
Using Structs As Data Lookup Indices In ColdFusion Data Manipulation
At InVision App, I've been working a lot with query optimization, data caching, and general performance. Often times, this means simplifying queries, breaking apart JOINs, and moving data munging into the application layer where the cost of processing can be distributed by the load balancer (so to speak). One technique that I've found completely invaluable for data munging is the use of the ColdFusion struct as a fast-access key index. Think of this like a database table index that you can build explicitly in memory.
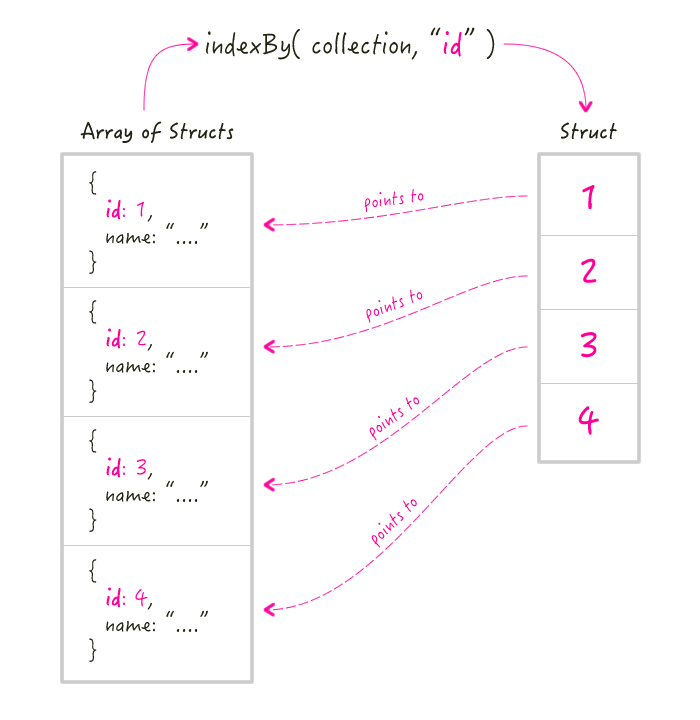
A struct index helps you locate an item when all you have is an item identifier (typically a primary key of some sort). So, for example, you have user ID "4" and you need to access the in-memory user with that ID. If you have a struct index of user IDs, you can quickly retrieve the target user without having to use array iteration or functions like arrayFind() or arrayContains().
I should say that nothing that I'm talking about here is actually ColdFusion specific. I use the same techniques all the time in JavaScript; though, I find that I have to munge data on the server (in ColdFusion) more often than I have to munge data on the client (in JavaScript) - typically because it's already been munged on the server.
And, in fact, when I create these struct indices in ColdFusion, I use a few choice methods that I directly lifted from popular JavaScript libraries like lodash and underscore. The ones that I use most often are:
- indexBy( collection, key )
- groupBy( collection, key )
- reflect( values )
- pluck( collection, key )
To illustrate the generation and subsequent consumption of these ColdFusion struct indices, I tried to put together a few scenarios that mimic how I munge, manipulate, and combine data after I've pulled it back from the data persistence layer.
In this first demo, I'm taking a collection of movie objects and creating a struct index based on the movie ID. Then, as I loop over a subset of the movie IDs (watched by a given user), I can quickly access the movie detail based solely on the ID:
<cfscript>
// Here is a collection of movies, each of which as a unique ID.
movies = [
{
id: 1,
name: "Hackers"
},
{
id: 2,
name: "Purpose"
},
{
id: 3,
name: "DOT"
},
{
id: 4,
name: "Antitrust"
},
{
id: 5,
name: "War Games"
}
];
// Here is a collection of movie IDs that represent the movies that the given user
// has watched.
moviesSeenByUser = [ 1, 3 ];
// We want to output the names of the movies that the user has watched. Since we
// have the IDs of the movies, we need a way to access the movie data based on ID.
// We can facilitate this by creating an ID-based index of the movie collection.
// This will give us a struct that allows quick access to each movie.
moviesIndex = indexBy( movies, "id" );
// Now that we have the ID-based index, we can loop over the IDs associated with
// the user and look each ID up in the index.
for ( movieID in moviesSeenByUser ) {
writeOutput( "User has seen: " & moviesIndex[ movieID ].name & "<br />" );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I take the given collection and return a struct whose keys point to items within
* the collection. The struct keys are determined by the given collection key.
*
* @collection I am an array of structs.
* @key I am the property within each item that will be used as the index value.
* @output false
*/
public struct function indexBy(
required array collection,
required string key
) {
var collectionIndex = {};
for ( var item in collection ) {
collectionIndex[ item[ key ] ] = item;
}
return( collectionIndex );
}
</cfscript>
When we run this code, we get the following output:
User has seen: Hackers
User has seen: DOT
In the second demo, I'm rotating the first demo; and, instead of displaying the movies the user watched, I'm listing all movies and then, for each movie, indicating whether or not the user has watched it. This time, I don't need quick access to the movies (since I'm iterating over all of them); but, I do need to quickly check which movie a user has watched. Since this information isn't represented as an array of struct, but rather as a collection of IDs, we'll use the reflect() function to generate the index:
<cfscript>
// Here is a collection of movies, each of which as a unique ID.
movies = [
{
id: 1,
name: "Hackers"
},
{
id: 2,
name: "Purpose"
},
{
id: 3,
name: "DOT"
},
{
id: 4,
name: "Antitrust"
},
{
id: 5,
name: "War Games"
}
];
// Here is a collection of movie IDs that represent the movies that the given user
// has watched.
moviesSeenByUser = [ 1, 3 ];
// We want to output the collection of movies and, for each one, indicate whether
// or not the user has seen it. Since we have the IDs of all the movies that the
// user has watched, it would be great to have a way to quickly look up each ID.
// We can facilitate this by reflecting the ID collection, creating an index in
// which each ID becomes a key.
moviesSeenByUserIndex = reflect( moviesSeenByUser );
// Now that we have the ID-based index, we can loop over the movies and quick check
// to see if the movie has been watched.
for ( movie in movies ) {
// NOTE: You could have also used the arrayContains() function to check the
// existence of the ID. But, that would require ColdFusion to iterate over the
// ID array for each movie. That may or may not be more efficient, depending
// on the shape of the data. I personally find the "index" approach easier to
// reason about most of the time.
action = structKeyExists( moviesSeenByUserIndex, movie.id )
? "seen"
: "not seen"
;
writeOutput( "User has #action#: " & movie.name & "<br />" );
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I take the given collection of simple values and return a struct in which each
* value becomes a key that points back to itself.
*
* @values I am an array of simple values.
* @output false
*/
public struct function reflect( required array values ) {
var reflectedValues = {};
for ( var value in values ) {
reflectedValues[ value ] = value;
}
return( reflectedValues );
}
</cfscript>
When we run this code, we get the following output:
User has seen: Hackers
User has not seen: Purpose
User has seen: DOT
User has not seen: Antitrust
User has not seen: War Games
In the final demo, I have a collection of "movie watch events" that JOINs users to movies. For each user in the watch collection, we want to output the movies that the user has watched. To do this, we are going to group the watch collection by the user ID. This creates a struct index that maps user IDs to watch events. Then, we'll also create a movie index so that we can quickly access movie details by movie ID.
<cfscript>
// Here is a collection of movies, each of which as a unique ID.
movies = [
{
id: 1,
name: "Hackers"
},
{
id: 2,
name: "Purpose"
},
{
id: 3,
name: "DOT"
},
{
id: 4,
name: "Antitrust"
},
{
id: 5,
name: "War Games"
}
];
// Here is a collection of "watch" events for users and movies (ie, which user
// watched which movie on which date).
userMovies = [
{
userID: 1,
movieID: 1,
watchedOn: "Mar 29, 2016"
},
{
userID: 2,
movieID: 2,
watchedOn: "Mar 28, 2016"
},
{
userID: 3,
movieID: 1,
watchedOn: "Mar 21, 2016"
},
{
userID: 1,
movieID: 3,
watchedOn: "Mar 28, 2016"
},
{
userID: 3,
movieID: 4,
watchedOn: "Mar 03, 2016"
}
];
// For each user, we want to indicate which movies that user has watched. To
// facilitate this, we can group the "watch" collection by the user ID. That will
// give us a collection of watch events for each user ID.
moviesByUserIndex = groupBy( userMovies, "userID" );
// The watch collection, while grouped, still only contains IDs. As such, we'll want
// to quickly look up the movies by ID. To facilitate that, we can index the movie
// collection by ID.
moviesIndex = indexBy( movies, "id" );
// Now, all we have to do is loop over each user's watch group and grab the movie
// based on the watched ID.
for ( userID in moviesByUserIndex ) {
for ( watched in moviesByUserIndex[ userID ] ) {
writeOutput( "User #userID# has seen " & moviesIndex[ watched.movieID ].name & "<br />" );
}
}
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I take the given collection and return a struct whose keys point to individual
* collections of items that each had the same property value (corresponding to the
* given key value).
*
* @collection I am an array of structs.
* @key I am the key by which to group items in the collection.
* @output false
*/
public struct function groupBy(
required array collection,
required string key
) {
var groupIndex = {};
for ( var item in collection ) {
if ( structKeyExists( groupIndex, item[ key ] ) ) {
arrayAppend( groupIndex[ item[ key ] ], item );
} else {
groupIndex[ item[ key ] ] = [ item ];
}
}
return( groupIndex );
}
/**
* I take the given collection and return a struct whose keys point to items within
* the collection. The struct keys are determined by the given collection key.
*
* @collection I am an array of structs.
* @key I am the property within each item that will be used as the index value.
* @output false
*/
public struct function indexBy(
required array collection,
required string key
) {
var collectionIndex = {};
for ( var item in collection ) {
collectionIndex[ item[ key ] ] = item;
}
return( collectionIndex );
}
</cfscript>
When we run this code, we get the following output:
User 3 has seen Hackers
User 3 has seen Antitrust
User 2 has seen Purpose
User 1 has seen Hackers
User 1 has seen DOT
You might be looking at all of this data manipulation and think to yourself that you could more easily accomplish the same thing in a SQL statement with some INNER JOINs and some EXISTS() sub-queries. And, you might be right. But, the long-term issue with doing this in the database is that you create single point of processing (or maybe a few points of processing with some read-replicas). That puts load on the database server in a way that is harder to scale. If you can move some of that processing out of the database and in to the application servers, you can distribute that processing through the load balancer to any number of machines, in a way that's much easier to scale.
But, this isn't really a conversation about scalability, it's a conversation about how you can use the ColdFusion struct data type as an in-memory index for fast data access. I honestly use this approach daily and it makes data munging so much easier. Creating a collection index has some upfront cost (a full collection iteration); but, that cost is generally paid for in terms of simplicity in subsequent iterations of the data.
Want to use code from this post? Check out the license.
Reader Comments