
Programming Is Hard: Reconciling Server-Side And Client-Side "Clean" Architectures
CAUTION: You will likely get no value from this post. Be warned!
As you may have noticed, I haven't been writing very much lately. This is because I'm currently in a mental tar pit, struggling to make sense of "Clean" Architecture (as described by Uncle Bob Martin). Not only is the topic itself difficult to understand (at least for me), I find the very topic becomes even less clear when you consider the fact that both Server-Side code and Client-Side code can be built on the same principles. This post is nothing more than me trying to use the activity of writing as a way to attack the topic from a different angle, using different parts of my brain.
I once heard a man say (as best I can remember): "There are an infinite number of ways to succeed in life, but there is only one way to fail: stay in the same place." In that sense, I am currently failing - hard. I've been staring at the same 100 lines of JavaScript code for the past week, completely unable to find a path forward because my mental model for "clean architecture" is so poor.
Specifically, I am having trouble with managing erros in an application:
- How do I report errors within the core of the application?
- How do I ensure that errors expose the necessary contextual information for debugging?
- How do those errors get translated into user-friendly error messages for the user interface (UI)?
- How do I translate errors into HTTP status codes (if necessary)?
- Who is responsible for logging errors?
The moment I start to feel any sort of clarity on one of these questions, I get flummoxed when I remember that the answer should hold true - I think - for both Server-Side and Client-Side code. This is because the location of the code - Server vs. Client - is an "implementation detail." It describes the delivery mechanism of the core application logic. As such, the philosophical responsibilities of the "app core" should be location independent even if the concrete responsibilities are implemented differently.
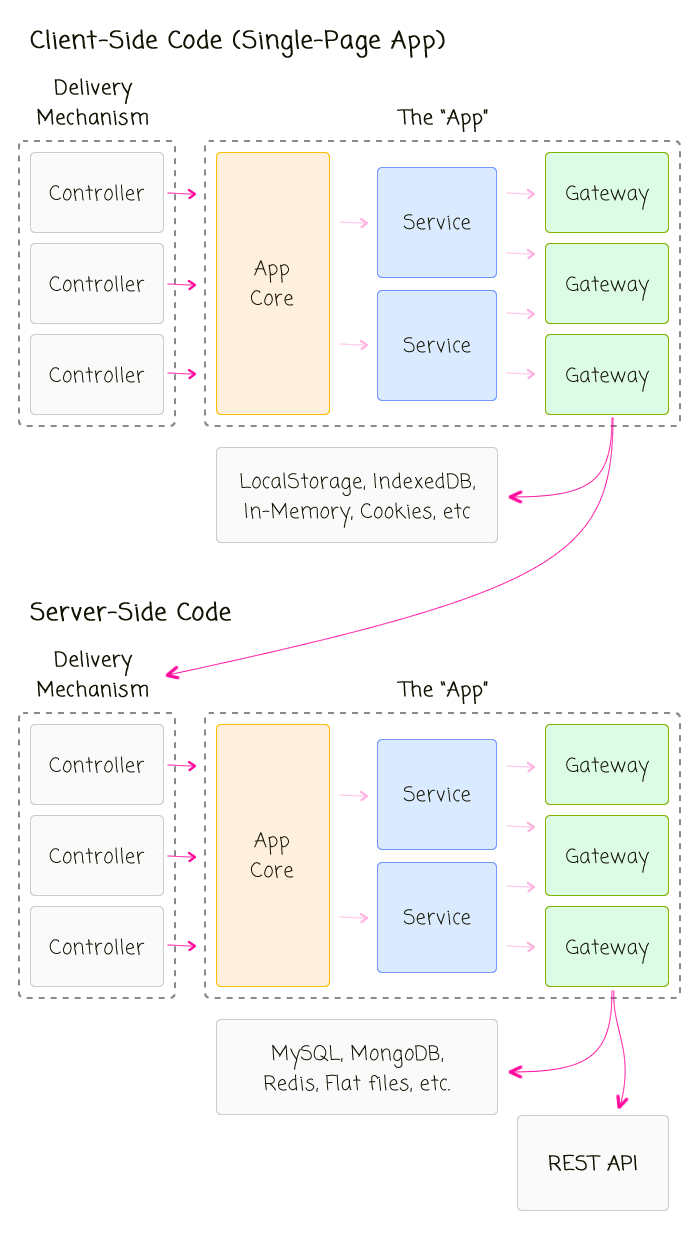
To help me noodle on this fact, I put together a diagram that attempts to show the common abstractions and workflow on both the Server and the Client:
| |
|
|
||
| |
 |
|
||
| |
|
|
Here, the very existence of the server-side code in this relationship is a mere implementation detail of the Gateway layer - it just so happens that a particular Gateway goes to a remote server instead of going to an in-memory cache or an IndexedDB database.
But, the real value-add of this diagram, for me, is the reminder that the nature of the Controller layer can be distracting. For example, in a Server-side REST application, the Controller uses more of a traditional request/response life-cycle, typically with a set of middleware or common controllers, that provide single-points of entry into the application. As such, the controller architecture may make it feel like logging errors should be the responsibility of the Controller since we can create a single catch-point for all errors that come out of the app core.
But, when you take that thinking and bring it over to the Client-Side, it starts to feel funny. The Client-Side code doesn't use a traditional request/response life-cycle. In a Single-Page App (SPA), a controller stays open, initiating successive requests against the app core based on the events triggered by the rendered View. So, in a Client-Side SPA, there's no single-point of failure to catch errors. And, in fact, if an error is allowed to bubble-up beyond an individual Controller, it may break the View (depending on the technology) or you may lose the ability to effectively report the error to the User.
Now, I'm not saying that it's not the responsibility of the Controller layer to log errors - frankly, I don't know the answer - it may very well be the Controller's responsibility. I'm just saying that the architecture and the transient behavior of a REST controller may make something appear to be true simply because it is "easy" to implement.
Anyway, I don't have much more to say on the topic because I do feel quite lost. I'm just hoping that the act of writing may have wiggled something loose in my head.
Reader Comments
It's hard to think about a lot of this stuff because none of it is in a vacuum. For example, if I decide that the App Core is responsible for logging errors, then it means that no errors can bubble up past the App Core boundary because you should never Log AND Rethrow an error - you do one or the other. So, if App Core is going to log, it CANNOT rethrow. This means that App Core is also responsible for translating the "raised error" into an "error response" from the App Core API.
On the other hand, if the App Core didn't have to log errors, it could simply set errors bubble up past the App Core boundary and let the Controller catch errors and log them.
I'm just saying this stuff is multi-faceted.
Hi Ben,
If you log the error in the code as close to where it happens then it will (probably) make it easier to debug.
Then your returning a response or dieing.
If your returning a oops response like a 500 then perhaps it's up to the requester to deal with that or die.
If your not going to stop or die then it probably makes sense to log at that point as well.
If each part of the application is responsible for its own requests then perhaps each part should be responsible for logging errors that occur whilst it's running?
Then I'm thinking of a big monolithic error logger everthing logs to so you can see a chain of logged errors when debugging later.
Perhaps passing responses after errors on to other components is a bit like a hospital pass in rugby and each would be better stopping rather than passing the problem on to the next component in the chain. So perhaps die and stop rather than cope.
Think I'm confused as well now :)
@Adam,
It's confusing stuff, right? Another issue that I keep wrestling with is what happens if I want to include data with the log-item that is not available within the app-core? For example, in the production app that I work with now, we currently log data like:
* User's IP address
* URL of the current request
* HTTP Referrer
* Machine name
... in my production app, which uses ColdFusion, we *happen* to be able to grab this stuff anywhere by breaking encapsulation and reaching into the globally-available CGI object. But, this is clearly hacky - any use of a global object is hacky, I think (which is why we try to quarantine it as best as possible).
But, if I did want to log that kind of data, I would likely have to perform the logging outside the app-core where I had direct access to the incoming and outgoing Request and Response object (such as in a Node.js Express app route handler).
Of course, maybe you could argue that I shouldn't need that kind of data with each log item - that the log item should be about debugging the actual error; but, I think the context of the request itself does help debug that kind of stuff. After all, the error might not be in the code - the error might be in the caller (sending bad data to the client) and the context information would help to figure out where that is coming from.
I was just going through the "Clean Code" Google discussion group and I came across this partial-quote from Uncle Bob Martin on doing some logging:
> The controllers, on the UI side, are the ones who figure out which
> use cases to activate. They also know who is activating those use
> cases. So they are in the best position to do the logging you are
> talking about. They could simply log the user, the request object,
> and the use case operation to be performed.
While I am taking this out of context a bit, he does seem to indicate that logging through be kept closest to the information that is *needed*. So, it sounds like if I want to log exceptions in the context of the request, it would be best to let exceptions bubble up outside of the *app core* and then catch them in the framework and log them there.
Source: https://groups.google.com/d/msg/clean-code-discussion/QevefQgWp5Q/G8QYXmtmtaYJ
This makes me think that the App Core should either return successful responses OR throw errors. I had thought about the App Core always returning a Response that may or may not be representative of a success or failure; but, I think that might just make life harder.
Philosophically speaking, is it the app core's responsibility to keep the app core "alive"? The more I think about it, the more I want to say No - that it is the responsibility of the Delivery Mechanism / Framework to ensure the app is kept alive.
@Ben
I to would want that info to provide the context when trying to debug the issue even if it is a bit hacky. The information you mention is a bit like the database key for the issue. Globals are legitimate to use, I think, if they didn't exist some would invent them :) and at least in Coldfusion you can clearly see its a global CGI.whatever.
I was reading this blog later on https://www.susanjfowler.com/blog/2016/12/18/the-four-layers-of-microservice-architecture
It mentions logging
"in microservice architecture, logging and monitoring should be centralized and standardized, independent of the individual microservices"
For me it seems to make sense to log errors server side and then return proper error status codes to the client and then let the client code deal with an appropriate action (display error to user etc).
I think is partly because conceptually server side is the REST API server which is responsible for all data / business logic, a dumb HTTP server for flat files and then the SPA client side. We haven't got to an isomorphic application yet so maybe this makes things easier as there is a more traditional separation of duty.
I agree it would be great to track all steps that a specific client took before the error arose and It should be possible to tag each request to identify the originating client to build up an audit of what that client did and who they are (Browser etc). Maybe some form of custom HTTP Header with a unique key which is then returned back to the server for subsequent calls.
We use papertrail - https://papertrailapp.com/ for logging and assuming you have the identifier you should be able to filter all logging requests easily.
@Adam,
I use global objects in my code, but it never feels right. It's more like I needed to get some data, but didn't realize it until much later, and then instead of refactoring the request workflow to pass that data around, I just break encapsulation and grab it out of nowhere. I'd feel more comfortable actually passing data down through the call-stack as needed. And, if that becomes overly tedious, then maybe that is an indication that something else is wrong.
@Mark,
I definitely agree that the server should return a nicely packaged "error response" as opposed to a plain Error as we definitely don't want to expose any implementation and stack trace details to the public. But, I think the server-side controller can catch server-side exceptions and do that kind of packaging.
Now, here's where I am currently getting very stuck. In the "clean architecture", the User Cases (what I was calling my "app core") talks to data persistence. On the server, this points to the database; but, on the client, this points to an API call ... OR... maybe it points to in-memory or localStorage stuff. The problem is, these are not all equivalent data storage implementations. For example, while it may be trivial - cost wise - to get entities out of a LocalStorage implementation, if we're pointing to a remote API, retrieving data is relatively expensive (if there are even API end-points that will facilitate it). Which makes me wonder, is the "Use Case" architecture fundamentally different if the data persistence is a "remote system" as opposed to a "local system."
Am I right in thinking that when you're talking about Controllers on the front end, you're specifically thinking about the "Angular/AngularJS" "thing" that is called a Controller? I think that the problem is that Controllers, Factories, and Services as defined in Angular don't at all map to the "real" programming concepts. And in fact, they acknowledge this somewhat by calling it MVVM (model-view-viewmodel).
Forgive me a moment, because I'm going to digress into a bit of Flash/Flex history. I'm doing this because a lot of good OOP resources were written by people who worked in those technologies. An Angular Controller is more what would have been called a Presentation Model (http://blogs.adobe.com/paulw/archives/2007/10/presentation_pa_3.html) in Flex and probably other related technologies like Java. Basically what a Presentation Model is is a Class that manages a specific piece of UI data and exposes properties and methods for the View to "glom onto." Presentation Models should only be responsible for allowing the user to interact with the data--that's it. Once the interaction is done, the Presentation Model hands the revised data back to the Controller, which then has the responsibility to decide what should be done with that change.
The problem in Angular is that this business logic layer is completely missing as a concept, so to implement that type of Controller you actually have to put it in a Service. (Don't even get me started on how making the View Controller/Presentation Model tightly coupled with the Component in Angular kind of sucks). Once your business logic is no longer part of a View controller, but is conceptually sitting *between* the View Models and the Services that are doing what Services ought to do and just communicating with the back end, that does become one place that is logical to handle errors.
Oh, and you might want to look at AlaSQL for abstracting between localStorage and NoSQL databases. If you write your relational DB services to return the same format, you can probably also use it for those as well.
@Amy,
To be honest, I don't really understand the finer points of the MVC vs. the MVVM vs. the MV* stuff. The way I see it, the "Controller" (and yes, I'm generally thinking about Angualr since that's what I use), acts as the traffic director between the View and the Business Logic. I will definitely concede that many Controllers have way more logic than they should - I am just as guilt of this as anyway; but, the Controller is still taking "requests" from the user and piping them into some soft of "service" that often abstracts the back-end.
Part of what brought all of this up in my mind is that I am currently working on a project (though getting often very distracted) that is trying to implement "Use Case", ala Uncle Bob Martin. So, in that case, the Controller is really taking requests from the View and directing them into Use Cases, that manage all of the business logic (by talking to various other services and so forth). Perhaps that makes things more clear.
I was making good progress until I start to trip over how I wanted to return Errors (and logging of those errors - tying it back to this post). Then, I got frustrated and distracted. I need to get back on that :D
In his architecture video on clean coders Uncle Bob considers the MV* pattern as Presentation tier so I kept my Use-Cases as a layer on the server side in my app. Communicated to them from angular controllers via angular services.
As web-apps get more complex you probably can justify a use-case layer on the frontend itself. Which sounds like what you have Ben.
Amy - I know what you mean they really should of properly facilitated business logic as concept with Angular . It was a problem that I struggled with whilst learning angular.
In the end I used Angular Services that returned constructor functions for business objects this allowed me to inject the constructors wherever I needed to create new instances.
Worked nicely though it feels like abit of an abuse of dependency injection and potentially angular 'services' but there was never any real guidance from angular on what the role of their 'services' is.
@Rob,
The thing that got me thinking about all of this is that I am in the process (though very distracted at the moment) of building an Angular 2 application with PouchDB that is intended to be a stand-alone application that *can* sync data to a remote data store if it needs to. So, in my case, there is no server-side code that holds the "business logic"; as such, the client has to do the orchestration. Which got me thinking - is this a "special case"? Or, is this just "the way" it should be done and the fact that there is no server-side logic an "implementation detail"?
The problem that I keep coming up against is that there are performance considerations that I have to take into account when I know that I am going to a server or staying on the client. And, I am not sure if that is a "smell" that I am doing something wrong. Or, if at some point, you have to have some "leaky abstraction" in order to make practical decisions.