
Using jQuery With Custom XHTML Attributes And Namespaces To Store Data
I was talking to Brian Swartzfager yesterday about his new jQuery plugin for editable tables when I started to think about various ways to store meta-data in an XHTML document. I only recently learned about the jQuery data() method, which totally blew my mind! The data() method allows you to store arbitrary data with an XHTML DOM element. But then, I got to thinking about custom attributes. In XHTML, you can use namespaces to add custom attributes to your XHTML DOM elements.
I thought maybe custom attributes would be another way to store custom data. I know that namespaces do cause some problems in jQuery when you are searching for DOM elements; but, as far as setting and getting them, I figured that would be worth an experiment. In the following demo, I am creating IMDB link elements based on existing custom attributes:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html
xmlns="http://www.w3.org/1999/xhtml"
xmlns:bn="http://www.bennadel.com">
<head>
<title>Using jQuery With Custom XHTML Attributes</title>
<script type="text/javascript" src="jquery-1.2.6.min.js"></script>
<script type="text/javascript">
$(
function(){
var jLI = $( "li" );
// Loop over each list istem to set up link.
jLI.each(
function( intI ){
var jThis = $( this );
var jLink = $( "<a></a>" );
// Set the link text (trim text first).
jLink.text(
jThis.text().replace(
new RegExp( "^\\s+|\\s+$", "g" ),
""
)
);
// Set the link href based on the IMDB
// attribute of the list item.
jLink.attr(
{
"href": jThis.attr( "bn:imdb" ),
"bn:rel": "Pretty Cool Ladies"
}
);
// Replace the LI content with the link.
jThis
.empty()
.append( jLink )
;
}
);
}
);
</script>
</head>
<body>
<h1>
Pretty Cool Ladies
</h1>
<ul>
<li bn:imdb="http://www.imdb.com/name/nm0004742/">
Maria Bellow
</li>
<li bn:imdb="http://www.imdb.com/name/nm0184965/">
Christina Cox
</li>
<li bn:imdb="http://www.imdb.com/name/nm0226459/">
Ani DiFranco
</li>
</ul>
</body>
</html>
As you can see, the HREF attribute of the new link is based on the bn:imdb custom attribute of each list item. I am then setting a custom REL attribute (bn:rel) based on the type of node we are looking at. When we run the above code, we can see in FireBug that the XHTML was properly updated:
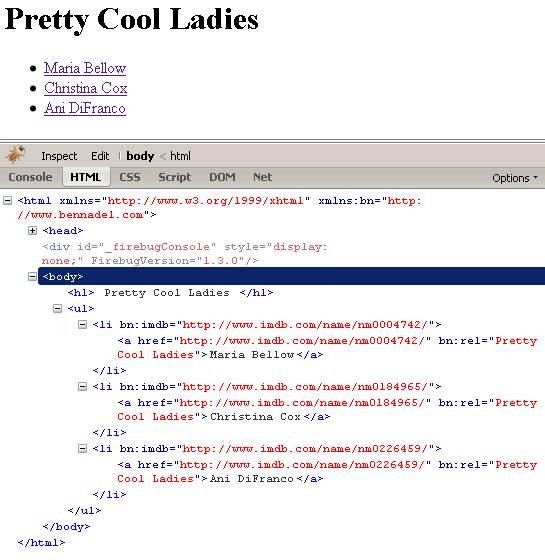
I tested this in FireFox, IE7, and Safari and all work fine. I doubt I would ever go this way instead of just using the data() method; but, it's interesting as an alternate approach for simple values. What's nice about it too is that the custom attributes can be built directly into the XHTML by ColdFusion before jQuery even has a chance to execute. This does give it an advantage over the data() method in specific use cases.
Want to use code from this post? Check out the license.

Reader Comments
I've found what works best for me is to store any custom variables in the name attribute in JSON format. I don't know if this is a good way to do it, but it's pretty darn customizable, scalable, and consistent.
for example, I use the dialog UI fairly liberally in most apps I make. So i'll bind the dialog to anchors with the class "dialog", and in the name attribute write something like: name="{title='My Dialog', width:500, height:300}", etc. then use jquery to parse the JSON and create the dialog dynamically.
just another way to store metadata inside an xhtml element while keeping it W3C valid.
@Eric,
The JSON strategy is nice. This could be used quite elegantly in conjunction with the custom namespace attributes:
<div app:data="{ref:3,sku:123456}">..</div>
The downsite to storing anything in attributes is that it is only easy when dealing with simple data. If we wanted to start storing node references of what not, then I think the data() method becomes the most viable answer.
Encoding metadata in an XHTML attribute is definitely a powerful technique. But like anything in development, you should always weighing the benefits against the potential drawbacks: in this case, defining behavior in your markup.
Separating a page's content, style, and behavior leads to more maintainable and reusable code. It usually results in a smaller code footprint (one CSS rule can affect a zillion elements) which decreases page load times.
It's a common pattern to use markup to flag elements (eg: form inputs) as having properties (eg: they are required fields) triggering behavior in the page's JavaScript. You can take this to all sorts of crazy places. Given a sufficiently expressive API, you can basically start doing metaprogramming right in your markup.
I'm not saying any of this is good or bad per se. (I think metaprogramming is just about the awesomest thing ever.) But it could be argued that putting application logic in your markup might reduce the maintainability of your code. Something to think about. . .
@Dave,
Another issue with putting business logic inline is that someone even mildly savvy in their browser could start changing your attribute values. Hopefully the processing code has validation in place, but if there are any loopholes, this could open you up to easier malicious behaviors.
Of course, with things like GreaseMonkey, there's really nothing client-side that can or even should be considered "Secure". So, really, I guess it's not a security issue.
Yeah, that's an issue with my JSON approach. I'm not very familiar with security issues around JavaScript or best practices, but to convert JSON to an object I use eval(), and I've always been taught evaluating in any language is a huge no-no and presents a security risk.
@Eric,
Don't worry about security from a script-execution standpoint; anyone can execute any script on their own page. This cannot be turned into an XSS (cross-site-scripting) attack. The only security issue I would be concerned about would be to have someone change ID values that are then submitted back to the server and processed without validation.
For example, imagine someone changing this:
<div product:price="34.95">Cool Product</div>
... to be:
<div product:price="5.00">Cool Product</div>
... and really only being charged 5.00 on checkout.
A silly example, but you'd be shocked how little security some apps have :D
I know this is just an example and all, but why would you have the value of the hrefs on the LI instead of actually creating the a hrefs?
If you turn off javascript (or surf around with FireFox + Ad Block + No Script), then your text (which are expecting to be links) are just that... plain text? Plus, search engines have no links to follow, so I guess if you were attempting to be SEO unfriendly, this is one way to do it.
@Todd,
I just needed something to play with :) That's not an actual valid use case.
Well, I still wish you would take a peek at the jquery metadata plugin ( http://plugins.jquery.com/project/metadata ). I have an internal project (timetracker) that I'm working on and I like it. You mentioned that you didn't like having JSON data all over the place. I still insist that if you use it wisely, it can be done right.
I have an example as well ( http://pastebin.com/m60f62544 ) - So, the part that is highlighted with yellow is my metadata JSON for the div span. Because the JSON is on the span, I'm not repeating myself on all the A HREFs within the SPAN.
Then, on each href, I have a class that dictates what javascript function I want to kick off, how do I get the data? I get it from the a href's parent... the span. $(this).parent('.actions') is looking for the parent above it with the class of .actions.
Neat & Tidy IMHO and more importantly, I'm not repeating myself and I'm making use of data containers.
@Todd,
Don't get me wrong - I love JSON in general. I am not against using it in the way you have, and as you are saying, when used correctly, it can be awesome.
The meta-data plugin seems to go along quite nicely with this.
Just a short note - you might be interested in jQuery.trim() ... built-in function to trim a string
@Hansjoerg,
Thanks - I keep forgetting about that one!
I found this article when trying to find how to select elements with namespaced attributes, so in case anyone else does too, I'll note what I've found.
It seems that if you want to select all items with the "bn:rel" attribute, you CANNOT do this...
jQuery('[bn:rel]')
...because jQuery doesn't accept the colon in the selector.
There's a workaround using filter, like so:
$('*').filter(function(){return $(this).attr('bn:rel')!==undefined})
Eugh! Horribly ugly, but it's only way I've found that'll work.
Since I'm doing a fair bit of work with namespaced attributes at the moment, I think I'll have to turn it into a plugin so I don't have to look at it. :S
@Peter,
I've never actually tried this, but I believe you can escape special characters in jQuery selectors. Try using something like:
jQuery('[bn\\:rel]')
... I *think* it might actually support that.
Yeah I tried that and still got an error - in Firefox anyway. (I saw something suggesting it was a browser-specific thing.)
@Peter,
Hmmm, that's not good. I wish I had a better suggestion. At the very least, if you include a tag selector or something, it would probably speed up your query (* is gonna be the slowest).
Yeah, that'd definitely make sense in general.
For my specific case the attributes can actually be on almost any tag, so it's simpler to just use * than try to list them all - only needs to be fast running on my machine, since it's a backend UI - so far it's good enough.
@Peter,
I figured as much... I was just trying to come up with *something* valuable to tell you :)