a production environment.
Now that we've looked at the code, I'll present the evidence (without explanation) upon which these rules have been built. In some cases, the content is from podcasts where I had to transcribe it manually. As such, it might not be entirely accurate.
One of the things that I found most interesting in all of this was the concept of the "Fundamental Guarantee":
Fundamental guarantee should be provided by every single part of your system - what ever happens, you must not have resource leaks; and, whatever happens, you must not have code that is in an undefined state but still available to clients.=
To me, this makes so much sense! And, again, just speaks to one of my earlier posts in which I stated that it seems odd to crash a process just because an error bubbled up to the top of the application.
ERROR HANDLING AND REPORTING EVIDENCE
This doesn't represent all of the content that I consumed; but, these were the pieces that I felt were worth sharing.
Elegant Objects By Yegor Bugayenko
It is an obvious choice we have to make when designing a method - to catch all exceptions here and now, making the method look "safe" for its users, or escalate the problems. I am in favor of the second option. Escalate them as much as you can. Every catch statement has to have a very strong reason for its existence. In other words, don't catch unless you really have to do it, and there is no other choice.
In an ideal design, there has to be only one catch statement per point of entrance into the application. For example, if it is a mobile app communicating with the user through the phone screen, it has a single entrance and must have a single catch in the entire application. Unfortunately, that is very rarely possible, mostly because Java itself and many existing frameworks are design with a different idea in mind.
(Page 202)
I'm sure this is just obvious, but let me reiterate anyway: always chain exceptions, and never ignore original ones.
But why do we need exception chaining in the first place, you may ask. Why can't we just let the exceptions float up and declare all our methods unsafe? In the example above, why catch IOException and throw it again, "wrapped" into Exception? What is wrong with the existing IOException? The answer is obvious: exception chaining semantically enriches the problem context. In other words, just receiving "Too many open files (24)" is not enough. It is too low-level. Instead, we want to see a chain of exceptions where the original one says that there are too many open files, the next one says that the file length can't be calculated, the next one claims that the content of the image can't be read, etc. If a user can't open his or her own profile picture, just returning "too many files" is not enough.
Ideally, each method has to catch all exceptions possible and rethrow them through chaining. Once again, catch everything, chain, and immediately rethrow. This is the best approach to exception handling.
(Page 207)
[main] is the only legal place for recovery... The same should happen at every entrance point. There are not so many of them, even in complex systems. What I'm saying is that there are just a few legal places for recovering in any software. Everywhere else, we must catch and rethrow or not catch at all. The first option is preferable. Always catch, chain, and rethrow. Recover only once at the highest level. That's it.
(Page 209)
If you agree with the "never recover" and "always chain" principles explained above, you would understand why exception typing is a redundant feature. Indeed, if we recover only once, we have an exception object that contains all other exceptions inside it when that happens. If properly chained, why do we need to know its type?
Moreover, we never use exceptions for flow control, right? We never catch exceptions in order to decide what to do next. we only catch in order to rethrow, right? If that's the case, we don't really care about the type of exception we're catching. We will rethrow it anyway. We simply don't need this information, because we never use it. We don't catch exceptions on their way up. Even when do catch, we do it for only one purpose: to chain them and rethrow.
(Page 212)
Exception messages are for programmers
All of the above arguments even implicitly assume that you're writing exception messages for a known system. What if you're writing a reusable library? If you're writing a reusable library, you don't know the context in which it's going to be used. If you don't know the context, then how can you write an appropriate message for an end user?
It should be clear that when writing a reusable library, you're unlikely to know the language of the end user, but it's worse than that: you don't know anything about the end user. You don't even know if there's going to be an end user at all; your library may as well be running inside a batch job.
The converse is true as well. Even if you aren't writing a reusable library, end user-targeted exception messages increases the coupling in the system, because exception messages would be coupled to a particular user interface. This sort of coupling doesn't occur in the type system, but is conceptual. Exactly because it's not tied to any type system, an automated tool can't detect it, so it's much harder to notice, and more insidious as a result.
Exception messages are not for end users. Applications can catch known exception types and translate them to context-aware error messages, but this is a user interface concern - not a technical concern.
Exceptional practices, Part 3
... The explanatory error text simply does not belong in the Java code; it should be retrieved from an external source. What happens when you want to localize this code for a foreign market? Someone will have to comb through all the source code, identifying all text strings that will be used to build exceptions. Then a translator will have to translate them all, and then you have to figure out how to maintain different versions of the same code for multiple markets. And you have to repeat this process for every release.
Even if you never plan to localize, there are other good reasons for removing error message text from code: Error messages can easily get out of sync with the documentation -- a developer might change an error message and forget to inform the documentation writer. Similarly, you might want to change the wording of all error messages of a certain type to make them more consistent, but since you must comb through all the sources to find all such error messages, you could easily miss one, resulting in inconsistent error messages.
....
The error message is separated (somewhat) from the code, so it is much easier to find when localizing the class. Separating the error message from the code reduces the work required for localization and reduces the chance that an error message will be missed. It also encourages developers to reuse the same message if multiple methods throw the same error so the program will be more likely to have a consistent set of error messages.
....
Using message catalogs to store exception message strings offers another hidden benefit. Once you've placed all the exception messages in a message catalog, you now have a comprehensive list of all the exception messages your application might throw. This provides an easy starting point for the documentation writer to use when creating the manual's "Troubleshooting" or "Error Messages" section. Message catalogs also make it easy for documentation writers to track changes in the resource bundles and ensure the documentation stays in sync with the software.
Error handling considerations and best practices
Be descriptive in your error messages and include as much context as possible. Failure to do so will cost you dearly in support later on: if your client developers cannot figure out why their request went wrong, they will look for help - and eventually that will be you who will spend time tracking down client errors instead of coding new and exiting features for your service.
If it is a validation error, be sure to include why it failed, where it failed and what part of it that failed. A message like "Invalid input" is horrible and client developers will bug you for it over and over again, wasting your precious development time. Be descriptive and include context: "Could not place order: the field 'Quantity' should be an integer between 0 and 99 (got 127)".
You may want to include both a short version for end users and a more verbose version for the client developer.
....
Error messages for end users should be localized (translated into other languages) if your service is already a multi language service. Personally I don't think developer messages should be localized: it is difficult to translate technical terms correct and it will make it more difficult to search online for more information.
....
I often find myself searching for online resources that can help me when I get some error while interacting with third party APIs. Usually I search for a combination of the API name, error messages and codes. If you include additional error codes in your response then you might want to use letters instead of digits: it is simply more likely to get a relevant hit for something like "OAUTH_AUTHSERVER_UNAVAILABLE" than "1625".
Best Practices To Create Error Codes Pattern For an Enterprise Project in C#
There is a difference between error codes and error return values. An error code is for the user and help desk. An error return value is a coding technique to indicate that your code has encountered an error.
One can implement error codes using error return values, but I would advice against that. Exceptions are the modern way to report errors, and there is no reason why they should not carry an error code within them.
This is how I would organize it (Note that points 2-6 are language agnostic):
- Use a custom exception type with an additional ErrorCode property. The catch in the main loop will report this field in the usual way (log file / error pop-up / error reply). Use the same exception type in all of your code.
- Do not start at 1 and don't use leading zeros. Keep all error codes to the same length, so a wrong error code is easy to spot. Starting at 1000 usually is good enough. Maybe add a leading 'E' to make them clearly identifiable for users (especially useful when the support desk has to instruct users how to spot the error code).
- Keep a list of all error codes, but don't do this in your code. Keep a short list on a wiki-page for developers, which they can easily edit when they need a new code. The help desk should have a separate list on their own wiki.
- Do not try to enforce a structure on the error codes. There will always be hard-to-classify errors and you don't want to discuss for hours whether an error should be in the 45xx group or in the 54xx group. Be pragmatic.
- Assign each throw in your code a separate code. Even though you think it's the same cause, the help desk might need to do different things in different cases. It's easier for them to have "E1234: See E1235" in their wiki, than to get the user to confess what he has done wrong.
- Split error codes if the help desk asks for it. A simple if (...) throw new FooException(1234, ".."); else throw new FooException(1235, ".."); line in your code might save half an hour for the help desk.
And never forget that the purpose of the error codes is to make life easier for the help desk.
The Generation, Management and Handling of Errors (Part 1)
One of the key requirements for any group required to maintain a system is the ability to detect errors when they occur and to obtain sufficient information to diagnose and fix the underlying problems from which those errors spring. If incorrect or inappropriate error information is generated from a system it becomes difficult to maintain. Too much error information is just as much of a problem as too little. Although most modern development environments are well provisioned with mechanisms to indicate and log the occurrence of errors (such as exceptions and logging APIs), such tools must be used with consistency and discipline in order to build a maintainable application. Inconsistent error handling can lead to many problems in a system such as duplicated code, overly-complex algorithms, error logs that are too large to be useful, the absence of error logs and confusion over the meaning of errors. The incorrect handling of errors can also spill over to reduce the usability of the system as unhandled errors presented to the end user can cause confusion and will give the system a reputation for being faulty or unreliable. All of these problems are manifest in software systems targeted at a single machine. For distributed systems, these issues are magnified.
....
Split Domain And Technical Errors
This pattern language classifies errors as 'domain' or 'technical' and also as 'expected' and 'unexpected'. To a large degree the relationship between these classifications is orthogonal. You can have an expected domain error (no funds in the account), an unexpected domain error (account not in database), an expected technical error (WAN link down - retry), and an unexpected technical error (missing link library). Having said this, the most common combinations are expected domain errors and unexpected technical errors.
....
Design and development policies should be defined for domain and technical error handling. These policies should include:
* A technical error should never cause a domain error to be generated (never the twain should meet). When a technical error must cause business processing to fail, it should be wrapped as a SystemError.
* Domain errors should always start from a domain problem and be handled by domain code.
* Domain errors should pass 'seamlessly' through technical boundaries. It may be that such errors must be serialized and re-constituted for this to happen. Proxies and facades should take responsibility for doing this.
* Technical errors should be handled in particular points in the application, such as boundaries (see Log at Distribution Boundary).
....Positive consequences:
* The business error handling code will be in a completely different part of the code to the technical error handling and will employ different strategies for coping with errors.
* Business code needs only to handle any business errors that occur during its execution and can ignore technical errors making it easier to understand and more maintainable.
* Business error handling code can be clearer and more deterministic as it only needs to handle the subset of business errors defined in the contract of the business methods it calls.
* All potential technical errors can be handled in surrounding infrastructure (server-side skeleton, remote facade or main application) which can then decide if further business actions are possible.
* Different logging and auditing policies are easily applied due to the clear distinction of error types.
....Log At Distribution Boundary
When technical errors occur, log them on the system where they occur passing a simpler generic SystemError back to the caller for reporting at the end-user interface. The generic error lets calling code know that there has been a problem so that they can handle it but reduces the amount of system-specific information that needs to be passed back through the distribution boundary.
....
Whenever a technical error occurs, the application infrastructure code that catches the error should call the technicalError routine to log the error on its behalf and then create a SystemError object containing a simple explanation of the failure and the unique error instance ID returned from technicalError. This error object should be then returned to the caller... If a technical error can be handled within a tier (including it being 'silently' ignored - see proto-pattern Ignore Irrelevant Errors - except that it is always logged) then the SystemError need not be propagated back to the caller and execution can continue.
....
Unique Error Identifier
Generate a Unique Error Identifier when the original error occurs and propagate this back to the caller. Always include the Unique Error Identifier with any error log information so that multiple log entries from the same cause can be associated and the underlying error can be correctly identified.
....
The unique error identifier must be unique across all the hosts in the system. This rules out many pseudo-unique identifiers such as those guaranteed to be unique within a particular virtual platform instance (.NET Application Domain or Java Virtual Machine). The obvious solution is to use a platform-generated Universally Unique ID (UUID) or Globally Unique ID (GUID). As these utilize the unique network card number as part of the identifier then this guarantees uniqueness in space (across servers). The only issue is then uniqueness across time (if two errors occur very close in time) but the narrowness of the window (100ns) and the random seed used as part of the UUID/GUID should prevent such problems arising in most scenarios.
Episode 7: Error Handling
NOTE: Transcribed by Ben Nadel - may not be entirely accurate.
If we do local exception handling, there's the danger of having catch blocks all over the place... where 2/3rds of the code is just catch blocks that catch a dozen different kinds of exceptions just to re-wrap it without doing any actual handling. This makes code very difficult to read. And, it bloats a one line method to 30, 40 lines of code. This can really be a problem for readability, for maintainability of code. And, it does not really add any value to the system because all that happens is re-wrapping of exceptions.
So, over time I've come to see a different perspective on exception handling, and that is the big picture: at every exception, go up the call stack and not handle them at all locally. I mean let's look at the different kinds of errors we had. If we had bugs, there's not really any point in wrapping bugs into application-specific exceptions. And re-wrapping these. And re-wrapping these up the call stack - a bug is a bug is a bug. And, bugs usually are handled at some high level in the code, top of the call stack kind of. And, lead to a message popping up. And, that is all about all... There's not really any value to doing deign by contract for bugs....
And the third thing - infrastructure problems. Let's say there is a some sort of problem with the database or some sort of problem with the network. In those situations, it is really useful at the top level to have the original exception; and, basically, that's all we're interested in most of the time. If there's a network problem, let's say there is a naming service lookup timeout, then this is really what we want to have at the user interface level to present that to the user. And, we don't want 5 layers of application-specific exceptions around that....
[It does make sense to catch and wrap exceptions at boundaries], definitely; but, the boundaries where it makes sense to catch exceptions and re-wrap them are usually Team boundaries. Subsystem boundaries. At a very high level, in very big systems. And there, it definitely makes sense to catch them and re-wrap them because if there's a database problem inside Amazon, I'm not interested in knowing there's a database problem at Amazon, I just want to know that there was some sort of problem looking up the Book information I wanted to have. In that situation, it makes sense to add this abstraction.
But, there has been a tendency over the years to apply this kind of pattern at a smaller and smaller and smaller scale. Where subsystems are replaced with single classes. And there, it is really problematic. So, inside one team of people who need to debug this - who need to understand this - one team of system administrators, who administrate a system, it does not really make sense to wrap exceptions and re-wrap them. Then, it's often better to, and much simpler to, have the original exception information....
The idea is basically to... not have small catch blocks all over the place that try to handle exceptions where they really cannot be handled; but, rather to have one catch block at the top of the call stack and let that do all of the exception handling. And, only where it's possible to do exception handling locally, let's do that locally; where it's necessary to add information locally, let's do that locally. But, the actual handling in the end is done in this high-level catch block that does everything, basically....
This is not an invitation to just dump the work on someone else. If you can "retry" [an action], and that makes sense, definitely do that locally. So, if you can handle an exception, handle it. But, many of the exceptions cannot be handled; or, there are situations where they cannot be handled in a meaningful way. So, if there's something you cannot handle, don't fake it. And then, it's good to have one place high up the call chain, in the call stack, that catches everything and does the processing there.
Episode 21: Error Handling Pt. 2
NOTE: Transcribed by Ben Nadel - may not be entirely accurate.
You sort of restrict yourself to handling expected conditions in a well-defined way and then you have unexpected kinds of exceptions that you handle in a catch-all way that makes sure nothing really bad happens; but, the expectation is that the system won't behave as gracefully as with the expected conditions.
....
The key point is to think about your design in terms of what guarantee does my code provide? Or, looking at it differently, what parts of my code need to provide which level of guarantee. To sum these level of guarantee up, the key thing is that the Fundamental guarantee should be provided by every single part of your system - what ever happens, you must not have resource leaks; and, whatever happens, you must not have code that is in an undefined state but still available to clients... And then, building on that, you can think about providing the Basic Guarantee that says whatever happens, the components will remain usable. The Strong Guarantee, I have roll-back semantics. Or, the No-Throw Guarantee if you want to have portions that you can rely on, that whatever happens they deal with it gracefully and contain any exceptional condition.
....
The single most important best practice of dealing with [unexpected] exceptions is to handle the exceptions at the subsystem boundaries. To partition your system and only deal with exceptions at these boundaries of the system. This might be, if you have a big monolithic system, then you might just have one component and deal with any sort of exception at the GUI (or right below the GUI)... It is important to not clutter your code with Catch blocks that handle exceptions all over your code because this makes the code unreadable and covers up the design - makes it very hard to understand what is going on.
....
For [expected] Errors - errors are sort of different. If an error occurs - sort of an expected problem - the "expected" part of the definition of "error" means that someone thought you might want to handle it rather locally - you might be interested in it and deal with it. So, if you can and it makes sense to, then you should contain it and handle it locally. Examples of this are, Connection fail-over.... This is the architectural strategy of thinking about error conditions and how you can gracefully handle them locally. This does not mean that you can always do that.
....
When you design a component, when you design a part of the system, with an interface that others will call, it is good to think about what are the things that can go wrong; and, which of these things would be meaningful to a caller to deal with, and which wouldn't. I mean it's good to think about that; but, this shows that the distinction is sort of hard to get exact because you will not know which people will call your code, how that will evolve, and some things are really hard to put in one of the categories.... so, this shows that, yeah, it is good to think about this distinction, but then don't think about it too much and try to be over strict in applying this distinction....
Another best practice is .... whenever a technical exception is thrown, it means that it should contain all data that is necessary to understand; to reconstruct the context; to reconstruct what went wrong, what lead to this. And, that everything that is necessary to handle this exception condition. Which means that, often times, exception classes have data added to them or you have an inheritance hierarchy that reflects the way in which they will be handled differently. The key point here is to hit the right level of detail, which is as always, difficult. But, some level of detail is necessary and helpful....
....
The last rule of thumb is, robustness goes first. And performance tuning is a distant second, if even second, maybe third or fourth. Robustness goes first. This should be obvious - it's being said so often; but still, it is not obvious. And, I hear that over and over and over again, people saying that, "Oh, using exception costs performance - it's slow - it has huge overhead, so I will not use exceptions" ... this is weird.... Exceptional conditions are rare - or should be rare anyway. And, thinking about performance in the handling of exceptional conditions is usually a really really bad idea. Exceptional conditions are so rare that usually it does not matter if there's an overhead. And, using the technical means of exceptions has become quite fast by now. Yes, it is slower than a return code. But, that is just something that does not matter at all. No one should care; and, if you do care about that, for example, if you're in an embedded system, you should at least measure the impact it has. And, if you have measured and, yes, exceptions are the bottleneck in your design, you might want to redesign. And, if all these means fail, you might consider removing exceptions or make them less robust. But, simplify your design - keep it simple and use exceptions. Exceptions make for robust and simple technical means to keep your code free from the details of dealing with problems... So, use exceptions and ignore performance concerns unless you do the effort to actually measure if throwing exceptions has the critical impact on your performance; which I seriously doubt.
Episode 52 - Clean Code - Error Handling
NOTE: I didn't have time to transcribe the interesting bits.
Failure and Exceptions - A Conversation with James Gosling, Part II
James Gosling: It's all over the map. Ideally you should be spending almost all of your time on the one true path. But if you look at various domains, the percentages are different. The worst case would be people doing avionics software. If they spend a few percent of their time working on the one true path, they feel very good about themselves. That's the kind of area where the high nineties percentage of your time is spent dealing with things that could go wrong, and speculating about things that could go wrong. In that area, life is truly dynamic. There are real random number generators up there, with turbulence doing strange things to wing tips and all kinds of weird stuff that may never actually happen.
Almost as bad as avionics is networking software. When you're trying to write some piece of software that is dealing with something across the network, trying to make that truly reliable can be a lot of work. I've done code that tries to maintain reliable database access, for example, and that can be 90% error handling. You look at most protocol implementations and at some level they're almost all error handling. If you believed everything was perfect all you would do was spew packets. You wouldn't worry about timeouts, flow control negotiations, and any of the other things that go on. Networking is all about how you deal with errors at all various different levels. But when you're in a fairly well-controlled regime like, "Here's a web request, compute the result please," there shouldn't be a whole lot that you're actually worried about.
Bill Venners: Yeah, I think there's a spectrum. At one end you have pace makers and airplanes. If you don't deal with certain kinds of unexpected situations people can die. At the other end you have one off scripts. I remember one script I wrote that was pulling information out of web pages and putting it into XML files, and the script worked on maybe 90% of the pages I was processing. And that was good enough because it was faster for me to fix the other 10% by hand than to make the script better at dealing with badly formed input files. In that case, there was a system administrator who was quite happy to spend an hour fixing things by hand, because that was cheaper than spending 2 or 3 hours trying to get the script to be more solid.
Catch Me If You ... Can't Do Otherwise
Exceptions were invented to simplify our design by moving the entire error handling code away from the main logic. Moreover, we're not just moving it away but also concentrating it in one place - in the main() method, the entry point of the entire app.
The primary purpose of an exception is to collect as much information as possible about the error and float it up to the highest level, where the user is capable of doing something about it. Exception chaining helps even further by allowing us to extend that information on its way up. We are basically putting our bubble (the exception) into a bigger bubble every time we catch it and re-throw. When it hits the surface, there are many bubbles, each remaining inside another like a Russian doll. The original exception is the smallest bubble.
....
My suggestion is to catch exceptions as seldom as possible, and every time you catch them, re-throw.
Replacing Throwing Exceptions with Notification in Validations
My preferred way to deal with reporting validation issues like this is the Notification pattern. A notification is an object that collects errors, each validation failure adds an error to the notification. A validation method returns a notification, which you can then interrogate to get more information.
....
I need to stress here, that I'm not advocating getting rid of exceptions throughout your code base. Exceptions are a very useful technique for handling exceptional behavior and getting it away from the main flow of logic. This refactoring is a good one to use only when the outcome signaled by the exception isn't really exceptional, and thus should be handled through the main logic of the program. The example I'm looking at here, validation, is a common case of that.
Clean Code and The Art of Exception Handling
So, define the single responsibility of your class or method, and handle the bare minimum of exceptions that satisfy this responsibility requirement. For example, if a method is responsible for getting stock info from a remote a API, then it should handle exceptions that arise from getting that info only, and leave the handling of the other errors to a different method designed specifically for these responsibilities.
[code snippet] Here we defined the contract for this method to only get us the info about the stock. It handles endpoint-specific errors, such as an incomplete or malformed JSON response. It doesn't handle the case when authentication fails or expires, or if the stock doesn't exist. These are someone else's responsibility, and are explicitly passed up the call stack where there should be a better place to handle these errors in a DRY way.
....
We are working with moving requirements almost all the time, and making the decision that an exception will always be handled in a specific way might actually harm our implementation, damaging extensibility and maintainability, and potentially adding huge technical debt, especially when developing libraries.
Take the earlier example of a stock API consumer fetching stock prices. We chose to handle the incomplete and malformed response on the spot, and we chose to retry the same request again until we got a valid response. But later, the requirements might change, such that we must fall back to saved historical stock data, instead of retrying the request.
At this point, we will be forced to change the library itself, updating how this exception is handled, because the dependent projects won't handle this exception. (How could they? It was never exposed to them before.) We will also have to inform the owners of projects that rely on our library. This might become a nightmare if there are many such projects, since they are likely to have been built on the assumption that this error will be handled in a specific way....
So here is the bottom line: if it is unclear how an exception should be handled, let it propagate gracefully. There are many cases where a clear place exists to handle the exception internally, but there are many other cases where exposing the exception is better. So before you opt into handling the exception, just give it a second thought. A good rule of thumb is to only insist on handling exceptions when you are interacting directly with the end-user.
Error and Exception Handling
Don't worry too much about the what() message. It's nice to have a message that a programmer stands a chance of figuring out, but you're very unlikely to be able to compose a relevant and user-comprehensible error message at the point an exception is thrown. Certainly, internationalization is beyond the scope of the exception class author. Peter Dimov makes an excellent argument that the proper use of a what() string is to serve as a key into a table of error message formatters. Now if only we could get standardized what() strings for exceptions thrown by the standard library...
Exception-Safety in Generic Components - Lessons Learned from Specifying Exception-Safety for the C++ Standard Library
A non-generic component can be described as exception-safe in isolation, but because of its configurability by client code, exception-safety in a generic component usually depends on a contract between the component and its clients. For example, the designer of a generic component might require that an operation which is used in the component's destructor not throw any exceptions. The generic component might, in return, provide one of the following guarantees:
* The basic guarantee: that the invariants of the component are preserved, and no resources are leaked.
* The strong guarantee: that the operation has either completed successfully or thrown an exception, leaving the program state exactly as it was before the operation started.
* The no-throw guarantee: that the operation will not throw an exception.
Microsoft Design Guidelines Update: Exception Throwing
Most developers have become comfortable with using exceptions for hard error cases such as division by zero or null references. In the Framework, exceptions are used for both hard errors and logical errors. At first, it can be difficult to embrace exception handling as the means of reporting all functional failures. However, it is important to design all public methods of a framework to report method-failures by throwing an exception.
There are a variety of excuses for not using exceptions, but most boil down to the two perceptions that exception handling syntax is undesirable, so returning an error code is somehow preferable, or that a thrown exception does not perform as well as returning an error code. The performance concerns are addressed in the performance section below. The concern over syntax is largely a matter of familiarity and should not be a consideration. As an API designer we should not make assumptions about the familiarity of the application developers consuming our code.
* Do not return error codes. Exceptions are the primary means of reporting errors in frameworks.
* Do report execution failures by throwing exceptions. If a member cannot successfully do what is designed to do, it should be considered an execution failure and an exception should be thrown.
* Do not have public members that can either throw or not based on some option.
* Do not have public members that return exceptions as the return value or an out parameter.
* Do set all the relevant properties of the exception you throw.
* Do create and throw custom exceptions if you have an error condition that can be programmatically handled in a different way than any other existing exception. Otherwise, throw one of the existing exceptions.
* Do not use error codes because of concerns that exceptions might affect performance negatively.
* Consider the TryParse pattern for members which may throw exceptions in common scenarios to avoid performance problems related to exceptions.
* Do provide an exception-throwing member for each member using the TryParse pattern.
Exceptions
The reasoning is that I consider exceptions to be no better than "goto's", considered harmful since the 1960s, in that they create an abrupt jump from one point of code to another. In fact they are significantly worse than goto's:
They are invisible in the source code. Looking at a block of code, including functions which may or may not throw exceptions, there is no way to see which exceptions might be thrown and from where. This means that even careful code inspection doesn't reveal potential bugs.
They create too many possible exit points for a function. To write correct code, you really have to think about every possible code path through your function. Every time you call a function that can raise an exception and don't catch it on the spot, you create opportunities for surprise bugs caused by functions that terminated abruptly, leaving data in an inconsistent state, or other code paths that you didn't think about.
Try. Finally. If. Not. Null.
The presence of null in Java code is a clear indicator of code smell. Something is not right if you have to use null. The only place where the presence of null is justified is where we're using third-party APIs or JDK. They may return null sometimes because... well, their design is bad. We have no other option but to do if(x==null). But that's it. No other places are good for null.
Clean Code: A Handbook of Agile Software Craftsmanship
Returning error codes from command functions is a subtle violation of command query separation. It promotes commands being used as expressions in the predicates of if-statements.
(Page 46)
Create informative error messages and pass them along with your exceptions. Mention the operation that failed and the type of failure. If you are logging in your application, pass along enough information to be able to log the error in your catch.
(Page 107)
Often a single exception class is fine for a particular area of code. The information sent with the exception can distinguish the errors. Use different classes only if there are times when you want to catch one exception and allow the other one to pass.
(Page 109)
When we return null, we are essentially creating work for ourselves and foisting problems upon our callers. ALl it takes is one missing null check to send an application spinning out of control.... It's easy to say that the problem with the code above is that it is missing a null check, but in actuality, the problem is that it has too many. If you are tempted to return null from a method, considering throwing an exception or returning a SPECIAL CASE object instead. If you are calling a null-returning method from a third-party API, consider wrapping that method with a method that either throws an exception or returns a special case object.
(Page 109-110)
Top 20 Java Exception Handling Best Practices
Always catch only those exceptions that you can actually handle... Don't catch any exception just for the sake of catching it. Catch any exception only if you want to handle it or, you want to provide additional contextual information in that exception. If you can't handle it in catch block, then best advice is just don't catch it only to re-throw it.
Error handling: Exception or Result?
The first one is exactly the type of errors the Result class is intended for. If you know how to process a failure, let alone expect that failure to happen, there's no reason to use exceptions. It's much better to be explicit about your intent and represent the result of the operation as a value so that you can handle it later the same way you handle other values.
....
Alright, so here's the takeaway from this article: don't catch exceptions you don't know how to deal with. At all. The exception semantics is exactly what you need in this case: let the error bubble up and stop the current operation entirely. A corollary to this rule is that there's no benefit in wrapping such exceptions using the Result class (or any other return value for that matter).
It's pretty easy to differentiate use cases for Result and exceptions. Whenever the failure is something you expect and know how to deal with - catch it at the lowest level possible and convert into a Result instance. If you don't know how to deal with it - let it propagate and interrupt the current business operation. Don't catch exceptions you don't know what to do about.
....
You described a correct behavior for libraries. And it doesn't contradict the advice from the article.
As I mentioned in the post, if you don't know how to deal with some failure / situation, throw an exception. If you do know that, return a Result instance. Note that it's not the client of your library whose ability to deal with that failure you need to know about, it's *your*, library author's ability. In other words, if you as a library author don't know what to do with some failure, wrap it with your own exception and let it propagate further. For the client, the same failure might be an expected one so they can decide to convert it into a Result instance on their end.
Let's say for example that you write an ORM. Inability to connect to the database is a failure that you, as the library author, don't know how to deal with. The solution here is highly contextual and depends on the client application specific, you can't possibly know that specific. So the only way for you here is to throw an exception. On the other hand, the client of the ORM might expect their database to go offline from time to time, so for them, the failure is expected. In this case, they wrap your exception with a Result instance and deal with it as with a regular value from there.
Good Exception Management Rules of Thumb
If your functions are named well, using verbs (actions) and nouns (stuff to take action on) then throw an exception if your method can't do what it says it can... For example, SaveBook(). If it can't save the book - it can't do what it promised - then throw an exception. That might be for a number of reasons.
Want to use code from this post? Check out the license.
Reader Comments
Wow! I'm going to be coming back to this to let it "wash over me" for quite a while!
@Dominic,
Very cool - I hope you enjoy it and get some value out of it :)