
Ask Ben: Converting A Parent-Child Data Table Into A Nested XML Document
Recently, I was asked a question about taking parent-child hierarchical data records and converting them into a nested XML document. Whenever you deal with a parent-child relationship in which the depth of nesting is indeterminate, you get into a situation where you will probably have to hit the database a number of times. So for example, if I had a data table like this (as did the person asking the question):
Columns: id, parentID, name
... I would have to gather the records in a step-wise fashion. That is, I would get all the top level records. Then, I would get all of their children; then I would get all of their children; and so on until I hit a depth in which there were no more relevant child records.
If all of the records in the data table pertain to a single hierarchy, it's not so much of a problem since you can get all the record in one select. However, if one data table contains more than one hierarchy, then you might have an enormous number of rows in which only a few pertain to your hierarchy. In such a situation, I sometimes to like to add a table column for a given tree such that I can quickly find all the related records, even if not in any particular order:
Columns: id, parentID, treeID, name
In this case, all records that pertain to a given hierarchy would have the same treeID. Typically, the treeID would be the same as the ID of the most parent record in a given hierarchy; however, you could just as easily create a separate table that contains the treeID along with meta data about the tree.
I like this approach because it allows me to get out of the database context as quickly as possible. And once I have the sub-set of records that pertain to my hierarchy, I can easily manipulate those programmatically (outside of the database - our biggest bottleneck) in order to render an XML document.
In the following example, I am going to explore a few recursive approaches to building such an XML document. For demonstration purposes, I am assuming that all records in my dataset pertain to the given tree; however, you could easily replace my query variable with subsequent requests to the database if such an assumption cannot be made.
Before we look at the code that builds the XML document, let's build our query object. Since I don't have a true database, I am going to construct a ColdFusion query object manually:
<!---
Create our in-memory database table. This will be a parent-child
table in which eacn node can be a child of another node.
--->
<cfset nodeTable = queryNew( "" ) />
<!--- Add the ID column. --->
<cfset queryAddColumn(
nodeTable,
"id",
"cf_sql_integer",
listToArray( "1,2,3,4,5,6,7,8,9" )
) />
<!---
Add the parent ID column (each node can be a child of
another node).
--->
<cfset queryAddColumn(
nodeTable,
"parentID",
"cf_sql_integer",
listToArray( "0,1,0,3,3,0,6,7,8" )
) />
<!--- Add the name column. --->
<cfset queryAddColumn(
nodeTable,
"name",
"cf_sql_varchar",
listToArray( "A,B,C,D,E,F,G,H,I" )
) />
As you can see, I am creating a query object with three columns: id, parentID, name. This is the parent-child "database" that we are going to convert into a nested-node XML document.
Approach One: Recursive ColdFusion Function
In this approach, we are going to use the CFXML tag and a single ColdFusion function to recursively build the XML document from the root node, down. Basically, we are going to output the root node and then all of its child nodes; which, in turn, output all of their child nodes; which, in turn, output all of their child nodes; and so on until no more child nodes can be found.
<!---
In our first approach, we are going to use a brute force approach
in which we simply create a series of query-of-queries to figure
out which children below to which row.
To make this a little cleaner, we are going to factor the
querying out into a method that we can call recursively from the
top down.
NOTE: This function has OUTPUT=TRUE so that it can add contenct
directly to the CFXML content buffer.
--->
<cffunction
name="outputChildNodes"
access="public"
returntype="void"
output="true"
hint="I output the child nodes based on the given query and the given given parent ID.">
<!--- Define arguments. --->
<cfargument
name="nodeTable"
type="query"
required="true"
hint="I am the node query object."
/>
<cfargument
name="parentID"
type="numeric"
required="false"
default="0"
hint="I am the optional parentID of the node for which we are outputting children."
/>
<!--- Define the local scope. --->
<cfset var local = {} />
<!--- Query for the child nodes. --->
<cfquery name="local.childNodes" dbtype="query">
SELECT
id,
parentID,
name
FROM
arguments.nodeTable
WHERE
parentID = <cfqueryparam value="#arguments.parentID#" cfsqltype="cf_sql_integer" />
ORDER BY
id ASC
</cfquery>
<!--- Output each child node. --->
<cfloop query="local.childNodes">
<node
id="#local.childNodes.id#"
parent-id="#local.childNodes.parentID#"
name="#local.childNodes.name#">
<!---
Now that we are inside this node, we need to see if
it has any children. Call THIS function recursively,
moving down the parent chain.
--->
<cfset outputChildNodes(
arguments.nodeTable,
local.childNodes.id
) />
</node>
</cfloop>
<!--- Return out. --->
<cfreturn />
</cffunction>
<!--- Build the node XML document recursively. --->
<cfxml variable="nodeTree">
<nodes>
<!--- Output the root-level nodes. --->
<cfset outputChildNodes( nodeTable ) />
</nodes>
</cfxml>
<!--- Render the XML document. --->
<cfdump
var="#nodeTree#"
label="Node Tree"
/>
As you can see, we have defined a ColdFusion user defined function, outputChildNodes(), which takes our "database" and the parentID in question. This UDF then outputs all of the child nodes for the given parentID, which in turn, recursively calls itself in a depth-first recursive algorithm. Each recursive call passes in a new parentID to help build the resultant XML document.
When we run this code and CFDump the resultant XML document, we get the following:
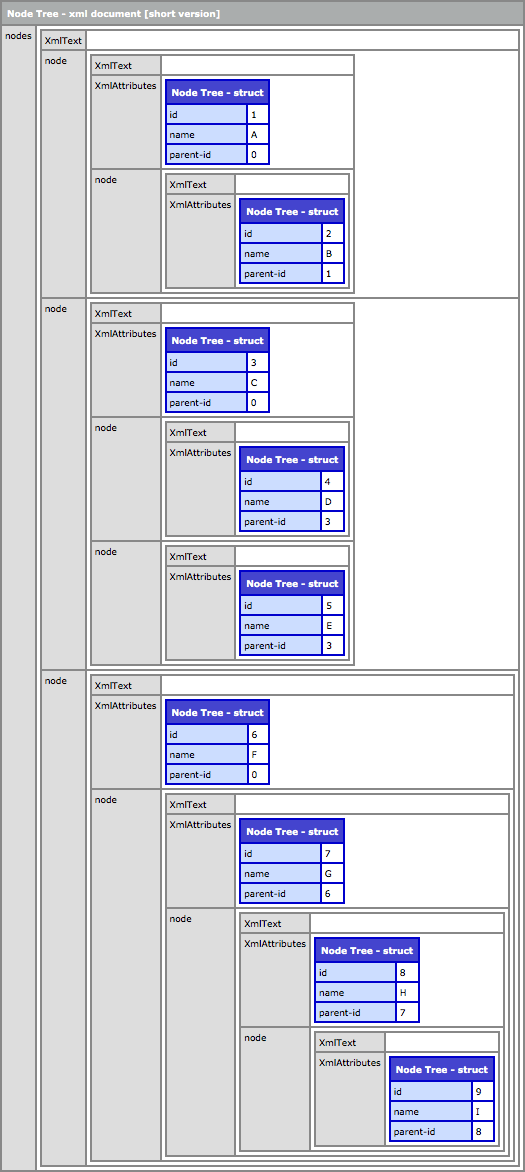
As you can see, we have successfully turned out parent-child database table into a nested-node XML document.
Approach Two: Recursive XML Transformation (XSLT)
In this approach, I mostly wanted to dust off some older parts of my brain to see if they still work (following the whole Use it or lose it philosophy). We're still going be using a recursive approach; however, this time, instead of calling a ColdFusion UDF, we're going to use XSLT to recursively transform one XML document into another.
In order to use XSLT and ColdFusion's xmlTransform() method, we need two XML documents: the original XML document and our XSLT definition. In our case, we're going to create the original XML document by converting our parent-child data table into a single-level XML document in which each node represents one record in our data table. Then, our XML transform will convert that non-hierarchical document into the desired nested-node XML document.
<!---
In this approach, we are going to create an XML representation of
the database in which each record is a NODE element. This initial
XML tree will not be hierarchical - it is simply one node per
database table row.
--->
<cfxml variable="rawNodeTree">
<cfoutput>
<nodes>
<!--- Output a node element per data table row. --->
<cfloop query="nodeTable">
<node
id="#nodeTable.id#"
parent-id="#nodeTable.parentID#"
name="#nodeTable.name#"
/>
</cfloop>
</nodes>
</cfoutput>
</cfxml>
<!---
Now, we are goint to transoform the flat XML document into a
nested XML document using a recursive template match.
--->
<cfxml variable="xslt">
<xsl:transform
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<!--- Start by matching the root node. --->
<xsl:template match="/nodes">
<nodes>
<!---
Inside our new root node, output all the top-
level NODE elements (ie. those with a parentID
value of zero).
--->
<xsl:call-template name="getChildNodes" />
</nodes>
</xsl:template>
<!---
This function outputs all child node elemenst of the node
with the given ID.
--->
<xsl:template name="getChildNodes">
<!--- Param our parent ID. --->
<xsl:param name="parentID" select="0" />
<!---
Select all the child node elements that have the
given parentID.
--->
<xsl:for-each select="//node[ @parent-id = $parentID ]">
<!--- Sort this node list on ID. --->
<xsl:sort select="@id" />
<!--- Output the new node. --->
<node
id="{@id}"
parent-id="{@parent-id}"
name="{@name}">
<!---
Now that are outputting a given node, let's
output all the child nodes that might be a
descendant of it.
NOTE: This is the recursive aspect of this
XSTL approach.
--->
<xsl:call-template name="getChildNodes">
<xsl:with-param
name="parentID"
select="@id"
/>
</xsl:call-template>
</node>
</xsl:for-each>
</xsl:template>
</xsl:transform>
</cfxml>
<!---
Transform our flat XML node document into the nested node
XML document.
--->
<cfset result = xmlTransform( rawNodeTree, xslt ) />
<!--- Output our new node tree. --->
<cfdump
var="#xmlParse( result )#"
label="XSLT Tree"
/>
In this approach, rather than an outputChildNodes() UDF, we've created a getChildNodes template. In the magical land of XSLT, a template can be invoked sort of like a function (very loose interpretation); and in our case, this getChildNodes template is recursively invoked for every child node that needs to be output.
When we run this code and CFDump out the resultant XML document, we get the following:
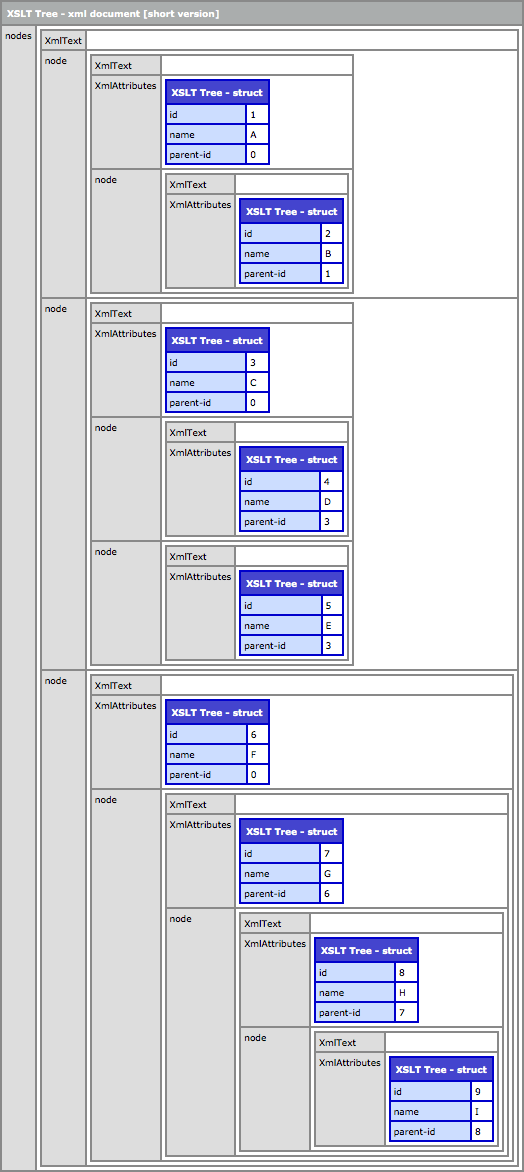
As you can see, this approach works. However, working with XSLT is not what you'd refer to as "fun." Again, I present this option mostly for the sake of variety and brain food. This approach does assume that you can boil your data table down to a single XML document before you transform it. However, if you need to hit the database more than one time in order to make this happen, you'd be much better off just going with something like my first ColdFusion UDF approach.
Recursion is awesome. But, recursively hitting a database is not so cool. Most of the time, the database interactions in our applications create the bottlenecks for performance. As such, I'd like to be able to pull parent-child data out of the database with a single query. I think some of the newer databases actually support this concept inherently. But, if they don't, I like to provide a key that groups all nodes in a given tree together. This way, once we have the records in our application server, it's quite easy to transform them into a properly nested hierarchy.
Want to use code from this post? Check out the license.
Reader Comments
Ben! Thank you for this... what a great way to handle such a scenario. I would've never had thought to use xmlTransform to solve this.
@Amanda,
Yeah, the xmlTransform() was more for fun than anything else (if you can image that anyone in their right mind would do anything with XSLT for fun :P). The biggest problem with it (other than XSLT is hard) is that is requires all records to be available beforehand. If you need to go back to the database more than once to gather the related records, this latter approach becomes much less feasible.
In any case, it was a fun thought experiment!
This is actually something I try and do on the database side if the DB supports it. I could probably do this as a single select statement in oracle.
Of course, having many different methods to get the same response is always useful!
@Frank,
I knew that some database could support recursion, but I have never actually done it myself. I think the first time I had ever seen it was SQL Server 2005 (or was it 2008). But by that time, I had actually switched over to MySQL for most things. I am not sure that MySQL supports it in any version (although I could be way wrong).
Seems like a tremendously powerful feature of some RDMS.
As usual, great article!
Something that may be of interest in the same general direction - I needed to do something similar a while ago and based my solution on a udf from cflib; it takes a slightly different approach, taking the base query for the data, sorting it with structs and creating a return query that you can then work with for outputting, the advantage being only one trip to the database.
http://cflib.org/udf/queryTreeSort
@Frank & @Ben,
I know how you feel. I always try to do this on the DB side if possible. I have always worked with Oracle DB's at work, and when i tried to this on my own projects on MySQL at home I quickly got frustrated. I found Oracle's connect by (http://www.adp-gmbh.ch/ora/sql/connect_by.html) so so so so useful.
There are ways to emulate heirarchial data queries in MySQL. The MySQL website suggests adding extra fields to support it ( http://dev.mysql.com/tech-resources/articles/hierarchical-data.html )
, and I have seen other methods through stored procedures (IIRC thats what they are called in mysql :S), but whatever way you do it, it is ugly.
Basically with MySQL i have always done it programatically, rather than through the query - seemed easier
@Rafe,
Oh man I wished I had found that udf before today - thanks for that link :)
The best approach to this challenge is to simply not use the parent/child model to represent a hierarchy: it's a fairly leaden approach to effecting such things. It's easy to understand, and easy to update, but it's terribly inefficient to read: this whole recursion thing you mention.
A far superior approach is the "nested set model" (as Joe Celko describes it), which uses a left & right tag to place each node in the hierarchy, rather than just a single parent tag.
There's a performance hit on doing tree updates (although it's only two queries to do so, the queries hit every row in the table), but reading from the tree, especially hierarchically, is much much faster than the parent/child model: one simple query to return all ancestors or all descendants.
And in the web environment when data is being read and multiple orders of magnitude more frequently than it's being written, it's a much better solution.
Personally I use a hybrid of the two: I tag all of left, right and parent, because having the parent tag there is handy for extracting parent, siblings or children (children as opposed to descendants), which requires a fairly complex query if one has only a left & right tag. And the requirement for extracting siblings & children is a fairly common requirement in web applications (left nav, for argument's sake).
--
Adam
@Rafe,
Thanks for the link, I'll check it out.
@Richard,
That looks like a really interesting read as well. I like anything that outlines various approaches ;)
@Adam,
A friend of mine tried to explain the nested set model to me a while back; he was drawing it on paper and I was totally lost as to what he was saying. But, he said basically the same thing you did - that its costly to update (which is rare) and much much faster / easier to read. Looks like this is definitely something to read up on.
I don't yet understand your hybrid approach. Let me read up on the nested set model.
@Adam,
Like @Ben, it also took me a while to get my head around the nested set model - and it didnt seem practical enough for me to want to use it. Maybe i should take another read...
I imagine the performance hit would be completely dependant on the record set you were working on. If a heirarchy was updated all the time (eg if you had a heirarchial comment system {think like the slashdot.org system}) which could be potentially updated once for every 10 reads (i did say potentially :P) would it still be worth it?
As if you only retrieving comments for that particular post, wouldnt the number of iterations over the comments to sort them into a parent/child in this case outway having a poperly nested set (if you need to update a large number of rows for each update)?
Hi Richard
I think you'll find that slashdot, whilst getting comparatively a lot of "write" traffic is still getting far far far more "read" traffic.
Think about it... a "busy" slashdot article has a few hundred comments on it. But the "slashdot effect" - which is based on people reading an article then visiting the site mentioned in the article - frequently generates so much traffic on the target website it knocks over ever fairly big websites. So that's hundreds of comments vs 10s or 100s of thousands of hits to the "target" site from slashdot readers. And that's just the conversion rate of people who read an article, and then decide to click onwards to visit the site in question... with a conversion rate of 5% (random figure), that's a *bagload* of "read" traffic on the slashdot site.
Honestly... the ratio of read/write on a website scales up irrespective of how much the site is encouraging its users to make updates. And it's always grossly in favour of reads.
I also think it's a bit specious to pluck one of the busiest websites out there and using it as an example as to how something might or might not work. Pitch yourself at a more realistic level for the work we CF developers are likely to be doing, and then make your assessment.
--
Adam
Hi Ben
I only know one person who looked at a diagram of how nested sets worked and went "oh yeah, makes sense" the first time he saw it. It took me a few hours of drawing circles with numbers in them, and lines and arrows and working through the CRUD algorithms on bits of paper before I finally went "oh *right*".
I'll try to knock together a diagram I use to explain it to my colleagues, scan it and email it over to you tomorrow (OK... it's 1am... later today).
--
Adam
@Adam,
Myabe it was a bad idea to use slashdot as an example.
I was just really trying to think of an example where there were alot of and comments and articles in that kind of structure.
It was meant to be a theoretical question rather than realistic.
One question I had was that you didn't seem to have the actual database call just QofQ <cfquery>s so I couldn't tell for sure whether you were actually storing a 0 in the parentID field of root nodes or if you were using ISNULL or something similar to just return 0's inplace of nulls. Think the isnull approach is better because it allows for using referential integrity/foreign keys database side. I have used this method in a cfc with the actual DB query stored in the "This" scope and using the result to populate a flex tree.
Maybe I am wrong but a "nested set model" approach seems to be great if you want to know how many descendants a record has at any level, whether one element is a descendant of another would also be trivial, it seems to make starting with a descendant and getting all ancestors in order trivial as well(great for breadcrumb type situations that you only want one element per level), and it does have a natural ordering built into the structure(although in my experience alphabetical or date based sorts would be the order desired). But it doesn't seem as well suited to building a tree as the "adjacency list" approach, in-fact it seems quite clumsy to determine whether a element is a direct descendant of another and it doesn't seem to be well suited for multiple root type structures. Maybe I am missing something and would benefit from a real code example of SQL and CF building a tree this way but from reading that is the sense I get.
David, *precisely*. That's why I have modified the model for my own uses to include the parentId as a tag too. So I use the left/right tags for hierarchical queries, and the parent tag for lateral ones: the best of both worlds, and not really any additional maintenance overhead.
The thing is that with the nested set model - the standard one, without the parent - whilst the query to pull out siblings or parents is slightly complicated (sufficiently so that I don't recall it off the top of my head like I would the "getAncestors" or "getDescendants" one), it's still performant. With the "adjacency list model" as Celko and yourself refer to it (although as far as I can tell, this does not distinguish the parent/child model from the nested set one because "adjacency list" just means "has some data about the nodes it connects to", which both these models have), the recursive process to get hierarchical information is both complicated (in as much as people often don't find recursion straight forward) and non-performant. I don't see a "win" with it.
That said: recursive processing on Oracle with connect-by-prior, as with pretty much anything to do with Oracle, really is pretty quick. And my - limited - experience with the equivalent on SQL server with CTEs is pretty good to (although almost completely incomprehensible to me, compared to "connect by prior"). But there's still a lot of work going on there, and a lot more than "where left > node and right < node" which is all one needs to do with the NSM.
I come from the position of having used both models on moderately-sized systems (100000s of rows), and in each case, the NSM... err... *shits all over* the ALM (indeed the ALM model cacked out long before needing to work with a hierarchy that large, on the kit we had). I invite anyone who decides to have a speculative but otherwise not-based-on-experience opinion on this to try it out and come back with your findings.
--
Adam
Richard, it's easy: go to the Adobe CF forums. Or any specific "forum" website. These are intrinsically examples of a higher-than-usual ratio of writes to reads.
But think about it: to get to the point where one can "write", one has to first navigate ("read") to the location where one clicks the "I want to post something" button. So there's already a bunch more reads for anyone who is spefically trying to "write": because their form posting only effects one "write". And this is before one stops to consider that the bulk of forum users don't post, they search or just read.
I agree it's entirely possible to identify a system in which there is more writing going on than reading, but I doubt it would be a web site / application environment.
And, equally, everyone who espouses the nested set model does temper their espousal with "it's not a panacea: writes are slow" (just like I did, when I first mentioned it, above). We know. We told you that from the outset. So if you *do* have a system in which it's writing more than reading, *don't use it*. This however doesn't mean it's not a better solution that the parent/child model for almost all applications readers of this blog will be faced with.
--
Adam
I think this calls for some testing.
I guess one of the things I have the hardest time thinking about is how you would go about updating the hierarchy in the DB to reflect changes like one node(and its descendants) being move to a new parent, insertions and deletes are doable but I can't seem to visualize a straight sql process that would allow all the renumbering needed to move nodes while maintaining the relationships of the nodes.
One other concern I would have is that since writes are time consuming and need to be isolated for renumbering that you would have to have locking on the entire table(or tree if the table stores multiple separate trees, like comments tied to a specific thread) for relatively long periods of time which on large trees seems could lead to big problems. It just seems to me that you can't have a very efficient system if adding or deleting(or moving) nodes means modifying every single record in a table, it seems to violate the spirit of normalization.
@Adam,
I was gonna read up on it last night... but I got sucked into Stoyan Stefanov's new book, Javascript patterns. So much good stuff to read up on! And to think, as a kid, I didn't care much for books.
@David,
Since I manually created the query object, there was not actual database to query. That said, it is my personal preference to use ZERO instead of NULL for foreign key references that are not there. I know a *lot* of people will disagree with me on this one; but, it's just the way I like it.
@All,
This conversation is so exciting. I need to learn more about this stuff.
There's CF code that demonstrates all the processes needed for add / update / move / etc here:
http://nstree.riaforge.org/
Basically a MOVE operation requires a "make some room" process to open a gap in the left/right numbering to make a hole as wide as the left/right gap of the node you're moving, then adjust the left/right values of the node to fall within the gap, then close the gap left by updating the node's left/right values. And, yeah, this needs to be done as a transaction obviously.
The updates are very quick because all they are doing is adding/subtracting a value to/from the left/right values.
The table will be locked *for other writes* but this will not impact reads, which will be fine reading the "dirty" data. One gotcha I have found here is that one must NOT do something like do a query based on a node ID, get the left/right value, then within another transaction re-use those left/right values expecting them to still refer to the same node. Because obviously the node's left/right values will not necessarily be the same. One needs to always use the node ID as input data into queries, not the left/right values (unless one is in a transaction, I guess).
To be honest, you can have all the apprehensions you like, but I reckon if people like Celko (http://en.wikipedia.org/wiki/Joe_Celko) say "this is a better way of doing it", then... you know... he probably knows what he's on about.
--
Adam
Oh, and to go back on topic... converting nested set data to hierarchical mark-up is a doddle. I don't have the code in front of me but it's basically this query:
select left as lineNum, '<node [stuff in here]>' as myXmlNode
from tree
union
select right as lineNum'</node>' as myXmlNode
from tree
order by lineNum
The one just needs to loop over the recordset, outputting myXmlNode.
That's it.
--
Adam
@Adam,
You couldn't ask for a query more simple than that :) These seems like an exciting approach.
Ben: I use 0 in CF since it doesn't have the concept of null and null in the DB side, the DB I use won't take a 0 if the referential integrity is turned on with the foreign key.
@David,
Yeah, I'm not so great about referential integrity at the database level. Not that my data is corrupt; I just never really learned how to enforce that at that RDMS level. Probably something I should learn eventually.
Adam: I realized that you can output the xml like:
<cfset RightsList="">
<cfset XMLData="">
<cfloop query="DataQuery">
<cfloop condition="ListLen(RightsList) AND DataQuery.Left GT ListFirst(RightsList)">
<cfset XMLData=XMLData&"</node>">
<cfset RightsList=ListRest(RightsList)>
</cfloop>
<cfset XMLData=XMLData&"<node...>">
<cfif DataQuery.Left+1 IS DataQuery.Right>
<cfset XMLData=XMLData&"</node>">
<cfelse>
<cfset RightsList=ListPrepend(RightsList,ataQuery.Right)>
</cfif>
</cfloop>
<cfloop condition="ListLen(RightsList) AND DataQuery.Left GT ListFirst(RightsList)">
<cfset XMLData=XMLData&"</node>">
<cfset RightsList=ListRest(RightsList)>
</cfloop>
Adam: In MSSQL you could use something like:
DECLARE @XML varchar(max);
SELECT XML=ISNULL(@XML,'')+xml
FROM (
____SELECT TOP 100 PERCENT Lft AS lineNum, '<node...>' AS xml
____FROM Tree
____UNION
____SELECT Rht AS lineNum, '</node>' AS xml
____FROM Tree
__) AS XMLElements
ORDER BY lineNum
SELECT @XML AS XML
That would return 1 record with xml all together
Just in case anyone was curious, here's the SQL CTE method of recursion. From here, it's just a straight loop over the query to generate xml.
CREATE TABLE #tree (id INT, parentID INT, name VARCHAR(50))
-- Create test data
INSERT #tree (id, parentID, name)
VALUES (1, NULL, 'First Parent')
INSERT #tree (id, parentID, name)
VALUES (2, NULL, 'Second Parent')
INSERT #tree (id, parentID, name)
VALUES (3, 1, 'Child 1.1')
INSERT #tree (id, parentID, name)
VALUES (4, 1, 'Child 1.2')
INSERT #tree (id, parentID, name)
VALUES (5, 2, 'Child 2.1')
INSERT #tree (id, parentID, name)
VALUES (6, 3, 'Child 1.1.1')
-- Recursive CTE to retrieve the nodes in order
;WITH expanded_tree (id, parentID, NAME, sort)
AS (
SELECT id,
parentID,
NAME,
CAST(ROW_NUMBER() OVER(ORDER BY name) AS VARBINARY(MAX)) AS sort
FROM #tree
WHERE parentID IS NULL
UNION ALL
SELECT t.id,
t.parentID,
t.name,
et.sort + CAST(ROW_NUMBER() OVER(ORDER BY t.name) AS VARBINARY(3)) AS sort
FROM expanded_tree et INNER JOIN #tree t
ON t.parentID = et.id
)
SELECT *
FROM expanded_tree
ORDER BY sort
DROP TABLE #tree
@Adam,
Thanks a lot for the insight :) Im terrible at expressing myself in words, so I wasn't sure if I offended you earlier (sorry if I did, it was never my intention).
Awesome, now to go remodel my db :)
@Roland,
Some databases are wicked powerful. One of things I really miss about SQL Server is the ability to just create in-memory tables. MySQL can't do that.
@Richard,
Don't worry about it my man - we're all just here for the good conversation :D
Ben: table variables are very handy in stored procedures, I have a function that splits a list into ints so I can pass stored procedures a list and then use a table variable in the IN() clause
Richard, I will never take offence at anything anyone has to say on a blog post or any other faceless written contribution to some internet-based organ. Or indeed, in general face to face. "Taking offence" is something one has to choose to do (it simply *does not* happen automatically), and as "taking offence" has no benefit - and indeed achieves almost nothing other than a bit of mental finger waving and tutting, I don't see the point in doing it.
A person could call me the greatest sort of idiot, and suggest I have an inappropriate relationship with my own mother and I'd just laugh. At them. For being stupid. But I would not take offence. Taking offence at stuff is a mug's game.
Ben: busy weekend, so didn't get around to knocking together any guidance as to how to easily get one's brains around nested set trees. Although I've just been tasked with implementing one (which I should be doing rather than writing this...), so the docs for that might lend themselves to something I can flick your way.
--
Adam
Adam: I have always found that getting upset by someone is pretty silly, either no offense was meant which make you a jerk or they meant to upset you which makes them a jerk, and why give them the satisfaction and the ability to upset you and make you unhappy if they are a jerk, the opinion of jerks is unimportant.
@David,
I don't know much about stored procedures, but I can say that not having table variables in MySQL was my first "Oh no!" moment in the new DB engine.
@Adam,
No worries at all. I can always relate to being busy. I still haven't even read the MySQL docs on it. Perhaps I'll have a look this weekend.